Generative video technology creates new video content using algorithms and artificial intelligence, enabling dynamic and customizable visual experiences without the need for traditional filming. Video annotation involves labeling and tagging video content to enhance machine learning models for tasks such as object detection, action recognition, and automated editing. Explore the key differences and applications of generative video versus video annotation to understand their impact on the future of multimedia.
Why it is important
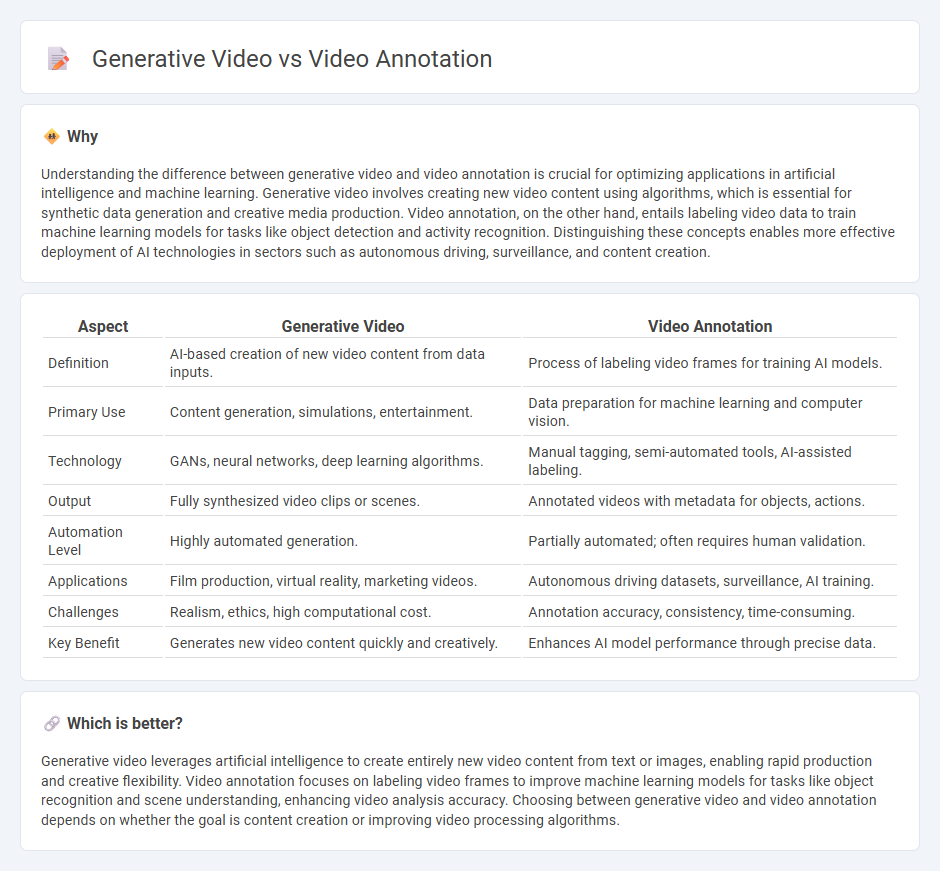
Understanding the difference between generative video and video annotation is crucial for optimizing applications in artificial intelligence and machine learning. Generative video involves creating new video content using algorithms, which is essential for synthetic data generation and creative media production. Video annotation, on the other hand, entails labeling video data to train machine learning models for tasks like object detection and activity recognition. Distinguishing these concepts enables more effective deployment of AI technologies in sectors such as autonomous driving, surveillance, and content creation.
Comparison Table
| Aspect | Generative Video | Video Annotation |
|---|---|---|
| Definition | AI-based creation of new video content from data inputs. | Process of labeling video frames for training AI models. |
| Primary Use | Content generation, simulations, entertainment. | Data preparation for machine learning and computer vision. |
| Technology | GANs, neural networks, deep learning algorithms. | Manual tagging, semi-automated tools, AI-assisted labeling. |
| Output | Fully synthesized video clips or scenes. | Annotated videos with metadata for objects, actions. |
| Automation Level | Highly automated generation. | Partially automated; often requires human validation. |
| Applications | Film production, virtual reality, marketing videos. | Autonomous driving datasets, surveillance, AI training. |
| Challenges | Realism, ethics, high computational cost. | Annotation accuracy, consistency, time-consuming. |
| Key Benefit | Generates new video content quickly and creatively. | Enhances AI model performance through precise data. |
Which is better?
Generative video leverages artificial intelligence to create entirely new video content from text or images, enabling rapid production and creative flexibility. Video annotation focuses on labeling video frames to improve machine learning models for tasks like object recognition and scene understanding, enhancing video analysis accuracy. Choosing between generative video and video annotation depends on whether the goal is content creation or improving video processing algorithms.
Connection
Generative video leverages AI algorithms to create synthetic video content, enabling rapid production of diverse visual data. Video annotation provides critical labeled information that trains these AI models to improve accuracy and realism in generative video outputs. Together, they enhance machine learning capabilities by facilitating the development of advanced applications such as autonomous driving, video surveillance, and content creation.
Key Terms
Labeling (Video annotation)
Video annotation involves the precise labeling of objects, actions, and scenes within video frames, enabling machine learning models to understand and interpret visual data accurately. Key techniques include bounding boxes, segmentation, and keypoint annotation, which enhance training datasets for applications such as autonomous driving and video surveillance. Explore further to discover how expert video annotation can elevate AI model performance.
Synthetic Content (Generative video)
Video annotation involves labeling video data to train machine learning models, enhancing accuracy in object detection and scene understanding. Generative video, a key aspect of synthetic content, uses AI algorithms to create realistic video sequences from scratch or existing footage, enabling applications in entertainment, advertising, and virtual environments. Explore the future of video technology by discovering how generative video is transforming synthetic content creation.
Machine Learning
Video annotation involves labeling video data to train machine learning algorithms for tasks like object recognition and motion tracking, enhancing model accuracy through precise data labeling. Generative video leverages neural networks, such as GANs and diffusion models, to create realistic video content by learning patterns from large datasets, pushing the boundaries of synthetic media creation. Explore the latest advancements in machine learning applications for video annotation and generative video technologies.
Source and External Links
A Short Introduction to Video Annotation for AI - Video annotation involves labeling or masking objects in video footage--either manually or using AI-powered tools--to create datasets for training computer vision models.
The Full Guide to Video Annotation for Computer Vision - Video annotation is the process of adding labels to video data so machine learning models can identify objects, actions, and events, using methods like frame-by-frame or continuous stream annotation depending on the task requirements.
Video Annotation: 5 Uncommon Tips and 7 Top Tools - Video annotation adds metadata, notes, or tags to specific video segments to highlight areas for feedback, research, or machine learning, with various tools available for different annotation needs.