Federated learning enables decentralized model training across multiple devices while preserving data privacy, whereas collaborative filtering relies on centralized user-data aggregation to generate recommendations. This decentralized approach enhances security by keeping sensitive information on local devices, contrasting with the traditional method's dependency on centralized data storage. Explore the distinct benefits and applications of federated learning versus collaborative filtering to understand their impact on modern technologies.
Why it is important
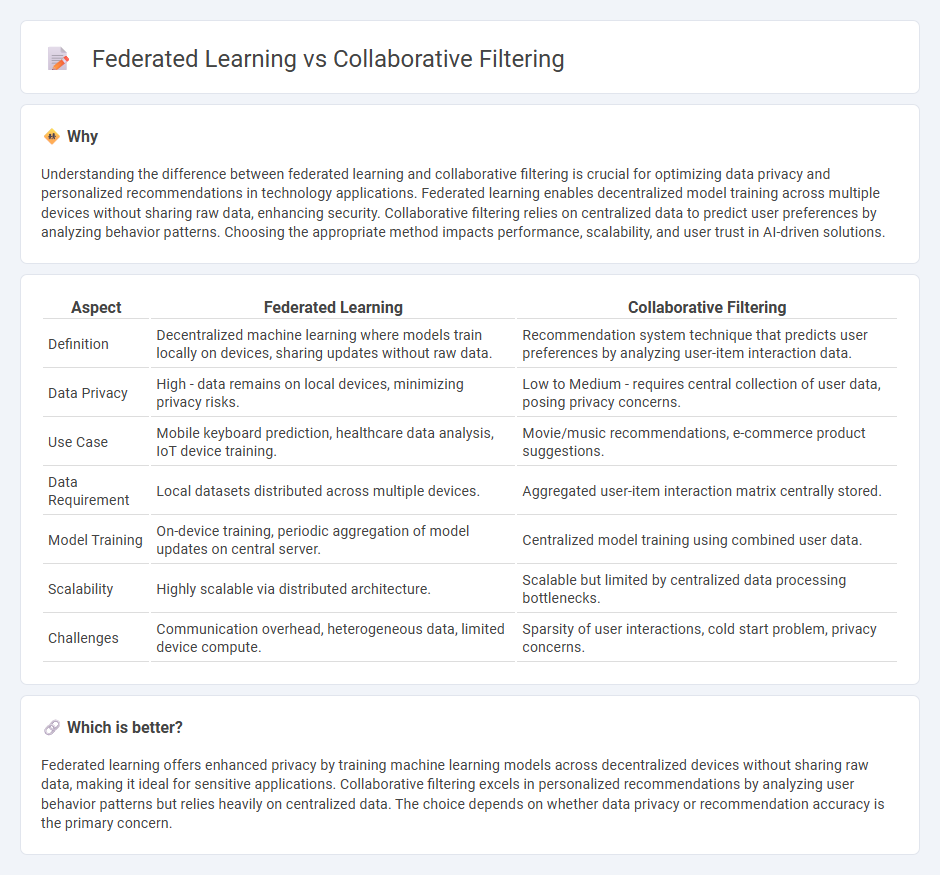
Understanding the difference between federated learning and collaborative filtering is crucial for optimizing data privacy and personalized recommendations in technology applications. Federated learning enables decentralized model training across multiple devices without sharing raw data, enhancing security. Collaborative filtering relies on centralized data to predict user preferences by analyzing behavior patterns. Choosing the appropriate method impacts performance, scalability, and user trust in AI-driven solutions.
Comparison Table
| Aspect | Federated Learning | Collaborative Filtering |
|---|---|---|
| Definition | Decentralized machine learning where models train locally on devices, sharing updates without raw data. | Recommendation system technique that predicts user preferences by analyzing user-item interaction data. |
| Data Privacy | High - data remains on local devices, minimizing privacy risks. | Low to Medium - requires central collection of user data, posing privacy concerns. |
| Use Case | Mobile keyboard prediction, healthcare data analysis, IoT device training. | Movie/music recommendations, e-commerce product suggestions. |
| Data Requirement | Local datasets distributed across multiple devices. | Aggregated user-item interaction matrix centrally stored. |
| Model Training | On-device training, periodic aggregation of model updates on central server. | Centralized model training using combined user data. |
| Scalability | Highly scalable via distributed architecture. | Scalable but limited by centralized data processing bottlenecks. |
| Challenges | Communication overhead, heterogeneous data, limited device compute. | Sparsity of user interactions, cold start problem, privacy concerns. |
Which is better?
Federated learning offers enhanced privacy by training machine learning models across decentralized devices without sharing raw data, making it ideal for sensitive applications. Collaborative filtering excels in personalized recommendations by analyzing user behavior patterns but relies heavily on centralized data. The choice depends on whether data privacy or recommendation accuracy is the primary concern.
Connection
Federated learning enables decentralized data processing by training machine learning models across multiple devices without sharing raw data, preserving privacy in collaborative filtering systems. Collaborative filtering relies on user preference data to make personalized recommendations, which can be enhanced through federated learning to maintain data security while aggregating insights. This combination allows recommendation algorithms to improve accuracy by leveraging distributed user data while minimizing privacy risks and compliance concerns.
Key Terms
Personalization
Collaborative filtering leverages collective user behavior data to deliver personalized recommendations by analyzing patterns across a centralized database, enhancing user experience through shared preferences. Federated learning offers a privacy-preserving alternative by training machine learning models locally on user devices, enabling personalized insights without the need to transfer sensitive data to a central server. Discover how these approaches shape the future of personalized technology and safeguard user privacy.
Data privacy
Collaborative filtering relies on centralized data collection, which raises significant privacy concerns due to users' sensitive information being stored and processed in a single location. Federated learning addresses these concerns by enabling model training directly on users' devices, ensuring personal data never leaves the local environment and greatly enhancing data privacy. Explore how these approaches impact privacy standards and choose the best solution for your application.
Distributed computation
Collaborative filtering relies on centralized data aggregation to predict user preferences, while federated learning enables distributed computation by training models directly on decentralized devices without sharing raw data. This approach in federated learning enhances privacy and reduces communication overhead compared to collaborative filtering's data-intensive centralization. Explore further to understand how distributed computation shapes these methodologies in modern AI systems.
Source and External Links
What Is Collaborative Filtering: A Simple Introduction - This article provides an introduction to collaborative filtering, explaining how it works by analyzing user behavior and preferences to recommend items.
Collaborative Filtering - This Wikipedia entry describes the methodology and applications of collaborative filtering, including both user-based and item-based approaches.
Collaborative Filtering: Your Guide to Smarter Recommendations - This tutorial offers insights into collaborative filtering, its implementation in Python, and its role in creating personalized recommendations.