Vector databases excel in handling complex, high-dimensional data such as images, videos, and natural language embeddings, enabling advanced search and similarity queries. Wide-column stores efficiently manage large-scale, sparse datasets with flexible schema designs, making them ideal for real-time analytics and time-series data. Explore how these database types optimize storage and retrieval across diverse technological applications.
Why it is important
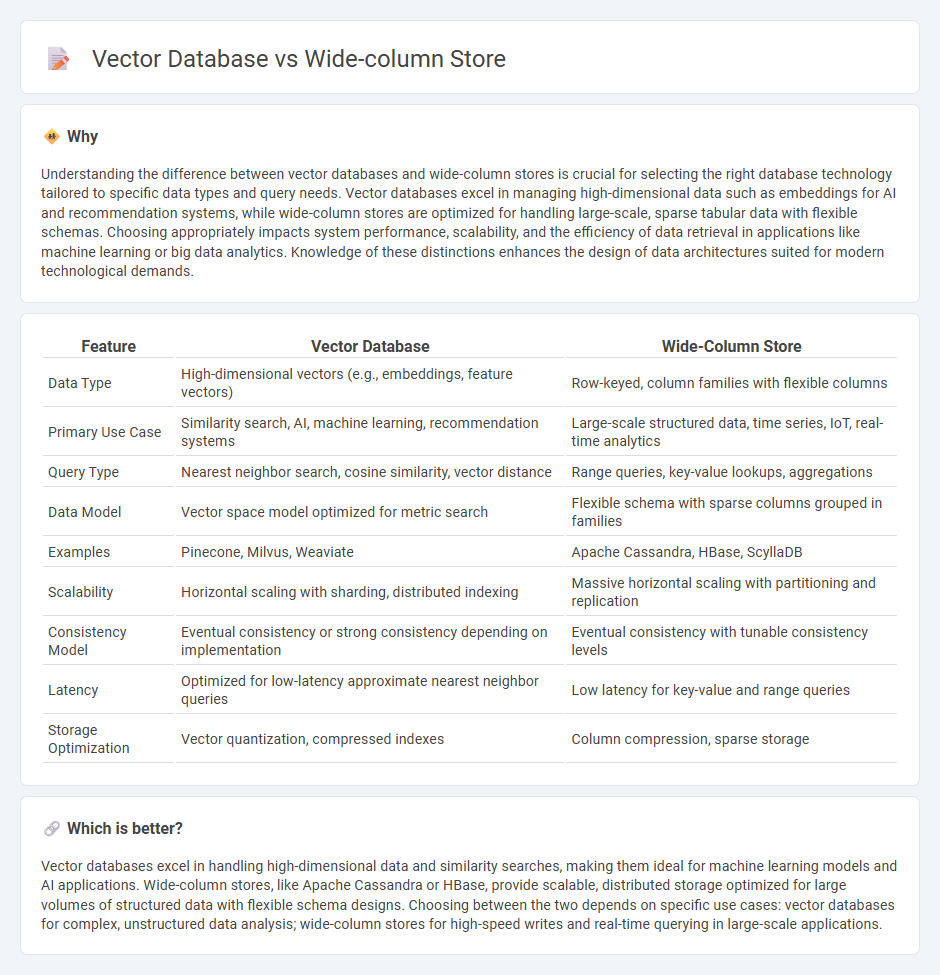
Understanding the difference between vector databases and wide-column stores is crucial for selecting the right database technology tailored to specific data types and query needs. Vector databases excel in managing high-dimensional data such as embeddings for AI and recommendation systems, while wide-column stores are optimized for handling large-scale, sparse tabular data with flexible schemas. Choosing appropriately impacts system performance, scalability, and the efficiency of data retrieval in applications like machine learning or big data analytics. Knowledge of these distinctions enhances the design of data architectures suited for modern technological demands.
Comparison Table
| Feature | Vector Database | Wide-Column Store |
|---|---|---|
| Data Type | High-dimensional vectors (e.g., embeddings, feature vectors) | Row-keyed, column families with flexible columns |
| Primary Use Case | Similarity search, AI, machine learning, recommendation systems | Large-scale structured data, time series, IoT, real-time analytics |
| Query Type | Nearest neighbor search, cosine similarity, vector distance | Range queries, key-value lookups, aggregations |
| Data Model | Vector space model optimized for metric search | Flexible schema with sparse columns grouped in families |
| Examples | Pinecone, Milvus, Weaviate | Apache Cassandra, HBase, ScyllaDB |
| Scalability | Horizontal scaling with sharding, distributed indexing | Massive horizontal scaling with partitioning and replication |
| Consistency Model | Eventual consistency or strong consistency depending on implementation | Eventual consistency with tunable consistency levels |
| Latency | Optimized for low-latency approximate nearest neighbor queries | Low latency for key-value and range queries |
| Storage Optimization | Vector quantization, compressed indexes | Column compression, sparse storage |
Which is better?
Vector databases excel in handling high-dimensional data and similarity searches, making them ideal for machine learning models and AI applications. Wide-column stores, like Apache Cassandra or HBase, provide scalable, distributed storage optimized for large volumes of structured data with flexible schema designs. Choosing between the two depends on specific use cases: vector databases for complex, unstructured data analysis; wide-column stores for high-speed writes and real-time querying in large-scale applications.
Connection
Vector databases and wide-column stores both manage large-scale, high-dimensional data but serve different purposes within technology ecosystems. Vector databases optimize storage and similarity search for complex vector embeddings used in AI and machine learning applications, while wide-column stores efficiently handle sparse, distributed data across many columns in big data scenarios. Their connection lies in integrating vector search capabilities within wide-column architectures to enhance real-time analytics and scalable AI data processing.
Key Terms
Data Model
Wide-column stores organize data into flexible, sparse tables with rows and dynamic columns ideal for large-scale, distributed systems requiring high write throughput and efficient querying of structured data. Vector databases specialize in storing and querying high-dimensional vectors, enabling similarity search and machine learning applications by efficiently indexing embeddings generated from unstructured data like text, images, or audio. Explore our detailed comparison to understand which data model best suits your application needs.
Query Pattern
Wide-column stores excel in handling large volumes of structured data using efficient row and column-based queries optimized for sequential scans and aggregations, ideal for time-series and sensor data analysis. Vector databases specialize in similarity search by indexing high-dimensional vectors, enabling fast approximate nearest neighbor queries crucial for applications like image retrieval, natural language processing, and recommendation systems. Explore detailed comparisons to understand which database aligns best with your specific query patterns and data needs.
Indexing Method
Wide-column stores utilize multi-dimensional indexing techniques such as partition keys combined with clustering columns to efficiently organize and retrieve large-scale structured data. Vector databases implement specialized indexing methods like Approximate Nearest Neighbor (ANN) algorithms, including HNSW and Faiss, to quickly search high-dimensional vector embeddings common in machine learning applications. Explore the nuances of indexing in both systems to optimize your data retrieval strategy.
Source and External Links
Wide-column store - A wide-column store is a type of NoSQL database that organizes data in tables, rows, and columns, where columns can vary between rows in the same table, offering flexibility and scalability for large, sparse datasets.
Wide Column Stores - Wide column stores, also known as extensible record stores, allow records to contain a very large number of dynamic columns, with both column names and keys not fixed, functioning similarly to two-dimensional key-value stores.
What is a Wide-Column Database? - Wide-column databases are highly scalable NoSQL systems that distribute data across columns and nodes, making them suitable for massive, variable, and distributed datasets such as logs, IoT, and time-series data.