Vector databases excel in handling high-dimensional data, making them ideal for machine learning, image recognition, and natural language processing tasks. Graph databases specialize in managing complex relationships between data points, enabling efficient queries of interconnected information in social networks, recommendation systems, and fraud detection. Explore the key differences and use cases of vector and graph databases to optimize your data management strategy.
Why it is important
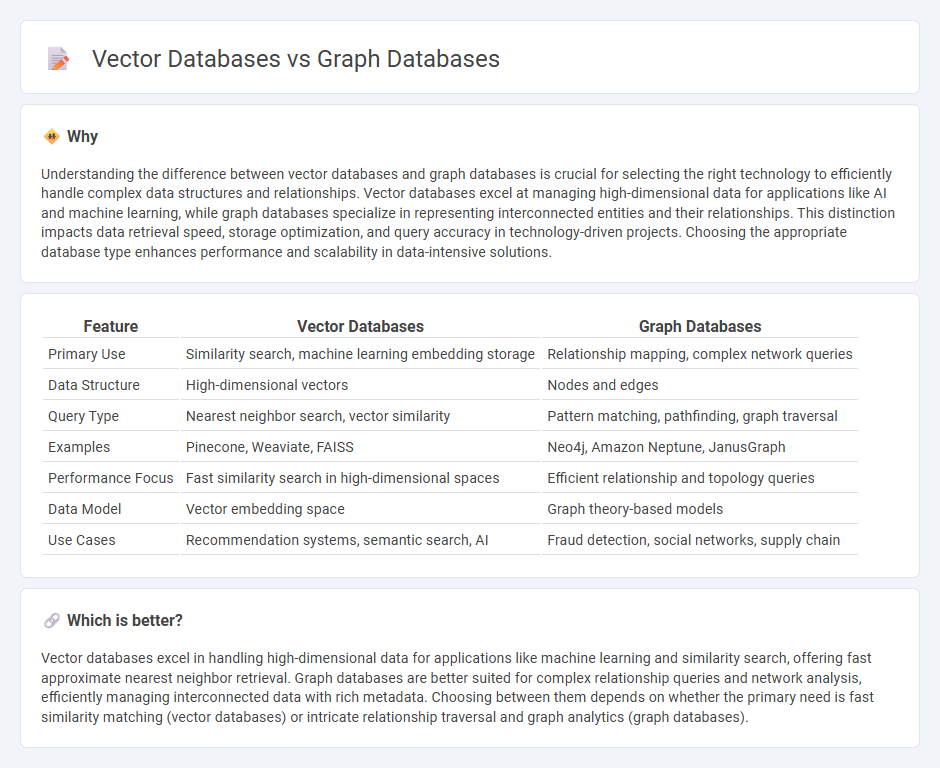
Understanding the difference between vector databases and graph databases is crucial for selecting the right technology to efficiently handle complex data structures and relationships. Vector databases excel at managing high-dimensional data for applications like AI and machine learning, while graph databases specialize in representing interconnected entities and their relationships. This distinction impacts data retrieval speed, storage optimization, and query accuracy in technology-driven projects. Choosing the appropriate database type enhances performance and scalability in data-intensive solutions.
Comparison Table
| Feature | Vector Databases | Graph Databases |
|---|---|---|
| Primary Use | Similarity search, machine learning embedding storage | Relationship mapping, complex network queries |
| Data Structure | High-dimensional vectors | Nodes and edges |
| Query Type | Nearest neighbor search, vector similarity | Pattern matching, pathfinding, graph traversal |
| Examples | Pinecone, Weaviate, FAISS | Neo4j, Amazon Neptune, JanusGraph |
| Performance Focus | Fast similarity search in high-dimensional spaces | Efficient relationship and topology queries |
| Data Model | Vector embedding space | Graph theory-based models |
| Use Cases | Recommendation systems, semantic search, AI | Fraud detection, social networks, supply chain |
Which is better?
Vector databases excel in handling high-dimensional data for applications like machine learning and similarity search, offering fast approximate nearest neighbor retrieval. Graph databases are better suited for complex relationship queries and network analysis, efficiently managing interconnected data with rich metadata. Choosing between them depends on whether the primary need is fast similarity matching (vector databases) or intricate relationship traversal and graph analytics (graph databases).
Connection
Vector databases and graph databases are connected through their ability to manage and analyze complex relationships within large datasets, with vector databases focusing on high-dimensional numerical data for similarity searches and graph databases specializing in interconnected entity relationships. Both technologies enhance machine learning and AI applications by enabling efficient retrieval of semantically relevant information and uncovering patterns within unstructured and structured data. Integrating vector embeddings into graph database frameworks allows for more nuanced insights, boosting the performance of recommendation systems, knowledge graphs, and natural language processing tasks.
Key Terms
Data Structure
Graph databases organize data as nodes, edges, and properties, enabling complex relationships and network queries ideal for social networks and fraud detection. Vector databases store high-dimensional vectors representing data points, optimized for similarity searches and machine learning applications, such as image and text retrieval. Explore detailed comparisons to understand which data structure suits your specific analytical needs.
Query Mechanism
Graph databases utilize complex traversals and pattern matching algorithms to execute queries based on relationships and connections between nodes and edges, enabling efficient retrieval of interconnected data. Vector databases, however, rely on approximate nearest neighbor (ANN) search algorithms to handle high-dimensional vector embeddings, optimized for similarity searches and machine learning applications. Explore further to understand how these distinct query mechanisms impact performance and use cases.
Use Cases
Graph databases excel in use cases involving complex relationships such as social networks, fraud detection, and recommendation engines by efficiently handling interconnected data and traversals. Vector databases are optimized for similarity searches in high-dimensional spaces, powering applications like image recognition, natural language processing, and personalized content recommendations. Explore detailed comparisons to understand which database type suits your specific use case and data needs.
Source and External Links
Graph database - Wikipedia - Graph databases use graph structures with nodes, edges, and properties to represent and store data, prioritizing relationships between data items for fast and intuitive querying of interconnected information.
What Is a Graph Database? - Oracle - Graph databases are specialized platforms for managing graphs (nodes, edges, properties) that excel at modeling and analyzing complex relationships, differing from relational databases by treating relationships as core elements.
What is a graph database - Getting Started - Neo4j - Neo4j and similar graph databases store data as nodes (entities), relationships (connections), and properties (attributes), enabling flexible and efficient modeling of highly connected data without a predefined schema.