Generative video leverages deep learning models to create entirely new visual content from scratch, utilizing techniques like GANs (Generative Adversarial Networks) to produce realistic animations or scenes. Video recognition focuses on analyzing existing footage by identifying objects, actions, and patterns through convolutional neural networks (CNNs) and computer vision algorithms to enable applications such as surveillance, content tagging, and autonomous navigation. Explore the evolving capabilities and use cases of generative video and video recognition technologies to understand their impact on digital media and AI innovation.
Why it is important
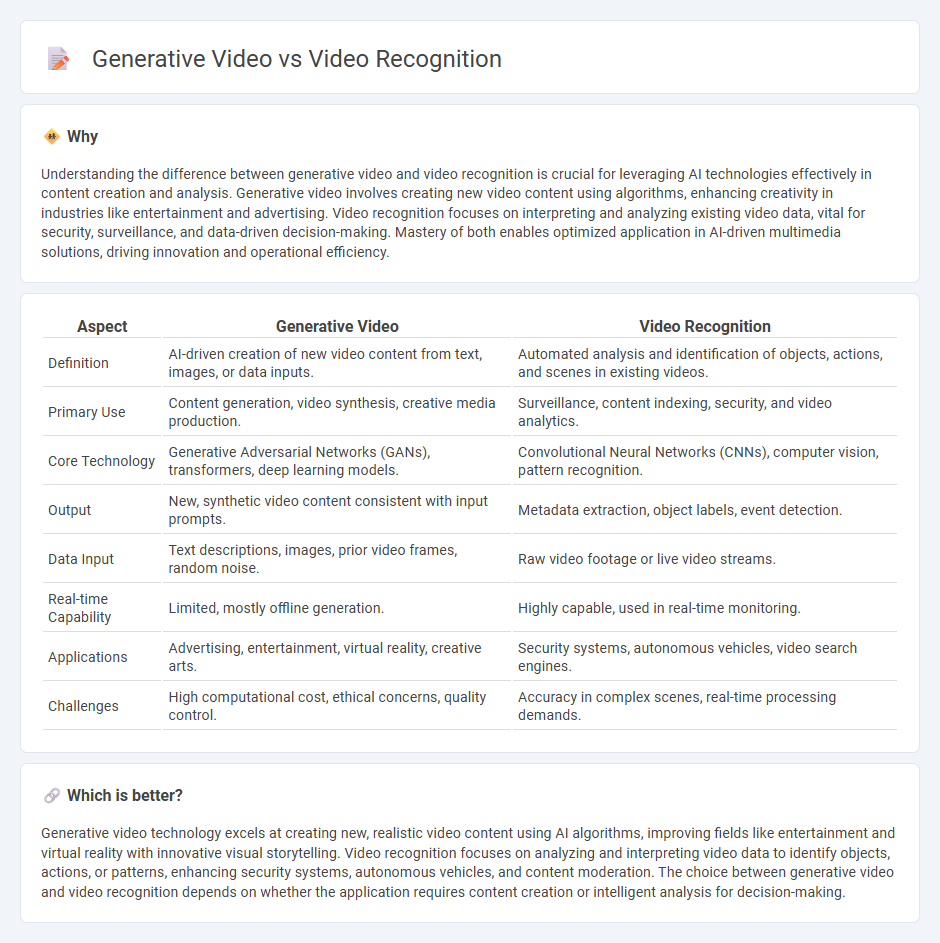
Understanding the difference between generative video and video recognition is crucial for leveraging AI technologies effectively in content creation and analysis. Generative video involves creating new video content using algorithms, enhancing creativity in industries like entertainment and advertising. Video recognition focuses on interpreting and analyzing existing video data, vital for security, surveillance, and data-driven decision-making. Mastery of both enables optimized application in AI-driven multimedia solutions, driving innovation and operational efficiency.
Comparison Table
| Aspect | Generative Video | Video Recognition |
|---|---|---|
| Definition | AI-driven creation of new video content from text, images, or data inputs. | Automated analysis and identification of objects, actions, and scenes in existing videos. |
| Primary Use | Content generation, video synthesis, creative media production. | Surveillance, content indexing, security, and video analytics. |
| Core Technology | Generative Adversarial Networks (GANs), transformers, deep learning models. | Convolutional Neural Networks (CNNs), computer vision, pattern recognition. |
| Output | New, synthetic video content consistent with input prompts. | Metadata extraction, object labels, event detection. |
| Data Input | Text descriptions, images, prior video frames, random noise. | Raw video footage or live video streams. |
| Real-time Capability | Limited, mostly offline generation. | Highly capable, used in real-time monitoring. |
| Applications | Advertising, entertainment, virtual reality, creative arts. | Security systems, autonomous vehicles, video search engines. |
| Challenges | High computational cost, ethical concerns, quality control. | Accuracy in complex scenes, real-time processing demands. |
Which is better?
Generative video technology excels at creating new, realistic video content using AI algorithms, improving fields like entertainment and virtual reality with innovative visual storytelling. Video recognition focuses on analyzing and interpreting video data to identify objects, actions, or patterns, enhancing security systems, autonomous vehicles, and content moderation. The choice between generative video and video recognition depends on whether the application requires content creation or intelligent analysis for decision-making.
Connection
Generative video leverages artificial intelligence to create realistic video content by learning from vast datasets, while video recognition uses machine learning models to analyze and understand video frames for object detection and scene identification. These technologies share underlying deep learning architectures, enabling generative models to improve video content based on patterns recognized during video analysis. Integration of video recognition enhances generative video accuracy by providing semantic context, improving applications in surveillance, entertainment, and augmented reality.
Key Terms
Object Detection — Video Recognition
Video recognition relies on advanced object detection algorithms to accurately identify and classify entities within video frames, enhancing tasks like surveillance and autonomous driving. Generative video employs deep learning models to create new video content, with object detection playing a crucial role in maintaining realism by accurately placing and animating objects. Explore in-depth differences and applications of video recognition and generative video in object detection technologies.
Frame Synthesis — Generative Video
Video recognition technology analyzes frames to identify objects, actions, and scenes, enhancing applications like surveillance and content indexing. Generative video, particularly in frame synthesis, uses AI models to create new frames, enabling seamless animation and video editing by predicting subsequent frames based on learned patterns. Explore how generative video revolutionizes frame synthesis for innovative visual media applications.
Temporal Analysis — Video Recognition
Video recognition relies on temporal analysis to identify and classify actions or events by processing sequential frames and extracting motion patterns using techniques like recurrent neural networks (RNNs) and temporal convolutional networks (TCNs). Generative video models emphasize temporal coherence by synthesizing smooth frame transitions and realistic motion trajectories, often leveraging generative adversarial networks (GANs) or variational autoencoders (VAEs). Explore further to understand how temporal analysis shapes advancements in video recognition and generative video technologies.
Source and External Links
Training Machines to Observe Our World: Examining Video Recognition - Video recognition enables computers to interpret and understand video content, identifying objects, people, actions, and events using AI and deep learning to extract meaningful insights from video data.
AI Video Recognition: Practical Tips for Getting Started - AI video recognition applies machine learning models to analyze video for tasks like object, face, and activity recognition, automating video tagging, categorization, and content discovery across industries.
Amazon Rekognition - Amazon Rekognition offers APIs for automated image and video analysis, including face detection, custom labels, content moderation, and identity verification, without requiring machine learning expertise.