Generative Adversarial Networks (GANs) employ a dual neural network system where a generator creates data samples and a discriminator evaluates their authenticity, excelling in realistic data generation and image synthesis. Stacked Denoising Autoencoders (SDAEs) focus on learning robust feature representations by reconstructing inputs corrupted with noise, enhancing performance in dimensionality reduction and data denoising tasks. Explore more to understand the distinct architectures and applications shaping modern AI advancements.
Why it is important
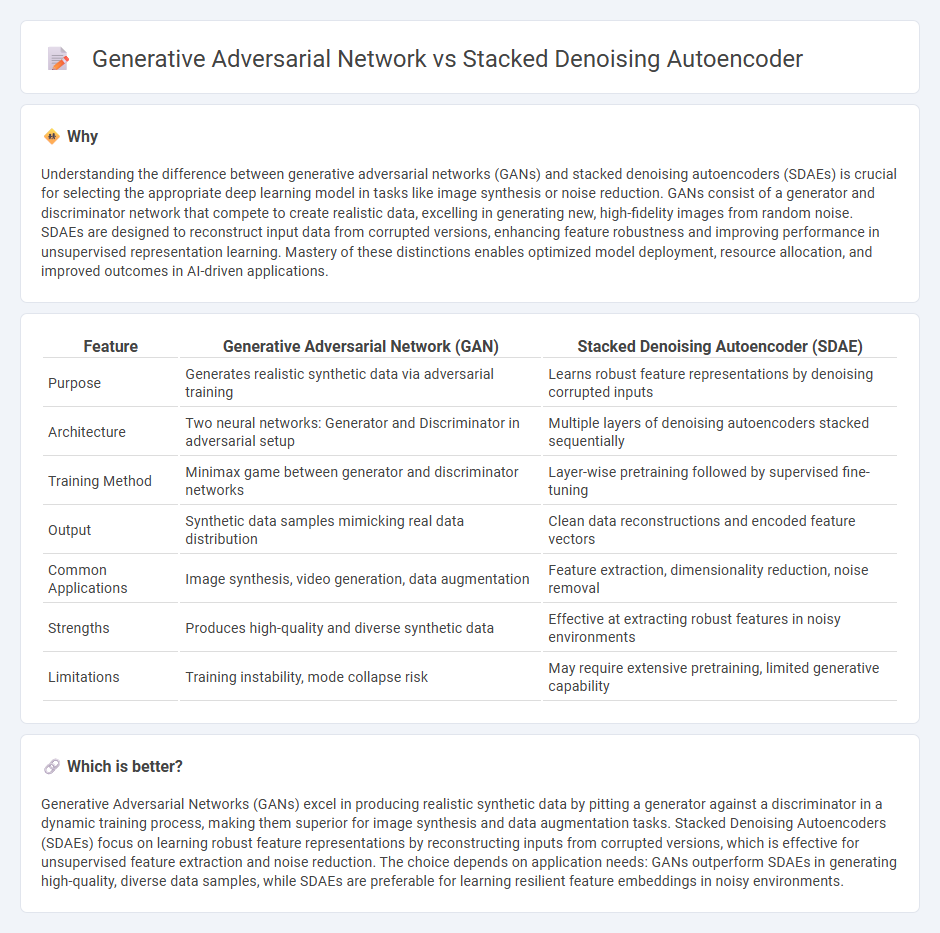
Understanding the difference between generative adversarial networks (GANs) and stacked denoising autoencoders (SDAEs) is crucial for selecting the appropriate deep learning model in tasks like image synthesis or noise reduction. GANs consist of a generator and discriminator network that compete to create realistic data, excelling in generating new, high-fidelity images from random noise. SDAEs are designed to reconstruct input data from corrupted versions, enhancing feature robustness and improving performance in unsupervised representation learning. Mastery of these distinctions enables optimized model deployment, resource allocation, and improved outcomes in AI-driven applications.
Comparison Table
| Feature | Generative Adversarial Network (GAN) | Stacked Denoising Autoencoder (SDAE) |
|---|---|---|
| Purpose | Generates realistic synthetic data via adversarial training | Learns robust feature representations by denoising corrupted inputs |
| Architecture | Two neural networks: Generator and Discriminator in adversarial setup | Multiple layers of denoising autoencoders stacked sequentially |
| Training Method | Minimax game between generator and discriminator networks | Layer-wise pretraining followed by supervised fine-tuning |
| Output | Synthetic data samples mimicking real data distribution | Clean data reconstructions and encoded feature vectors |
| Common Applications | Image synthesis, video generation, data augmentation | Feature extraction, dimensionality reduction, noise removal |
| Strengths | Produces high-quality and diverse synthetic data | Effective at extracting robust features in noisy environments |
| Limitations | Training instability, mode collapse risk | May require extensive pretraining, limited generative capability |
Which is better?
Generative Adversarial Networks (GANs) excel in producing realistic synthetic data by pitting a generator against a discriminator in a dynamic training process, making them superior for image synthesis and data augmentation tasks. Stacked Denoising Autoencoders (SDAEs) focus on learning robust feature representations by reconstructing inputs from corrupted versions, which is effective for unsupervised feature extraction and noise reduction. The choice depends on application needs: GANs outperform SDAEs in generating high-quality, diverse data samples, while SDAEs are preferable for learning resilient feature embeddings in noisy environments.
Connection
Generative Adversarial Networks (GANs) and Stacked Denoising Autoencoders (SDAEs) both leverage unsupervised learning to enhance data representation and feature extraction in deep learning models. GANs consist of a generator and discriminator working adversarially to produce realistic synthetic data, while SDAEs systematically corrupt and reconstruct inputs to learn robust feature embeddings. Their connection lies in utilizing neural networks to improve data quality, with SDAEs often serving as pretraining models that can enhance GAN performance by initializing more effective feature representations.
Key Terms
Feature Extraction
Stacked denoising autoencoders (SDAEs) specialize in extracting robust feature representations by learning to reconstruct input data corrupted by noise, enhancing the resilience and generalization of deep neural networks. In contrast, generative adversarial networks (GANs) focus on generating realistic data samples through a competitive process between generator and discriminator models, indirectly learning feature representations useful for synthetic data creation. Explore further to understand how these architectures uniquely contribute to feature extraction in various machine learning tasks.
Reconstruction Loss
Stacked denoising autoencoders minimize reconstruction loss by learning to recover original inputs from corrupted data, enhancing feature extraction and robustness. Generative adversarial networks primarily optimize adversarial loss, but reconstruction loss can be integrated in variants like BiGANs to improve data fidelity. Explore further to understand their comparative trade-offs in reconstruction quality and generative modeling.
Adversarial Training
Stacked Denoising Autoencoders (SDAEs) utilize hierarchical layers to learn robust feature representations by reconstructing corrupted input data, whereas Generative Adversarial Networks (GANs) employ adversarial training between a generator and discriminator to produce realistic synthetic data. The core of adversarial training in GANs involves a min-max game that enhances the generator's ability to create data indistinguishable from real samples, a concept absent in the reconstruction-focused SDAE framework. Explore further to understand the nuances of adversarial mechanisms and their impact on deep learning models.
Source and External Links
Stacked Denoising Autoencoders - A deep learning method that stacks layers of denoising autoencoders trained to remove noise from corrupted inputs, leading to improved classification performance and learning useful hierarchical features in an unsupervised manner.
Stacked Denoising Autoencoders (PDF) - Detailed research paper explaining how stacking denoising autoencoders improves deep network training by locally denoising corrupted inputs, bridging gaps with deep belief networks and enhancing feature learning.
Stacked Denoising Autoencoders - Practical tutorial describing how stacked denoising autoencoders (SdA) function through layer-wise pretraining and fine-tuning to achieve hierarchical feature extraction and better accuracy in various data analyses.