Tiny machine learning enables the deployment of AI models on resource-constrained devices, optimizing power consumption and latency by processing data locally. On-device inference executes pre-trained models directly on hardware, enhancing privacy and reducing reliance on cloud connectivity. Explore how these technologies revolutionize embedded systems and edge computing.
Why it is important
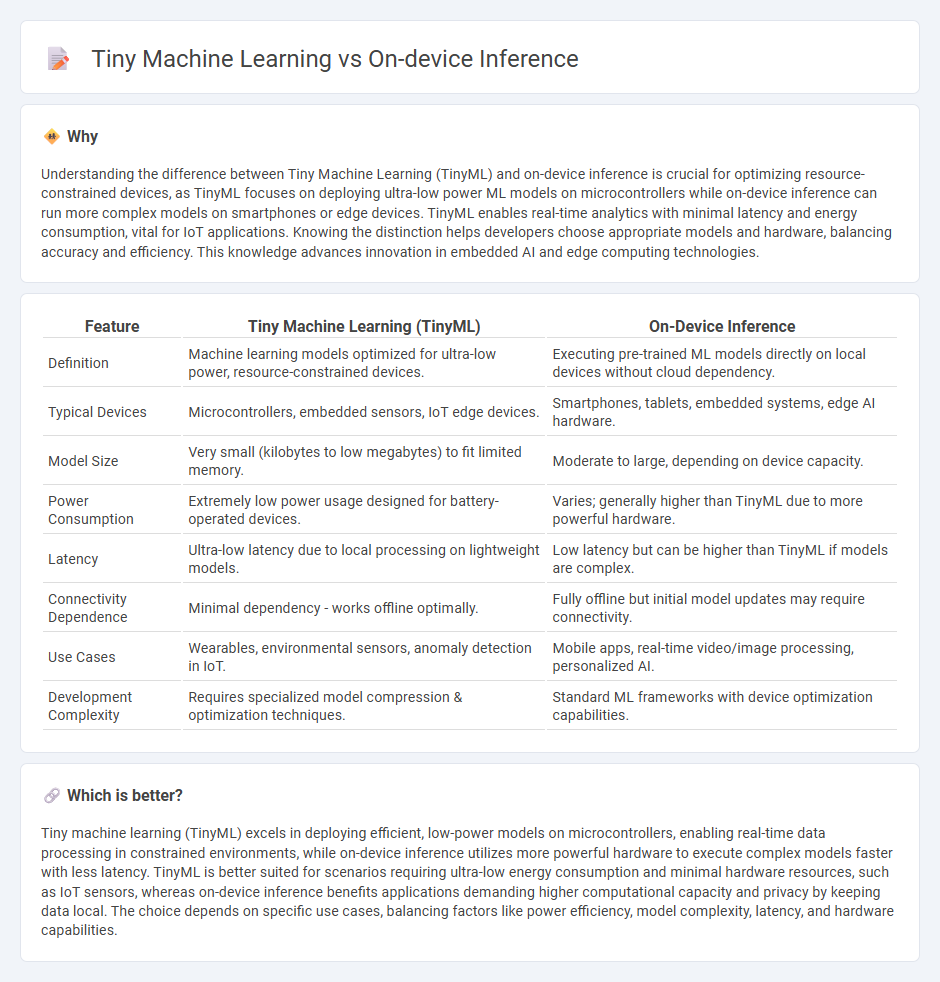
Understanding the difference between Tiny Machine Learning (TinyML) and on-device inference is crucial for optimizing resource-constrained devices, as TinyML focuses on deploying ultra-low power ML models on microcontrollers while on-device inference can run more complex models on smartphones or edge devices. TinyML enables real-time analytics with minimal latency and energy consumption, vital for IoT applications. Knowing the distinction helps developers choose appropriate models and hardware, balancing accuracy and efficiency. This knowledge advances innovation in embedded AI and edge computing technologies.
Comparison Table
| Feature | Tiny Machine Learning (TinyML) | On-Device Inference |
|---|---|---|
| Definition | Machine learning models optimized for ultra-low power, resource-constrained devices. | Executing pre-trained ML models directly on local devices without cloud dependency. |
| Typical Devices | Microcontrollers, embedded sensors, IoT edge devices. | Smartphones, tablets, embedded systems, edge AI hardware. |
| Model Size | Very small (kilobytes to low megabytes) to fit limited memory. | Moderate to large, depending on device capacity. |
| Power Consumption | Extremely low power usage designed for battery-operated devices. | Varies; generally higher than TinyML due to more powerful hardware. |
| Latency | Ultra-low latency due to local processing on lightweight models. | Low latency but can be higher than TinyML if models are complex. |
| Connectivity Dependence | Minimal dependency - works offline optimally. | Fully offline but initial model updates may require connectivity. |
| Use Cases | Wearables, environmental sensors, anomaly detection in IoT. | Mobile apps, real-time video/image processing, personalized AI. |
| Development Complexity | Requires specialized model compression & optimization techniques. | Standard ML frameworks with device optimization capabilities. |
Which is better?
Tiny machine learning (TinyML) excels in deploying efficient, low-power models on microcontrollers, enabling real-time data processing in constrained environments, while on-device inference utilizes more powerful hardware to execute complex models faster with less latency. TinyML is better suited for scenarios requiring ultra-low energy consumption and minimal hardware resources, such as IoT sensors, whereas on-device inference benefits applications demanding higher computational capacity and privacy by keeping data local. The choice depends on specific use cases, balancing factors like power efficiency, model complexity, latency, and hardware capabilities.
Connection
Tiny machine learning enables on-device inference by allowing neural networks to run efficiently on microcontrollers and edge devices with limited computational resources. This technology minimizes latency and enhances privacy by processing data locally rather than transmitting it to cloud servers. Optimized algorithms and model compression techniques are essential for achieving effective on-device inference in resource-constrained environments.
Key Terms
Edge Computing
On-device inference processes data directly on edge devices such as smartphones and IoT sensors, minimizing latency and preserving privacy by avoiding cloud dependency. Tiny Machine Learning (TinyML) specializes in deploying ultra-low-power models on microcontrollers, enabling intelligent decision-making in constrained environments with limited computational resources. Explore the future of Edge Computing by understanding how these technologies revolutionize real-time analytics and autonomous system capabilities.
Model Compression
Model compression techniques play a crucial role in both on-device inference and tiny machine learning by reducing model size and computational requirements to fit resource-constrained environments like mobile devices and IoT sensors. While on-device inference emphasizes real-time processing and privacy by running compressed models locally, tiny machine learning specifically targets ultra-low-power devices using aggressive quantization, pruning, and knowledge distillation. Explore detailed comparisons and cutting-edge compression strategies to maximize performance and efficiency in edge AI applications.
Microcontrollers
On-device inference enables microcontrollers to process data locally, reducing latency and enhancing privacy by eliminating the need for cloud communication. Tiny Machine Learning (TinyML) specifically targets resource-constrained microcontrollers to run efficient ML models with minimal power consumption and memory usage. Discover how leveraging these techniques can transform embedded systems by exploring state-of-the-art advancements and practical applications.
Source and External Links
On-Device Neural Net Inference with Mobile GPUs - Google Research - On-device inference runs machine learning models directly on mobile hardware such as GPUs, enabling lower latency and increased privacy while addressing mobile CPU constraints by using mobile GPUs for real-time deep neural network inference on both Android and iOS devices.
Exploring the Boundaries of On-Device Inference - arXiv - On-device inference provides energy-efficient, responsive, and privacy-preserving ML on resource-limited edge devices but is limited by model simplicity, leading to hierarchical inference systems that combine local and remote inference to reduce latency and energy consumption compared to on-device inference alone.
AI disruption is driving innovation in on-device inference - Qualcomm - The industry is rapidly innovating on-device AI inference, shifting AI workloads from the cloud to devices like smartphones and IoT hardware, unlocking new value through faster, privacy-centric, and efficient edge AI applications.