Generative fill leverages neural networks to seamlessly complete missing image regions by predicting plausible content based on surrounding pixels. Latent diffusion models operate by encoding images into latent space, then iteratively refining noisy representations to generate high-quality visuals with controlled creativity. Explore further to understand how these cutting-edge techniques transform artificial intelligence-driven image synthesis.
Why it is important
Understanding the difference between generative fill and latent diffusion is crucial for optimizing AI-driven image synthesis and editing workflows, as generative fill directly targets missing image regions while latent diffusion models generate new content by iteratively refining latent representations. Mastery of these methods enhances precision in creative applications, from virtual design to medical imaging, by leveraging appropriate algorithms for specific tasks. Awareness of generative fill's pixel-level accuracy and latent diffusion's generative diversity empowers developers to improve model efficiency and output quality. This knowledge drives innovation in artificial intelligence and deep learning, shaping future advancements in generative technologies.
Comparison Table
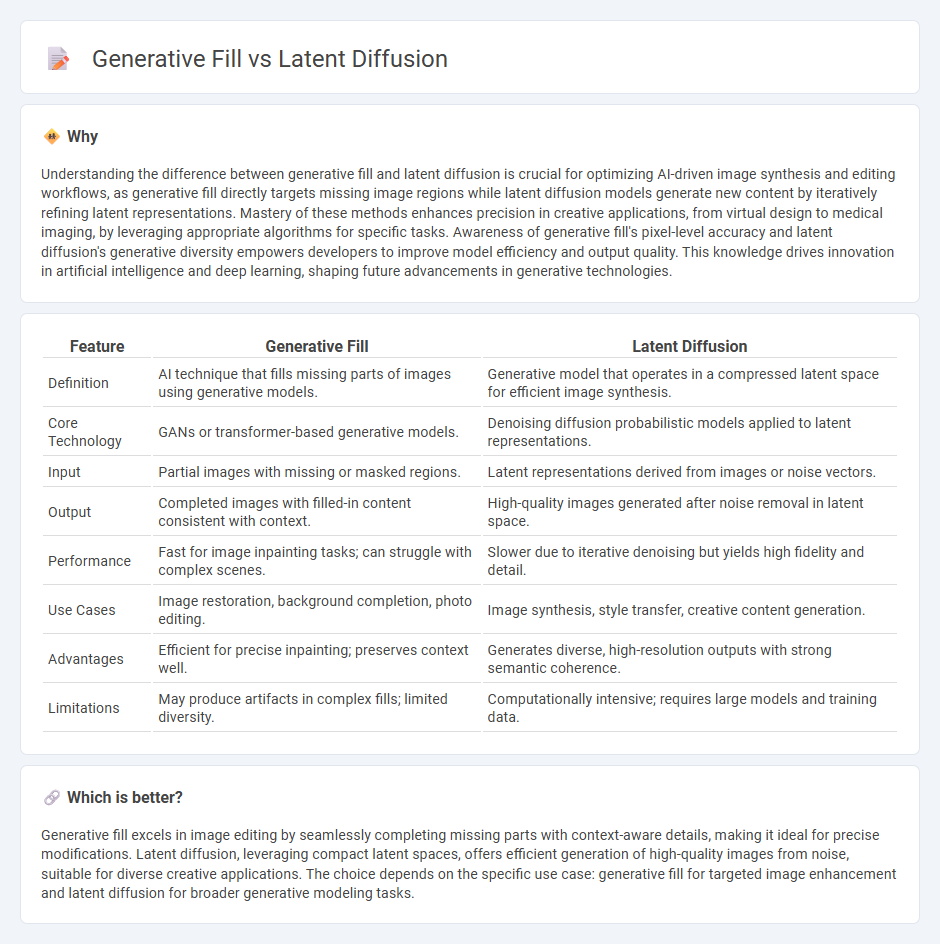
| Feature | Generative Fill | Latent Diffusion |
|---|---|---|
| Definition | AI technique that fills missing parts of images using generative models. | Generative model that operates in a compressed latent space for efficient image synthesis. |
| Core Technology | GANs or transformer-based generative models. | Denoising diffusion probabilistic models applied to latent representations. |
| Input | Partial images with missing or masked regions. | Latent representations derived from images or noise vectors. |
| Output | Completed images with filled-in content consistent with context. | High-quality images generated after noise removal in latent space. |
| Performance | Fast for image inpainting tasks; can struggle with complex scenes. | Slower due to iterative denoising but yields high fidelity and detail. |
| Use Cases | Image restoration, background completion, photo editing. | Image synthesis, style transfer, creative content generation. |
| Advantages | Efficient for precise inpainting; preserves context well. | Generates diverse, high-resolution outputs with strong semantic coherence. |
| Limitations | May produce artifacts in complex fills; limited diversity. | Computationally intensive; requires large models and training data. |
Which is better?
Generative fill excels in image editing by seamlessly completing missing parts with context-aware details, making it ideal for precise modifications. Latent diffusion, leveraging compact latent spaces, offers efficient generation of high-quality images from noise, suitable for diverse creative applications. The choice depends on the specific use case: generative fill for targeted image enhancement and latent diffusion for broader generative modeling tasks.
Connection
Generative fill leverages latent diffusion models to create realistic and coherent image completions by iteratively refining noise patterns in a latent space. Latent diffusion compresses high-dimensional data into a lower-dimensional space, enabling efficient generation and manipulation of complex visuals. The synergy between generative fill and latent diffusion enhances AI-driven image editing, improving accuracy and creative control.
Key Terms
Image Synthesis
Latent diffusion models (LDMs) excel in image synthesis by compressing images into a lower-dimensional latent space, enabling efficient generation with high fidelity and diversity. Generative fill techniques focus on context-aware inpainting, filling missing regions in images by learning spatially coherent patterns to produce seamless results. Explore detailed comparisons and applications of latent diffusion and generative fill in advanced image synthesis to enhance creative workflows.
Neural Networks
Latent diffusion models leverage neural networks to encode images into a compressed latent space, enabling efficient generation and manipulation by iteratively denoising latent variables. Generative fill techniques utilize convolutional neural networks (CNNs) or transformers to predict missing regions in images, focusing on context-aware synthesis for seamless completion. Explore the detailed differences and applications of these neural network-driven methods to unlock advanced image generation capabilities.
Inpainting
Latent diffusion excels in inpainting by utilizing a compressed latent space to generate detailed and coherent image regions, optimizing both quality and computational efficiency. Generative fill leverages contextual understanding to seamlessly reconstruct missing or corrupted parts of images, often harnessing transformer-based architectures for enhanced semantic consistency. Explore the nuances of these cutting-edge methods to enhance your image restoration projects.
Source and External Links
Text-to-image: latent diffusion models - This webpage discusses how latent diffusion models are used in text-to-image synthesis, leveraging components like autoencoders and diffusion processes for efficient image generation.
Latent Diffusion - The Hugging Face documentation covers latent diffusion models, highlighting their application in tasks such as image inpainting and text-to-image synthesis with reduced computational requirements.
Latent Diffusion Model - Wikipedia provides an overview of latent diffusion models, noting their improvement over standard diffusion models by operating in latent space and incorporating self- and cross-attention.