Self-supervised learning leverages labeled data generated from the input itself to train models, enabling more efficient feature extraction compared to traditional unsupervised learning, which relies solely on unlabeled data to identify patterns. Advances in self-supervised algorithms have significantly improved performance in natural language processing and computer vision tasks by reducing the dependency on large labeled datasets. Explore the distinctions and applications of self-supervised and unsupervised learning to understand how they revolutionize AI development.
Why it is important
Understanding the difference between self-supervised learning and unsupervised learning is crucial for optimizing artificial intelligence models, as self-supervised learning uses labeled data generated from the data itself to improve accuracy, while unsupervised learning identifies patterns in unlabeled data without predefined outputs. Self-supervised learning has proven effective in natural language processing and computer vision tasks by leveraging data representations, whereas unsupervised learning excels in clustering and anomaly detection. Choosing the appropriate method directly impacts the efficiency and effectiveness of machine learning applications in technology development. Mastery of these concepts enables engineers and data scientists to design more accurate and scalable AI systems.
Comparison Table
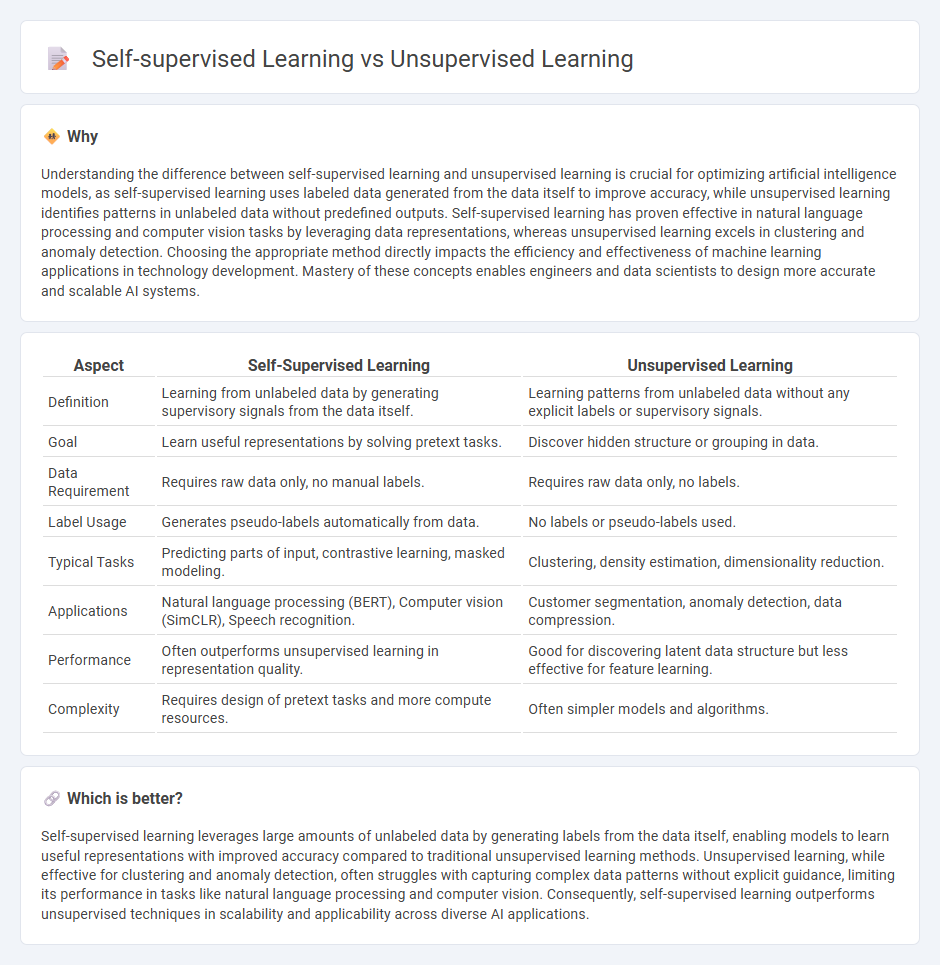
| Aspect | Self-Supervised Learning | Unsupervised Learning |
|---|---|---|
| Definition | Learning from unlabeled data by generating supervisory signals from the data itself. | Learning patterns from unlabeled data without any explicit labels or supervisory signals. |
| Goal | Learn useful representations by solving pretext tasks. | Discover hidden structure or grouping in data. |
| Data Requirement | Requires raw data only, no manual labels. | Requires raw data only, no labels. |
| Label Usage | Generates pseudo-labels automatically from data. | No labels or pseudo-labels used. |
| Typical Tasks | Predicting parts of input, contrastive learning, masked modeling. | Clustering, density estimation, dimensionality reduction. |
| Applications | Natural language processing (BERT), Computer vision (SimCLR), Speech recognition. | Customer segmentation, anomaly detection, data compression. |
| Performance | Often outperforms unsupervised learning in representation quality. | Good for discovering latent data structure but less effective for feature learning. |
| Complexity | Requires design of pretext tasks and more compute resources. | Often simpler models and algorithms. |
Which is better?
Self-supervised learning leverages large amounts of unlabeled data by generating labels from the data itself, enabling models to learn useful representations with improved accuracy compared to traditional unsupervised learning methods. Unsupervised learning, while effective for clustering and anomaly detection, often struggles with capturing complex data patterns without explicit guidance, limiting its performance in tasks like natural language processing and computer vision. Consequently, self-supervised learning outperforms unsupervised techniques in scalability and applicability across diverse AI applications.
Connection
Self-supervised learning bridges the gap between supervised and unsupervised learning by generating labels from the data itself, enabling models to learn useful representations without explicit annotations. Both approaches leverage unlabeled data to improve performance, with unsupervised learning focusing on discovering inherent structures and patterns within the data. Techniques such as contrastive learning and autoencoders exemplify the synergy between self-supervised and unsupervised methods in advancing artificial intelligence.
Key Terms
Clustering
Unsupervised learning in clustering involves identifying inherent groupings in data without labeled outcomes, relying solely on data structure and similarity measures like k-means or hierarchical clustering. Self-supervised learning enhances clustering by generating pseudo-labels from the data itself, often improving feature representations through pretext tasks and leading to better cluster separation. Explore the nuances and applications of both approaches to optimize clustering performance in your projects.
Representation learning
Unsupervised learning discovers patterns in unlabeled data without explicit guidance, often using clustering or dimensionality reduction to learn data representations. Self-supervised learning generates pseudo-labels from the data itself, enabling models to learn richer and more informative representations by solving pretext tasks like predicting missing parts or contrasting data views. Explore how these approaches enhance representation learning and drive advances in AI applications.
Data labeling
Unsupervised learning algorithms analyze raw data without any labeled examples, identifying hidden patterns and structures independently. Self-supervised learning utilizes automatically generated labels derived from the data itself, enabling models to learn meaningful representations without manual annotation. Discover more about how these approaches impact data labeling efficiency and model performance.
Source and External Links
What is unsupervised learning? - Unsupervised learning refers to machine learning techniques that analyze unlabeled data to discover patterns, without any human supervision or explicit output labels, enabling models to infer rules and group data into clusters based on similarities.
What is Unsupervised Learning? - It is a machine learning branch focused on finding hidden patterns and relationships in unlabeled data through models that learn without any predefined outputs or categories, discovering groups independently.
Unsupervised learning - A machine learning framework where algorithms learn exclusively from unlabeled data, with common methods including clustering, dimensionality reduction, and training neural networks for representation learning without labeled guidance.