Edge computing processes data near the source, reducing latency and bandwidth usage by handling computations locally on devices or nearby servers. Fog computing extends this concept by creating a decentralized network of edge devices, gateways, and cloud resources to improve scalability and support more complex workloads. Discover how these technologies transform manufacturing efficiency and innovation.
Why it is important
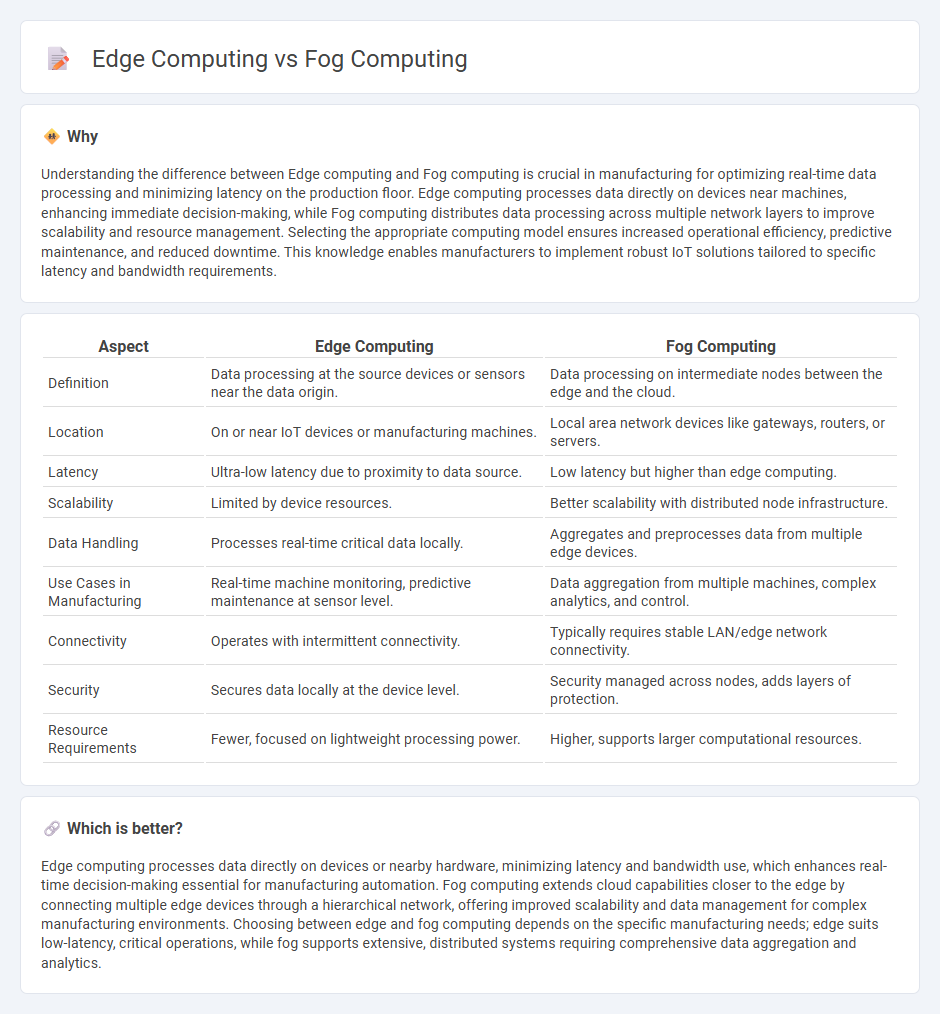
Understanding the difference between Edge computing and Fog computing is crucial in manufacturing for optimizing real-time data processing and minimizing latency on the production floor. Edge computing processes data directly on devices near machines, enhancing immediate decision-making, while Fog computing distributes data processing across multiple network layers to improve scalability and resource management. Selecting the appropriate computing model ensures increased operational efficiency, predictive maintenance, and reduced downtime. This knowledge enables manufacturers to implement robust IoT solutions tailored to specific latency and bandwidth requirements.
Comparison Table
| Aspect | Edge Computing | Fog Computing |
|---|---|---|
| Definition | Data processing at the source devices or sensors near the data origin. | Data processing on intermediate nodes between the edge and the cloud. |
| Location | On or near IoT devices or manufacturing machines. | Local area network devices like gateways, routers, or servers. |
| Latency | Ultra-low latency due to proximity to data source. | Low latency but higher than edge computing. |
| Scalability | Limited by device resources. | Better scalability with distributed node infrastructure. |
| Data Handling | Processes real-time critical data locally. | Aggregates and preprocesses data from multiple edge devices. |
| Use Cases in Manufacturing | Real-time machine monitoring, predictive maintenance at sensor level. | Data aggregation from multiple machines, complex analytics, and control. |
| Connectivity | Operates with intermittent connectivity. | Typically requires stable LAN/edge network connectivity. |
| Security | Secures data locally at the device level. | Security managed across nodes, adds layers of protection. |
| Resource Requirements | Fewer, focused on lightweight processing power. | Higher, supports larger computational resources. |
Which is better?
Edge computing processes data directly on devices or nearby hardware, minimizing latency and bandwidth use, which enhances real-time decision-making essential for manufacturing automation. Fog computing extends cloud capabilities closer to the edge by connecting multiple edge devices through a hierarchical network, offering improved scalability and data management for complex manufacturing environments. Choosing between edge and fog computing depends on the specific manufacturing needs; edge suits low-latency, critical operations, while fog supports extensive, distributed systems requiring comprehensive data aggregation and analytics.
Connection
Edge computing processes data near the source of generation, reducing latency and bandwidth usage in manufacturing environments. Fog computing extends this capability by providing a hierarchical layer of intermediate nodes between edge devices and centralized cloud servers, enhancing data management and real-time analytics. Together, they enable efficient, scalable, and responsive manufacturing operations by optimizing data flow from sensors, machines, and control systems.
Key Terms
Latency
Fog computing distributes processing tasks across multiple nodes between the cloud and edge devices, reducing latency by localizing data processing closer to the source. Edge computing pushes computation and data storage directly onto devices or sensors at the network's edge, achieving ultra-low latency critical for real-time applications such as autonomous vehicles and industrial automation. Explore deeper insights into latency impacts and use cases in fog versus edge computing to optimize your network architecture.
Data Processing Location
Fog computing extends cloud capabilities by distributing data processing across multiple local nodes situated between the cloud and edge devices, optimizing latency and bandwidth. Edge computing processes data directly on or near the source devices, such as sensors or gateways, reducing the distance data travels and enabling real-time analytics. Explore deeper insights into how these architectures impact performance and scalability in modern IoT environments.
Real-time Analytics
Fog computing extends cloud capabilities closer to data sources by deploying computing resources across multiple edge devices, enhancing real-time analytics with reduced latency and improved bandwidth efficiency. Edge computing processes data directly on local devices or edge servers, enabling faster decision-making and immediate insights critical for time-sensitive applications like autonomous vehicles and industrial automation. Explore the distinct benefits and use cases of fog and edge computing to optimize your real-time analytics strategy.
Source and External Links
Fog Computing: Definition, Explanation, and Use Cases - Fog computing is a decentralized computing infrastructure where data is processed locally or near the data source to reduce latency, bandwidth use, and enhance security by operating independently from external networks.
Fog computing - Wikipedia - Fog computing extends cloud computing by distributing computation and storage closer to IoT devices to handle large data volumes with low latency, improving quality of service and reducing backbone bandwidth requirements.
What Is Fog Computing? Importance, Applications, Everything to Know - Fog computing brings computation and data storage closer to network edge devices, enhancing real-time processing, performance, decision-making, and reducing costs by minimizing data transmission to the cloud.