Multimodal AI integrates data from multiple sources such as text, images, and audio, enabling it to understand and generate more contextually rich responses compared to unimodal AI, which relies on a single type of input. This fusion of diverse data types allows multimodal AI systems to achieve higher accuracy in tasks like image captioning, speech recognition, and natural language understanding. Explore the advancements shaping the future of intelligent systems by diving deeper into multimodal versus unimodal AI technologies.
Why it is important
Understanding the difference between multimodal AI and unimodal AI is crucial for leveraging the right technology in applications requiring diverse data inputs such as text, images, and audio. Multimodal AI integrates and analyzes multiple data types simultaneously, enhancing accuracy and context comprehension beyond the capabilities of unimodal AI, which processes only one data type at a time. This knowledge enables developers to create more sophisticated AI systems for complex tasks like autonomous driving, medical diagnosis, and natural language understanding. Choosing the appropriate AI model ensures optimal performance and resource efficiency in real-world deployments.
Comparison Table
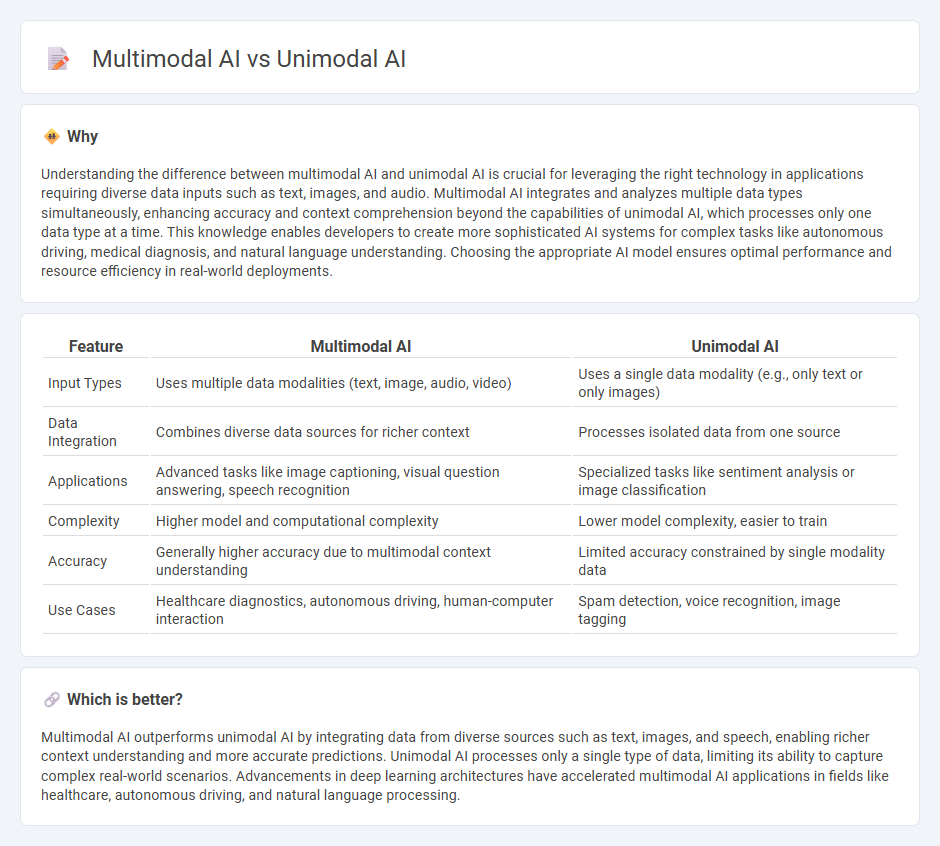
| Feature | Multimodal AI | Unimodal AI |
|---|---|---|
| Input Types | Uses multiple data modalities (text, image, audio, video) | Uses a single data modality (e.g., only text or only images) |
| Data Integration | Combines diverse data sources for richer context | Processes isolated data from one source |
| Applications | Advanced tasks like image captioning, visual question answering, speech recognition | Specialized tasks like sentiment analysis or image classification |
| Complexity | Higher model and computational complexity | Lower model complexity, easier to train |
| Accuracy | Generally higher accuracy due to multimodal context understanding | Limited accuracy constrained by single modality data |
| Use Cases | Healthcare diagnostics, autonomous driving, human-computer interaction | Spam detection, voice recognition, image tagging |
Which is better?
Multimodal AI outperforms unimodal AI by integrating data from diverse sources such as text, images, and speech, enabling richer context understanding and more accurate predictions. Unimodal AI processes only a single type of data, limiting its ability to capture complex real-world scenarios. Advancements in deep learning architectures have accelerated multimodal AI applications in fields like healthcare, autonomous driving, and natural language processing.
Connection
Multimodal AI integrates data from multiple sources such as text, images, and audio, enhancing understanding and contextual awareness beyond unimodal AI, which focuses on a single data type. This connection allows unimodal models to be combined or extended into multimodal systems, improving overall performance in tasks like image captioning or voice-activated assistants. Advances in deep learning architectures, such as transformers, enable seamless fusion of unimodal inputs, driving innovation in AI applications across industries.
Key Terms
Data Modality
Unimodal AI processes and analyzes data from a single modality such as text, images, or audio, optimizing performance within that specific data type but limiting flexibility across diverse inputs. Multimodal AI integrates and correlates information from multiple data modalities simultaneously, enhancing contextual understanding and enabling more sophisticated decision-making in complex environments. Discover more about how these AI approaches impact your data strategy and application possibilities.
Fusion
Unimodal AI processes data from a single source, such as text or images, while multimodal AI combines multiple data types through fusion techniques to enhance understanding and decision-making. Fusion strategies in multimodal AI include early fusion, which integrates raw data, and late fusion, which merges individual model outputs, optimizing the synergy of diverse information. Explore the latest advancements in fusion methods to unlock the full potential of multimodal AI systems.
Representation Learning
Unimodal AI focuses on representation learning within a single data type, such as text, images, or audio, optimizing models to extract features uniquely suited to one modality. Multimodal AI integrates diverse data types, combining textual, visual, and auditory inputs to create richer and more comprehensive representations that enhance understanding and prediction accuracy. Explore the advantages of these approaches and how they transform tasks like content generation and decision-making.
Source and External Links
What is Unimodal AI? - TestingDocs.com - Unimodal AI refers to artificial intelligence systems that process and work with only one type of data or modality at a time, such as text, images, audio, or video, and are typically specialized and optimized for that single data type.
Unimodal vs. Multimodal AI: Key Differences Explained - Index.dev - Unimodal AI models are designed to analyze and process just one kind of data input, using architectures tailored to that modality--like CNNs for images or RNNs for text--with training, feature extraction, and evaluation all focused on that single data source.
Multimodal AI Vs. Unimodal AI: Key Differences Explained - Unimodal AI relies on a single input-output pipeline, excelling in tasks specific to its modality (e.g., text generation, image classification, or speech recognition) but unable to process or understand other data types without significant modification.