Multimodal AI integrates diverse data types such as text, images, and audio to enhance machine understanding and decision-making, leveraging advanced neural networks for comprehensive context analysis. Reinforcement learning trains agents through reward-based feedback loops, enabling adaptive behaviors in dynamic environments by optimizing action policies. Explore the distinctions and applications of these cutting-edge AI methodologies to unlock their full potential.
Why it is important
Understanding the difference between multimodal AI and reinforcement learning is crucial for optimizing technology deployment in fields like natural language processing and robotics. Multimodal AI integrates data from various sources such as text, images, and audio to enhance decision-making accuracy, whereas reinforcement learning focuses on agents learning optimal strategies through reward-based feedback loops. Knowledge of these distinctions enables developers to select the appropriate AI model, improving system efficiency and innovation. Clear differentiation advances tailored solutions in emerging applications like autonomous vehicles and intelligent assistants.
Comparison Table
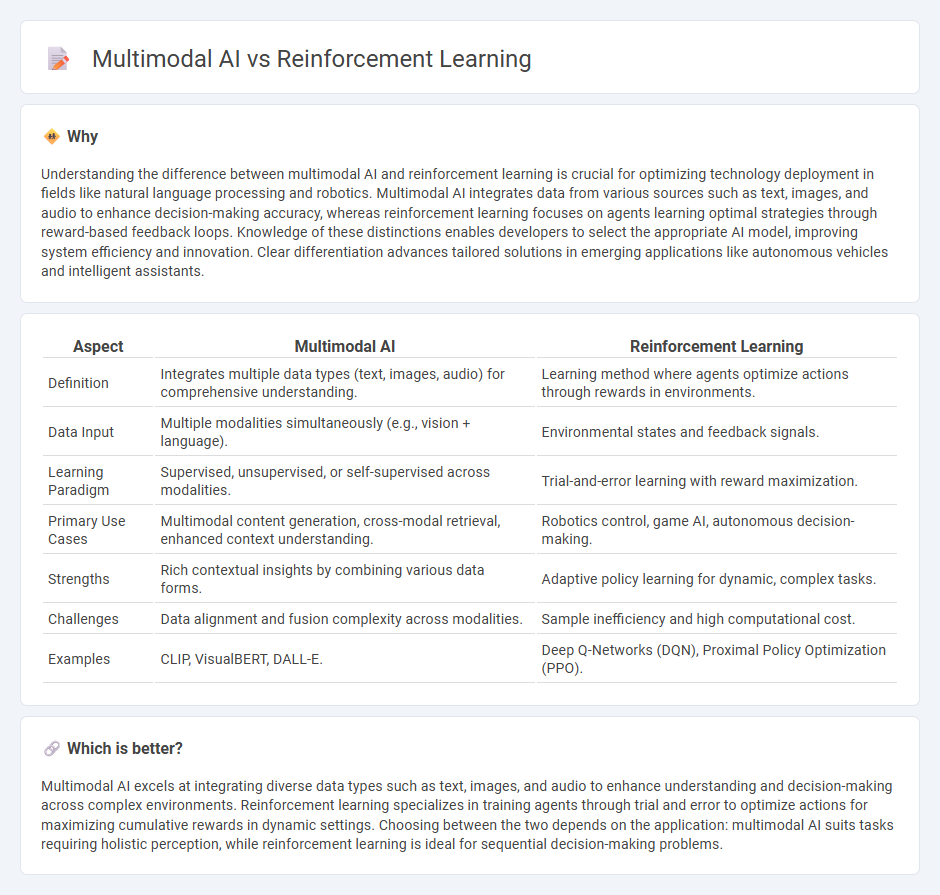
| Aspect | Multimodal AI | Reinforcement Learning |
|---|---|---|
| Definition | Integrates multiple data types (text, images, audio) for comprehensive understanding. | Learning method where agents optimize actions through rewards in environments. |
| Data Input | Multiple modalities simultaneously (e.g., vision + language). | Environmental states and feedback signals. |
| Learning Paradigm | Supervised, unsupervised, or self-supervised across modalities. | Trial-and-error learning with reward maximization. |
| Primary Use Cases | Multimodal content generation, cross-modal retrieval, enhanced context understanding. | Robotics control, game AI, autonomous decision-making. |
| Strengths | Rich contextual insights by combining various data forms. | Adaptive policy learning for dynamic, complex tasks. |
| Challenges | Data alignment and fusion complexity across modalities. | Sample inefficiency and high computational cost. |
| Examples | CLIP, VisualBERT, DALL-E. | Deep Q-Networks (DQN), Proximal Policy Optimization (PPO). |
Which is better?
Multimodal AI excels at integrating diverse data types such as text, images, and audio to enhance understanding and decision-making across complex environments. Reinforcement learning specializes in training agents through trial and error to optimize actions for maximizing cumulative rewards in dynamic settings. Choosing between the two depends on the application: multimodal AI suits tasks requiring holistic perception, while reinforcement learning is ideal for sequential decision-making problems.
Connection
Multimodal AI integrates data from diverse sources like images, text, and audio to create comprehensive understanding models, while reinforcement learning enables systems to learn optimal actions through trial-and-error interactions with the environment. The connection lies in reinforcement learning's ability to improve multimodal AI performance by continuously refining decision-making processes based on feedback from multiple data modalities. This synergy enhances applications such as autonomous driving, robotics, and interactive virtual assistants by enabling adaptive, context-aware behaviors driven by multimodal inputs.
Key Terms
Reward Function (Reinforcement Learning)
Reinforcement learning relies on a well-defined reward function to guide agents toward optimal decision-making by maximizing cumulative rewards over time. In contrast, multimodal AI integrates diverse data types, such as text, images, and audio, often requiring complex fusion techniques but lacks a singular reward signal driving learning objectives. Discover more about how reward functions shape reinforcement learning's adaptability and efficiency in dynamic environments.
Modality Fusion (Multimodal AI)
Modality fusion in multimodal AI integrates diverse data sources like text, images, and audio to enhance decision-making, whereas reinforcement learning optimizes actions through reward-based feedback in dynamic environments. This fusion approach leverages complementary modalities to improve context understanding and model robustness without relying solely on trial-and-error learning. Explore how modality fusion techniques transform AI capabilities by visiting our detailed insights on advanced multimodal systems.
Policy Optimization (Reinforcement Learning)
Policy optimization in reinforcement learning centers on improving decision-making strategies through iterative updates based on reward feedback, targeting an optimal policy for task execution. Multimodal AI integrates diverse data types, such as text, images, and audio, to enhance contextual understanding and decision accuracy, though it often leverages reinforcement learning techniques for policy refinement. Explore how advanced policy optimization methods drive superior performance in complex, multimodal environments for deeper insights.
Source and External Links
Reinforcement Learning Wikipedia - Reinforcement learning is a machine learning technique focusing on training agents to take actions that maximize cumulative rewards through trial and error.
Reinforcement Learning on AWS - Amazon provides an overview of reinforcement learning, highlighting its similarity to behavioral psychology and its applications in decision-making processes.
What is Reinforcement Learning? - This resource explains reinforcement learning as a subset of machine learning where agents learn through trial and error using feedback from their actions to maximize rewards.