Differential privacy implements mathematical algorithms to protect individual data points by adding controlled noise, ensuring robust privacy guarantees in data analysis. Synthetic data generation creates artificial datasets that replicate the statistical properties of original data without exposing sensitive information, enabling secure data sharing and modeling. Explore further to understand the distinct applications and benefits of these cutting-edge privacy-preserving technologies.
Why it is important
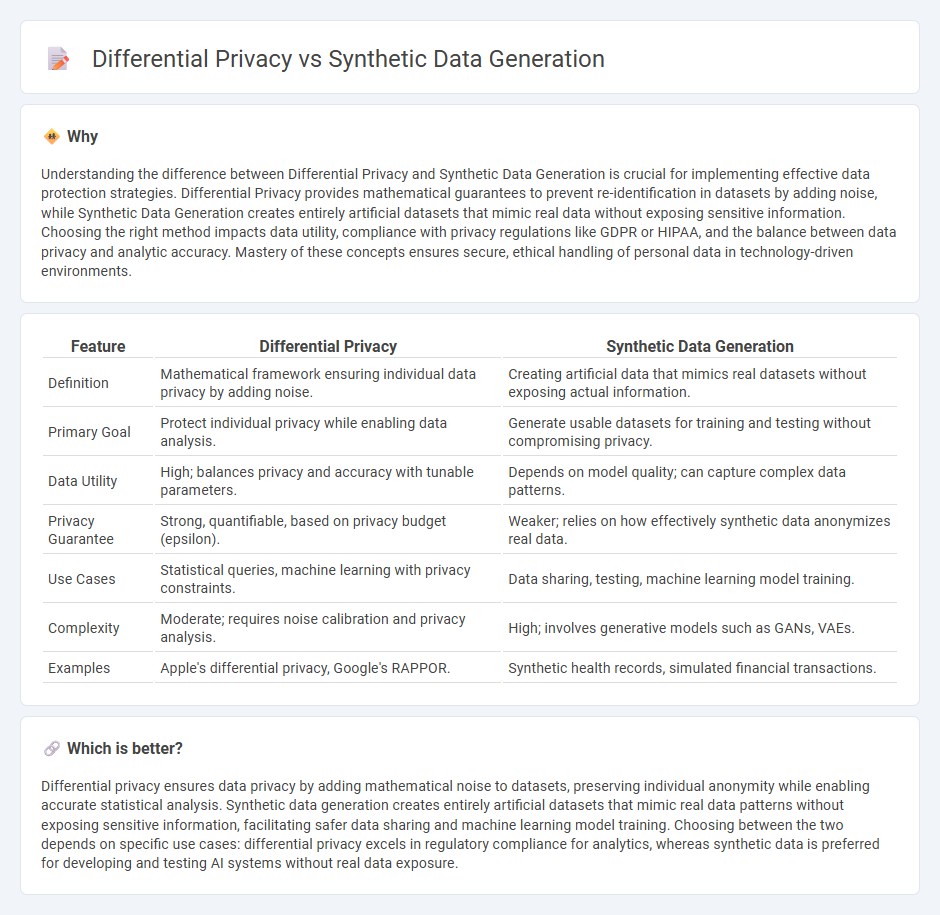
Understanding the difference between Differential Privacy and Synthetic Data Generation is crucial for implementing effective data protection strategies. Differential Privacy provides mathematical guarantees to prevent re-identification in datasets by adding noise, while Synthetic Data Generation creates entirely artificial datasets that mimic real data without exposing sensitive information. Choosing the right method impacts data utility, compliance with privacy regulations like GDPR or HIPAA, and the balance between data privacy and analytic accuracy. Mastery of these concepts ensures secure, ethical handling of personal data in technology-driven environments.
Comparison Table
| Feature | Differential Privacy | Synthetic Data Generation |
|---|---|---|
| Definition | Mathematical framework ensuring individual data privacy by adding noise. | Creating artificial data that mimics real datasets without exposing actual information. |
| Primary Goal | Protect individual privacy while enabling data analysis. | Generate usable datasets for training and testing without compromising privacy. |
| Data Utility | High; balances privacy and accuracy with tunable parameters. | Depends on model quality; can capture complex data patterns. |
| Privacy Guarantee | Strong, quantifiable, based on privacy budget (epsilon). | Weaker; relies on how effectively synthetic data anonymizes real data. |
| Use Cases | Statistical queries, machine learning with privacy constraints. | Data sharing, testing, machine learning model training. |
| Complexity | Moderate; requires noise calibration and privacy analysis. | High; involves generative models such as GANs, VAEs. |
| Examples | Apple's differential privacy, Google's RAPPOR. | Synthetic health records, simulated financial transactions. |
Which is better?
Differential privacy ensures data privacy by adding mathematical noise to datasets, preserving individual anonymity while enabling accurate statistical analysis. Synthetic data generation creates entirely artificial datasets that mimic real data patterns without exposing sensitive information, facilitating safer data sharing and machine learning model training. Choosing between the two depends on specific use cases: differential privacy excels in regulatory compliance for analytics, whereas synthetic data is preferred for developing and testing AI systems without real data exposure.
Connection
Differential privacy is a mathematical framework that ensures individual data privacy by injecting controlled noise into datasets, preventing the re-identification of personal information. Synthetic data generation leverages differential privacy techniques to create artificial datasets that maintain statistical validity while protecting sensitive information. This connection enables organizations to share and analyze data securely without compromising user privacy or data confidentiality.
Key Terms
Data Anonymization
Synthetic data generation creates artificial datasets that mimic real data characteristics without exposing personal information, enhancing data anonymization effectiveness. Differential privacy applies mathematical noise to datasets, guaranteeing that individual entries cannot be re-identified, thus protecting privacy while preserving data utility. Explore more to understand how these techniques revolutionize data anonymization strategies.
Noise Injection
Noise injection in synthetic data generation involves adding random fluctuations to data points to create new, privacy-preserving datasets that retain statistical properties. Differential privacy employs calibrated noise to queries or data outputs, ensuring individual data contributions are mathematically indistinguishable to protect personal information. Explore how these noise injection techniques impact data utility and privacy guarantees in modern data security frameworks.
Model Utility
Synthetic data generation creates artificial datasets that mimic real data distributions to maintain model utility while protecting sensitive information. Differential privacy injects calibrated noise into data or queries, balancing privacy protection with a measurable impact on model accuracy. Explore how these approaches impact machine learning outcomes and privacy preservation in greater detail.
Source and External Links
What is Synthetic Data Generation? A Practical Guide - Synthetic data generation creates artificial data that mimics the statistical patterns and properties of real-world data using algorithms, models, and techniques like generative AI, rules engines, entity cloning, and data masking, ensuring privacy and enabling analysis without real sensitive information.
Synthetic Data Generation - Synthetic data generation produces artificial datasets that replicate real-world data characteristics, addressing issues of scarcity, privacy, and cost through methods like statistical modeling, rule-based generation, data augmentation, and generative models.
What is Synthetic Data Generation (SDG)? | NVIDIA Glossary - Synthetic data generation involves creating text, images, or videos using computer simulations or generative AI to provide diverse, labeled datasets for training AI models when real data is limited, sensitive, or hard to collect.