Generative video technology creates new video content using artificial intelligence models, enabling innovative applications such as deepfakes and virtual reality environments. Video classification algorithms analyze and categorize existing video footage by identifying objects, scenes, or actions, enhancing content organization and retrieval. Explore the distinct advantages and applications of generative video and video classification to understand their impact on media and technology.
Why it is important
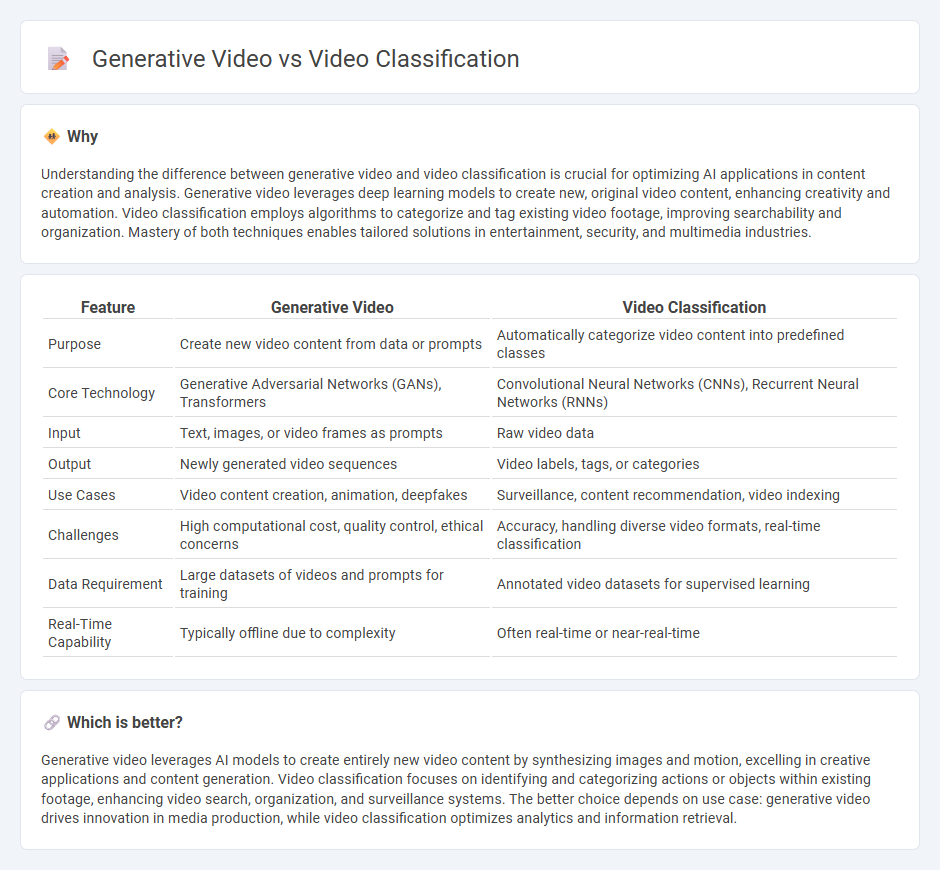
Understanding the difference between generative video and video classification is crucial for optimizing AI applications in content creation and analysis. Generative video leverages deep learning models to create new, original video content, enhancing creativity and automation. Video classification employs algorithms to categorize and tag existing video footage, improving searchability and organization. Mastery of both techniques enables tailored solutions in entertainment, security, and multimedia industries.
Comparison Table
| Feature | Generative Video | Video Classification |
|---|---|---|
| Purpose | Create new video content from data or prompts | Automatically categorize video content into predefined classes |
| Core Technology | Generative Adversarial Networks (GANs), Transformers | Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) |
| Input | Text, images, or video frames as prompts | Raw video data |
| Output | Newly generated video sequences | Video labels, tags, or categories |
| Use Cases | Video content creation, animation, deepfakes | Surveillance, content recommendation, video indexing |
| Challenges | High computational cost, quality control, ethical concerns | Accuracy, handling diverse video formats, real-time classification |
| Data Requirement | Large datasets of videos and prompts for training | Annotated video datasets for supervised learning |
| Real-Time Capability | Typically offline due to complexity | Often real-time or near-real-time |
Which is better?
Generative video leverages AI models to create entirely new video content by synthesizing images and motion, excelling in creative applications and content generation. Video classification focuses on identifying and categorizing actions or objects within existing footage, enhancing video search, organization, and surveillance systems. The better choice depends on use case: generative video drives innovation in media production, while video classification optimizes analytics and information retrieval.
Connection
Generative video leverages AI models to create new, realistic video content by synthesizing frames based on learned patterns, while video classification uses machine learning algorithms to categorize and analyze video data for specific features or actions. The connection lies in their shared reliance on deep neural networks and large datasets to improve accuracy and generate meaningful video outputs or classifications. Advances in generative video enhance video classification by providing synthetic training data, improving model robustness and performance in diverse video analysis tasks.
Key Terms
Feature Extraction
Video classification relies on advanced feature extraction techniques such as convolutional neural networks (CNNs) and 3D CNNs to capture spatial and temporal patterns effectively. Generative video models emphasize extracting features that enable realistic frame synthesis, often utilizing generative adversarial networks (GANs) or variational autoencoders (VAEs) to learn rich latent representations. Explore further to understand how feature extraction impacts the performance and applications of both video classification and generative video systems.
Temporal Modeling
Video classification leverages temporal modeling to analyze sequential frames, capturing motion dynamics and contextual dependencies essential for accurate categorization. Generative video models incorporate temporal coherence to synthesize realistic video sequences that evolve smoothly over time, using recurrent architectures or transformers to maintain frame-to-frame consistency. Explore advanced temporal modeling techniques to unlock deeper insights into both video classification accuracy and generative video quality.
Video Synthesis
Video classification involves categorizing video content into predefined labels based on visual and temporal features, critical for applications like surveillance and content recommendation. Generative video synthesis produces new, realistic video sequences by leveraging deep learning models such as GANs and VAEs, enabling innovations in entertainment, virtual reality, and data augmentation. Explore advanced techniques in video synthesis to enhance creative media production and AI-driven content creation.
Source and External Links
Video Classification: Methods, Use Cases, Tutorial - This guide provides an overview of video classification methods, including supervised and low supervision approaches, and discusses various applications.
Video Classification - This page lists relevant papers and benchmarks for video classification, including various datasets and state-of-the-art models.
Video classification - This resource explains how to perform video classification using models available on Hugging Face, enabling the categorization of entire videos.