Federated learning enables decentralized model training by allowing multiple devices to collaboratively learn from local data without sharing raw information, enhancing privacy and reducing communication costs. Split learning divides a neural network between client and server, where only intermediate activations are exchanged, optimizing resource usage and maintaining data confidentiality. Discover more about how these innovative technologies transform privacy-preserving machine learning.
Why it is important
Understanding the difference between federated learning and split learning is crucial for optimizing data privacy and computational efficiency in distributed AI systems. Federated learning enables multiple devices to collaboratively train a shared model without exchanging raw data, enhancing privacy by only sharing model updates. Split learning divides the neural network between client and server, reducing client-side resource requirements while keeping raw data local. This knowledge guides the selection of the most suitable architecture for secure, scalable machine learning applications in healthcare, finance, and edge computing.
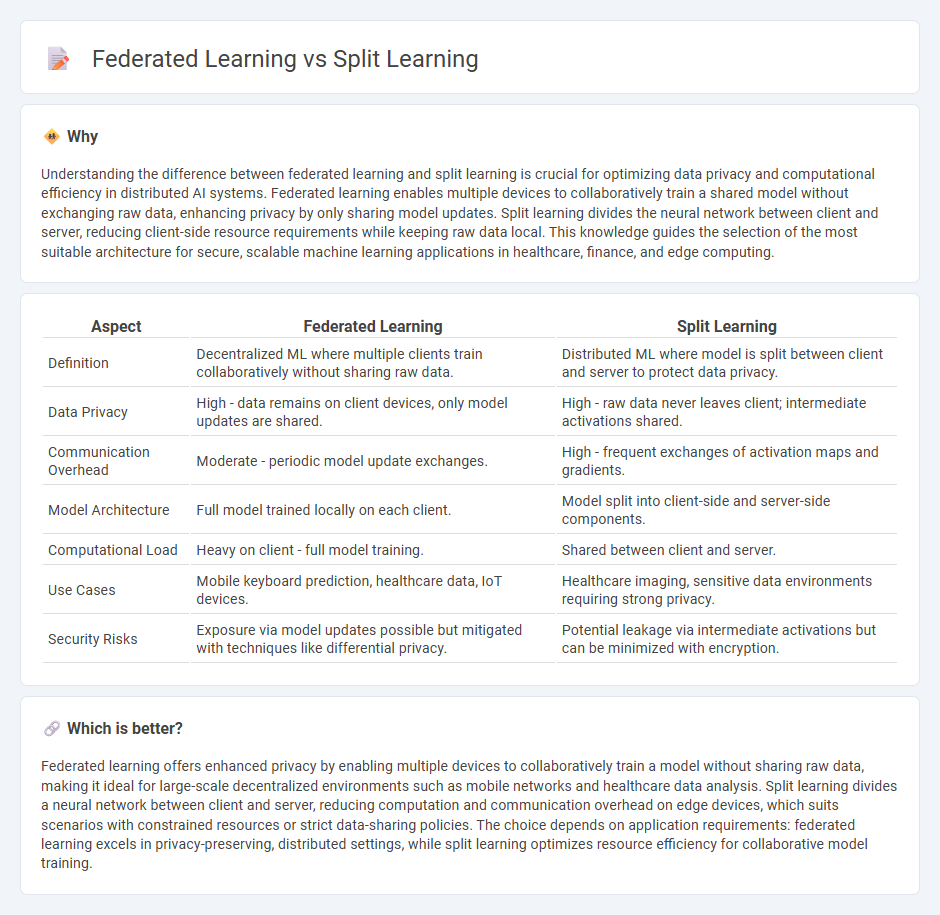
Comparison Table
| Aspect | Federated Learning | Split Learning |
|---|---|---|
| Definition | Decentralized ML where multiple clients train collaboratively without sharing raw data. | Distributed ML where model is split between client and server to protect data privacy. |
| Data Privacy | High - data remains on client devices, only model updates are shared. | High - raw data never leaves client; intermediate activations shared. |
| Communication Overhead | Moderate - periodic model update exchanges. | High - frequent exchanges of activation maps and gradients. |
| Model Architecture | Full model trained locally on each client. | Model split into client-side and server-side components. |
| Computational Load | Heavy on client - full model training. | Shared between client and server. |
| Use Cases | Mobile keyboard prediction, healthcare data, IoT devices. | Healthcare imaging, sensitive data environments requiring strong privacy. |
| Security Risks | Exposure via model updates possible but mitigated with techniques like differential privacy. | Potential leakage via intermediate activations but can be minimized with encryption. |
Which is better?
Federated learning offers enhanced privacy by enabling multiple devices to collaboratively train a model without sharing raw data, making it ideal for large-scale decentralized environments such as mobile networks and healthcare data analysis. Split learning divides a neural network between client and server, reducing computation and communication overhead on edge devices, which suits scenarios with constrained resources or strict data-sharing policies. The choice depends on application requirements: federated learning excels in privacy-preserving, distributed settings, while split learning optimizes resource efficiency for collaborative model training.
Connection
Federated learning and split learning are connected through their shared goal of enhancing data privacy in distributed machine learning by enabling model training across multiple devices without centralizing raw data. Both techniques partition a learning task: federated learning by sharing model updates from local devices to a central server, and split learning by dividing the neural network layers between clients and servers. This collaboration reduces data exposure risks and supports compliance with privacy regulations like GDPR in applications across healthcare, finance, and IoT networks.
Key Terms
Data Partitioning
Split learning divides a neural network model into segments, with each participant training a specific portion on its local data before sharing intermediate activations for collaborative learning, ideal for vertically partitioned data where features are distributed across entities. Federated learning involves multiple clients independently training models on their local horizontally partitioned datasets (sharing the same feature space but different samples), with only model updates transmitted to a central server for aggregation, preserving data privacy. Explore deeper into how these data partitioning strategies impact model performance and privacy preservation.
Model Aggregation
Model aggregation in federated learning involves combining locally trained model updates from multiple clients to create a global model, typically using algorithms like Federated Averaging (FedAvg) that preserve data privacy by transmitting only model parameters. In split learning, aggregation occurs by sequentially processing model segments: clients compute forward passes on initial layers, sending intermediate activations to a server that completes the forward and backward passes, aggregating gradients for synchronized updates without sharing raw data. Explore the nuances of model aggregation techniques to optimize privacy-preserving distributed learning frameworks.
Privacy Preservation
Split learning enhances privacy preservation by partitioning a neural network between clients and servers, ensuring raw data never leaves the client's side while only intermediate activations are shared. Federated learning enables multiple devices to collaboratively train a global model using local data without data exchange, reducing privacy risks but potentially exposing update patterns. Explore deeper insights into how each method safeguards sensitive information in distributed AI systems.
Source and External Links
Split Learning for Distributed Collaborative Training - This paper explores split learning as a paradigm for collaborative deep learning across distributed health data, ensuring privacy by only sharing processed data.
A Study of Split Learning Model - This study examines various configurations of split learning, including vanilla and U-shaped models, to protect user privacy by not sharing raw data.
Split Learning Project: MIT Media Lab - Developed at MIT Media Lab, split learning is a technique for training AI models without sharing raw data, addressing challenges in data sharing and privacy.