Multimodal AI integrates data from various sources such as text, images, and audio, enabling richer and more context-aware understanding compared to traditional deep learning models that typically focus on single data types. Deep learning relies on layered neural networks to model complex patterns in large datasets, excelling in tasks like image recognition and natural language processing. Explore how advancements in multimodal AI are revolutionizing applications by combining diverse data streams for enhanced intelligence.
Why it is important
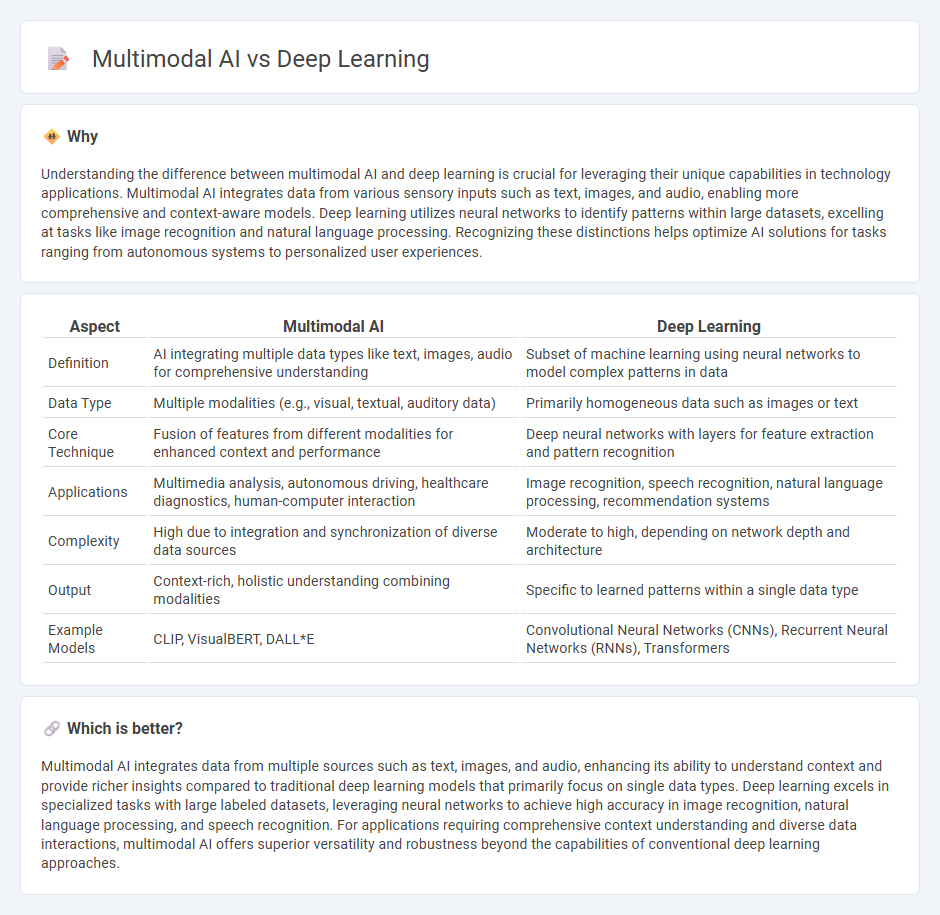
Understanding the difference between multimodal AI and deep learning is crucial for leveraging their unique capabilities in technology applications. Multimodal AI integrates data from various sensory inputs such as text, images, and audio, enabling more comprehensive and context-aware models. Deep learning utilizes neural networks to identify patterns within large datasets, excelling at tasks like image recognition and natural language processing. Recognizing these distinctions helps optimize AI solutions for tasks ranging from autonomous systems to personalized user experiences.
Comparison Table
| Aspect | Multimodal AI | Deep Learning |
|---|---|---|
| Definition | AI integrating multiple data types like text, images, audio for comprehensive understanding | Subset of machine learning using neural networks to model complex patterns in data |
| Data Type | Multiple modalities (e.g., visual, textual, auditory data) | Primarily homogeneous data such as images or text |
| Core Technique | Fusion of features from different modalities for enhanced context and performance | Deep neural networks with layers for feature extraction and pattern recognition |
| Applications | Multimedia analysis, autonomous driving, healthcare diagnostics, human-computer interaction | Image recognition, speech recognition, natural language processing, recommendation systems |
| Complexity | High due to integration and synchronization of diverse data sources | Moderate to high, depending on network depth and architecture |
| Output | Context-rich, holistic understanding combining modalities | Specific to learned patterns within a single data type |
| Example Models | CLIP, VisualBERT, DALL*E | Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Transformers |
Which is better?
Multimodal AI integrates data from multiple sources such as text, images, and audio, enhancing its ability to understand context and provide richer insights compared to traditional deep learning models that primarily focus on single data types. Deep learning excels in specialized tasks with large labeled datasets, leveraging neural networks to achieve high accuracy in image recognition, natural language processing, and speech recognition. For applications requiring comprehensive context understanding and diverse data interactions, multimodal AI offers superior versatility and robustness beyond the capabilities of conventional deep learning approaches.
Connection
Multimodal AI integrates data from multiple sources such as text, images, and audio to enhance machine understanding, leveraging deep learning architectures like convolutional neural networks (CNNs) and transformers to process and correlate diverse inputs. Deep learning models automatically extract hierarchical features from complex multimodal datasets, enabling improved accuracy in tasks like image captioning, natural language processing, and speech recognition. The synergy between multimodal AI and deep learning drives advancements in creating more context-aware and human-like artificial intelligence systems.
Key Terms
Neural Networks
Neural networks form the backbone of deep learning, enabling complex pattern recognition by processing vast amounts of data through multiple layers. Multimodal AI expands this approach by integrating neural networks designed to handle diverse data types like text, images, and audio simultaneously, enhancing the system's contextual understanding. Explore more about how neural network architectures differ and converge in deep learning and multimodal AI applications.
Data Fusion
Deep learning excels in extracting intricate patterns from large-scale datasets using neural networks, while multimodal AI integrates heterogeneous data types such as text, images, and audio for more comprehensive understanding. Data fusion in multimodal AI enables combining complementary information at early, intermediate, or late fusion stages, enhancing context awareness and improving prediction accuracy. Explore more about how data fusion strategies optimize the synergy between deep learning and multimodal AI to unlock advanced AI capabilities.
Representation Learning
Deep learning excels in hierarchical representation learning by extracting features from single-modal data such as images or text, achieving state-of-the-art performance in tasks like image recognition and natural language processing. Multimodal AI extends representation learning by integrating heterogeneous data sources, including vision, language, and audio, enabling richer, context-aware models that better understand complex interactions across modalities. Explore the latest advancements to discover how combining deep learning and multimodal approaches enhances AI's capacity for comprehensive representation learning.
Source and External Links
What is Deep Learning? | Google Cloud - Deep learning is a type of machine learning using artificial neural networks inspired by the human brain, capable of solving problems like image recognition and natural language processing by learning patterns from large labeled datasets.
What is deep learning in AI? - AWS - Deep learning uses artificial neural networks modeled after the human brain with multiple layers that process data at increasing levels of abstraction to solve complex problems such as image classification.
Introduction to Deep Learning - GeeksforGeeks - Deep learning is a subset of AI that uses multi-layered neural networks to autonomously extract intricate data patterns and make decisions from large unstructured datasets, outperforming traditional machine learning in complex tasks like image and speech processing.