Generative audio leverages deep learning models to create entirely new soundscapes and music from scratch, offering dynamic, customizable audio experiences. In contrast, speech synthesis focuses on converting text into human-like speech by mimicking natural intonation and rhythm. Explore how these technologies revolutionize audio production and communication.
Why it is important
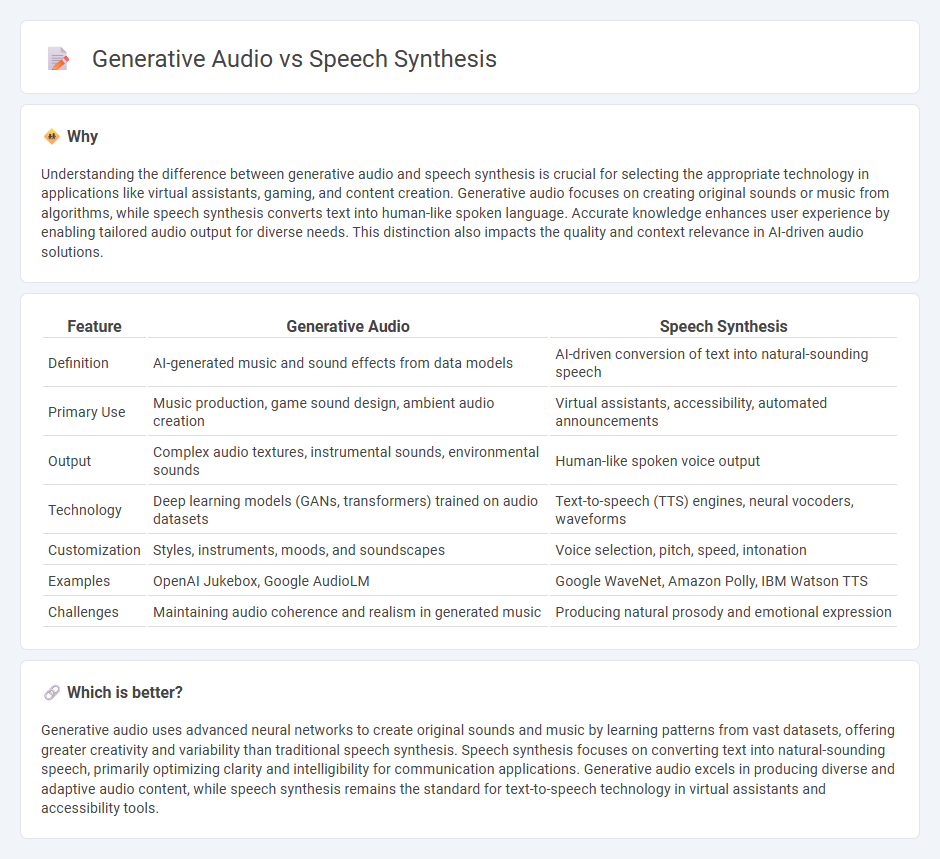
Understanding the difference between generative audio and speech synthesis is crucial for selecting the appropriate technology in applications like virtual assistants, gaming, and content creation. Generative audio focuses on creating original sounds or music from algorithms, while speech synthesis converts text into human-like spoken language. Accurate knowledge enhances user experience by enabling tailored audio output for diverse needs. This distinction also impacts the quality and context relevance in AI-driven audio solutions.
Comparison Table
| Feature | Generative Audio | Speech Synthesis |
|---|---|---|
| Definition | AI-generated music and sound effects from data models | AI-driven conversion of text into natural-sounding speech |
| Primary Use | Music production, game sound design, ambient audio creation | Virtual assistants, accessibility, automated announcements |
| Output | Complex audio textures, instrumental sounds, environmental sounds | Human-like spoken voice output |
| Technology | Deep learning models (GANs, transformers) trained on audio datasets | Text-to-speech (TTS) engines, neural vocoders, waveforms |
| Customization | Styles, instruments, moods, and soundscapes | Voice selection, pitch, speed, intonation |
| Examples | OpenAI Jukebox, Google AudioLM | Google WaveNet, Amazon Polly, IBM Watson TTS |
| Challenges | Maintaining audio coherence and realism in generated music | Producing natural prosody and emotional expression |
Which is better?
Generative audio uses advanced neural networks to create original sounds and music by learning patterns from vast datasets, offering greater creativity and variability than traditional speech synthesis. Speech synthesis focuses on converting text into natural-sounding speech, primarily optimizing clarity and intelligibility for communication applications. Generative audio excels in producing diverse and adaptive audio content, while speech synthesis remains the standard for text-to-speech technology in virtual assistants and accessibility tools.
Connection
Generative audio and speech synthesis are interconnected through the use of deep learning models that create realistic sound patterns and human-like speech from textual or acoustic inputs. These technologies employ neural networks such as WaveNet and Tacotron to generate natural-sounding voice outputs and dynamic audio textures. Advances in generative adversarial networks (GANs) further enhance speech synthesis quality by improving prosody, intonation, and expressiveness in synthesized audio.
Key Terms
Text-to-Speech (TTS)
Text-to-Speech (TTS) leverages speech synthesis technology to convert written text into natural-sounding spoken words, primarily using deep learning models like Tacotron and WaveNet for enhanced voice quality. Generative audio encompasses a broader domain, including not only TTS but also music generation and sound effects, utilizing neural networks such as GANs or autoencoders to create novel audio content from scratch. Explore the latest advancements in TTS and generative audio to understand their unique capabilities and applications.
Neural Audio Generation
Neural Audio Generation leverages deep learning models to create highly natural and expressive speech, surpassing traditional speech synthesis techniques focused primarily on replicating human voice patterns. Generative audio extends beyond speech to produce diverse sounds, including music and environmental noise, by modeling complex audio features through neural networks. Explore cutting-edge advancements in neural audio generation to understand its transformative impact on audio technology.
Waveform Modeling
Speech synthesis primarily involves creating human-like speech from text using models like Tacotron or WaveNet, emphasizing natural intonation and clarity. Generative audio through waveform modeling extends beyond speech by generating complex soundscapes, music, or environmental sounds with advanced techniques such as GANs or neural vocoders. Explore cutting-edge advancements in waveform modeling to understand the full potential and applications of generative audio technologies.
Source and External Links
Speech synthesis - Wikipedia - Speech synthesis is the artificial production of human speech, using techniques such as concatenative synthesis and formant synthesis, with the key goals being naturalness and intelligibility in the generated speech output.
How to synthesize speech from text - Azure AI services - This guide explains how to use Azure's SpeechSynthesizer object to convert text into speech audio files in formats like WAV, including code examples and customization options.
How speech synthesis works - Explain that Stuff - Speech synthesis transforms text into spoken words by converting text to phonemes and then to sound, handling complex language features like homographs through contextual analysis.