Deep learning forecasting leverages multilayer neural networks to model complex, non-linear patterns in accounting data, providing robust predictions for financial trends and risk assessments. Support vector regression (SVR) focuses on finding the optimal hyperplane in high-dimensional space to perform precise regression analysis, often excelling in smaller datasets with clear margin definitions. Explore how these advanced techniques can transform financial forecasting accuracy and decision-making in accounting.
Why it is important
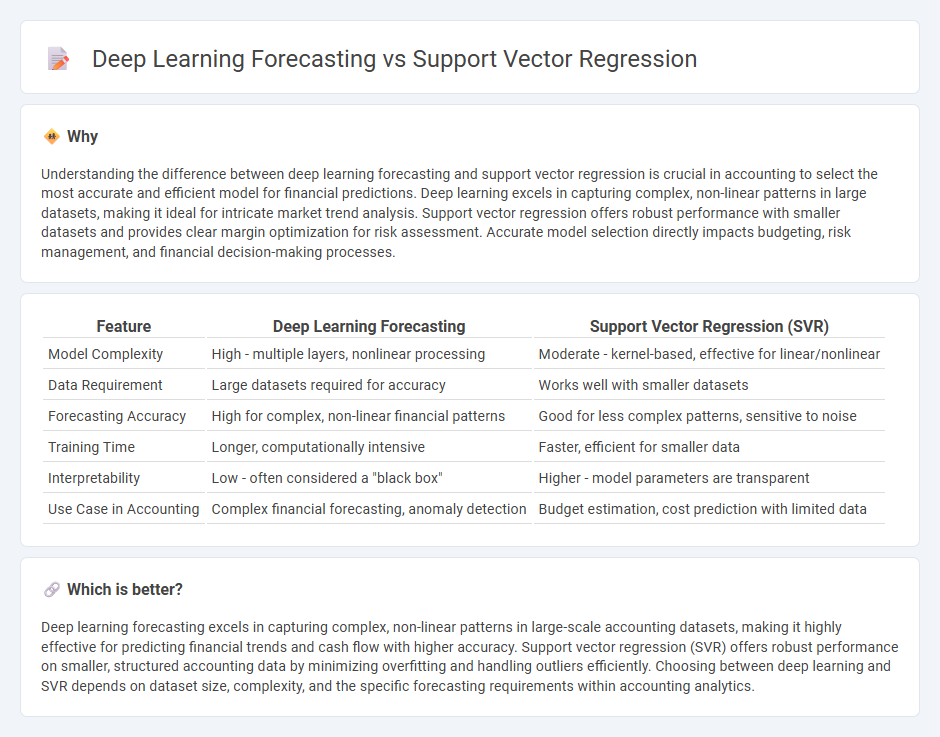
Understanding the difference between deep learning forecasting and support vector regression is crucial in accounting to select the most accurate and efficient model for financial predictions. Deep learning excels in capturing complex, non-linear patterns in large datasets, making it ideal for intricate market trend analysis. Support vector regression offers robust performance with smaller datasets and provides clear margin optimization for risk assessment. Accurate model selection directly impacts budgeting, risk management, and financial decision-making processes.
Comparison Table
| Feature | Deep Learning Forecasting | Support Vector Regression (SVR) |
|---|---|---|
| Model Complexity | High - multiple layers, nonlinear processing | Moderate - kernel-based, effective for linear/nonlinear |
| Data Requirement | Large datasets required for accuracy | Works well with smaller datasets |
| Forecasting Accuracy | High for complex, non-linear financial patterns | Good for less complex patterns, sensitive to noise |
| Training Time | Longer, computationally intensive | Faster, efficient for smaller data |
| Interpretability | Low - often considered a "black box" | Higher - model parameters are transparent |
| Use Case in Accounting | Complex financial forecasting, anomaly detection | Budget estimation, cost prediction with limited data |
Which is better?
Deep learning forecasting excels in capturing complex, non-linear patterns in large-scale accounting datasets, making it highly effective for predicting financial trends and cash flow with higher accuracy. Support vector regression (SVR) offers robust performance on smaller, structured accounting data by minimizing overfitting and handling outliers efficiently. Choosing between deep learning and SVR depends on dataset size, complexity, and the specific forecasting requirements within accounting analytics.
Connection
Deep learning forecasting and Support Vector Regression (SVR) intersect in accounting by enhancing predictive accuracy for financial data analysis and trend identification. Deep learning models capture complex, non-linear patterns in large accounting datasets, while SVR excels in managing smaller, noisy datasets with robust regression capabilities. Combining these methods enables accountants to forecast revenues, expenses, and risks with improved precision and reliability.
Key Terms
Model Complexity
Support vector regression (SVR) offers a simpler model architecture with fewer hyperparameters, making it efficient for small to medium-sized datasets due to its ability to find optimal hyperplanes in high-dimensional spaces. Deep learning forecasting models, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), involve complex architectures with multiple layers and extensive parameter tuning, which require larger datasets and more computational resources to capture nonlinear temporal dependencies effectively. Explore further to understand how model complexity influences forecasting accuracy and computational requirements in different application scenarios.
Overfitting
Support vector regression (SVR) offers robust overfitting control through margin maximization and kernel tricks, effectively enhancing generalization in smaller datasets. Deep learning forecasting models, such as recurrent neural networks (RNNs) or transformers, are prone to overfitting due to their high complexity and large parameter space but counteract this risk using dropout, early stopping, and extensive training data. Explore deeper insights and techniques to balance model complexity and generalization in predictive analytics.
Feature Engineering
Support vector regression (SVR) excels in forecasting tasks that benefit from carefully engineered features, leveraging kernel functions to handle nonlinearity with limited data. Deep learning forecasting models, such as LSTM and CNN, automatically extract complex patterns from raw data but often require extensive feature engineering when domain-specific insights are integrated. Explore the advantages and challenges of feature engineering in SVR and deep learning to enhance forecasting accuracy.
Source and External Links
Support Vector Regression SVR - Support Vector Regression (SVR) works by fitting a regression line surrounded by an epsilon-insensitive tube, where errors within the tube are ignored to minimize overall error and produce a robust regression model.
Support Vector Regression (SVR) using Linear and Non-Linear Kernels in Scikit Learn - SVR is a type of Support Vector Machine used for regression that predicts continuous outputs, capable of using both linear and non-linear kernels to capture various data patterns depending on complexity.
Support vector machine - Support Vector Machines (SVMs) extend to regression (SVR) by finding functions within an epsilon margin that avoid penalties for errors inside this margin, applying kernel tricks to perform linear or non-linear regression in high-dimensional space.