Generative video leverages deep learning models to create entirely new video content from textual or image inputs, enabling innovative applications in entertainment and media production. Video super-resolution focuses on enhancing the quality of existing videos by increasing resolution and improving detail through advanced algorithms such as convolutional neural networks. Explore the latest advancements to understand how these technologies are transforming digital video experiences.
Why it is important
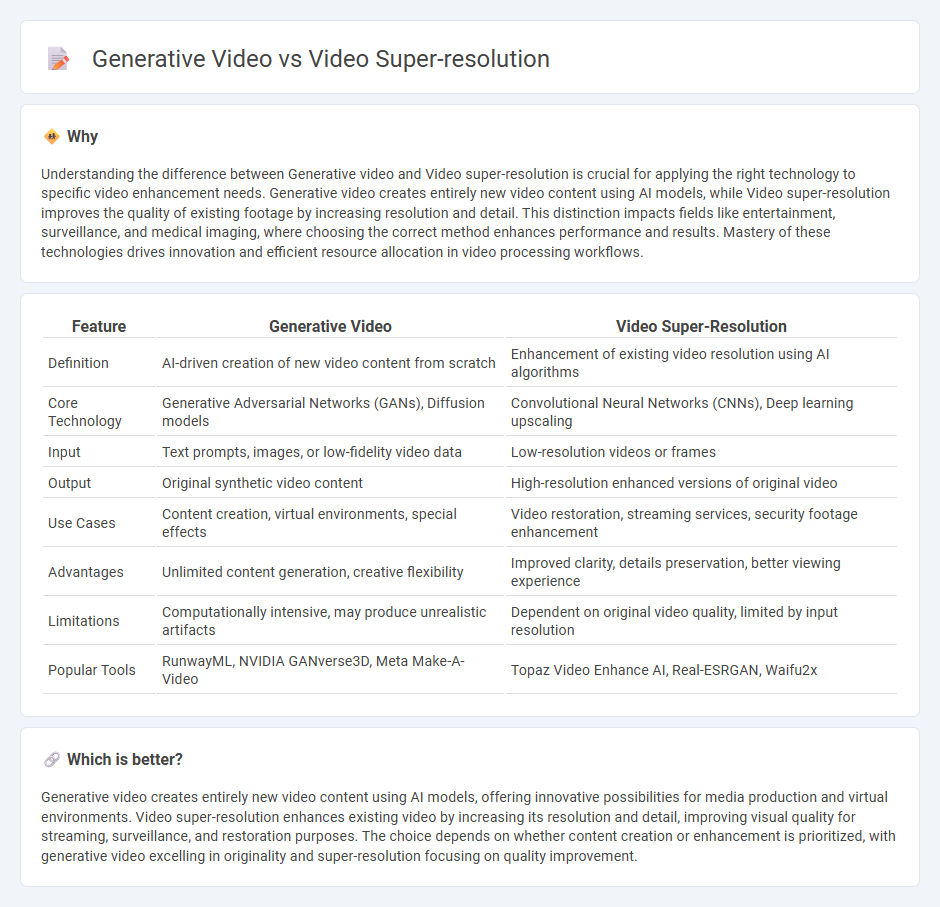
Understanding the difference between Generative video and Video super-resolution is crucial for applying the right technology to specific video enhancement needs. Generative video creates entirely new video content using AI models, while Video super-resolution improves the quality of existing footage by increasing resolution and detail. This distinction impacts fields like entertainment, surveillance, and medical imaging, where choosing the correct method enhances performance and results. Mastery of these technologies drives innovation and efficient resource allocation in video processing workflows.
Comparison Table
| Feature | Generative Video | Video Super-Resolution |
|---|---|---|
| Definition | AI-driven creation of new video content from scratch | Enhancement of existing video resolution using AI algorithms |
| Core Technology | Generative Adversarial Networks (GANs), Diffusion models | Convolutional Neural Networks (CNNs), Deep learning upscaling |
| Input | Text prompts, images, or low-fidelity video data | Low-resolution videos or frames |
| Output | Original synthetic video content | High-resolution enhanced versions of original video |
| Use Cases | Content creation, virtual environments, special effects | Video restoration, streaming services, security footage enhancement |
| Advantages | Unlimited content generation, creative flexibility | Improved clarity, details preservation, better viewing experience |
| Limitations | Computationally intensive, may produce unrealistic artifacts | Dependent on original video quality, limited by input resolution |
| Popular Tools | RunwayML, NVIDIA GANverse3D, Meta Make-A-Video | Topaz Video Enhance AI, Real-ESRGAN, Waifu2x |
Which is better?
Generative video creates entirely new video content using AI models, offering innovative possibilities for media production and virtual environments. Video super-resolution enhances existing video by increasing its resolution and detail, improving visual quality for streaming, surveillance, and restoration purposes. The choice depends on whether content creation or enhancement is prioritized, with generative video excelling in originality and super-resolution focusing on quality improvement.
Connection
Generative video leverages advanced AI models to create realistic video content from textual or visual inputs, enhancing creativity and content production. Video super-resolution improves the quality of existing videos by increasing their resolution and detail using deep learning algorithms, often applied to upscaled generative video outputs. Integrating generative video with video super-resolution results in high-quality, innovative video content that pushes the boundaries of digital media and entertainment technology.
Key Terms
Upscaling Algorithms
Video super-resolution leverages advanced upscaling algorithms such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to enhance video frame resolution by reconstructing finer details from low-resolution inputs. In contrast, generative video models utilize generative adversarial networks (GANs) to create high-resolution video frames, synthesizing realistic textures and motion that go beyond simple upscaling. Explore more about how these cutting-edge upscaling algorithms differ in boosting video quality and application.
Synthetic Content Generation
Video super-resolution enhances low-resolution footage by reconstructing finer details and improving clarity through advanced AI algorithms, resulting in sharper and more visually appealing videos. Generative video techniques create entirely new synthetic content by leveraging deep learning models like GANs and transformers to generate realistic scenes and animations from scratch or input prompts. Explore the latest advancements in synthetic content generation to understand how these technologies are transforming multimedia production.
Temporal Consistency
Video super-resolution enhances low-resolution footage by increasing pixel density and detail while prioritizing temporal consistency to avoid flickering or motion artifacts across frames. Generative video models create entirely new video content with plausible motion and appearance, often balancing creativity with temporal coherence but sometimes struggling with maintaining frame-to-frame consistency. Explore the latest research and techniques to understand how advances in temporal consistency impact both video super-resolution and generative video technologies.
Source and External Links
Video super-resolution - Wikipedia - Video super-resolution (VSR) is the process of generating high-resolution video frames from low-resolution inputs while preserving motion consistency and fine details, using advanced algorithms that exploit both spatial and temporal information in video sequences.
Video super resolution in Microsoft Edge - Windows Blog - Microsoft Edge uses machine learning-powered, graphics card-agnostic algorithms to upscale low-resolution videos (below 720p) on supported devices, removing compression artifacts and enhancing sharpness during playback on select GPUs and under specific conditions.
Pixel Perfect: RTX Video Super Resolution Now Available - NVIDIA Blog - NVIDIA's RTX Video Super Resolution employs AI on GeForce RTX 40 and 30 Series GPUs to upscale streaming video up to 4K, reducing blocky artifacts and improving clarity for content originally streamed at 1080p or lower.