Synthetic data is artificially generated using algorithms and simulations to replicate the statistical properties of real-world data, while collected data is obtained directly from actual user interactions, sensors, or surveys. Synthetic data offers advantages in privacy preservation and scalability, whereas collected data provides authentic and nuanced insights but may involve privacy risks and data acquisition challenges. Explore how businesses leverage synthetic and collected data to enhance machine learning models and decision-making processes.
Why it is important
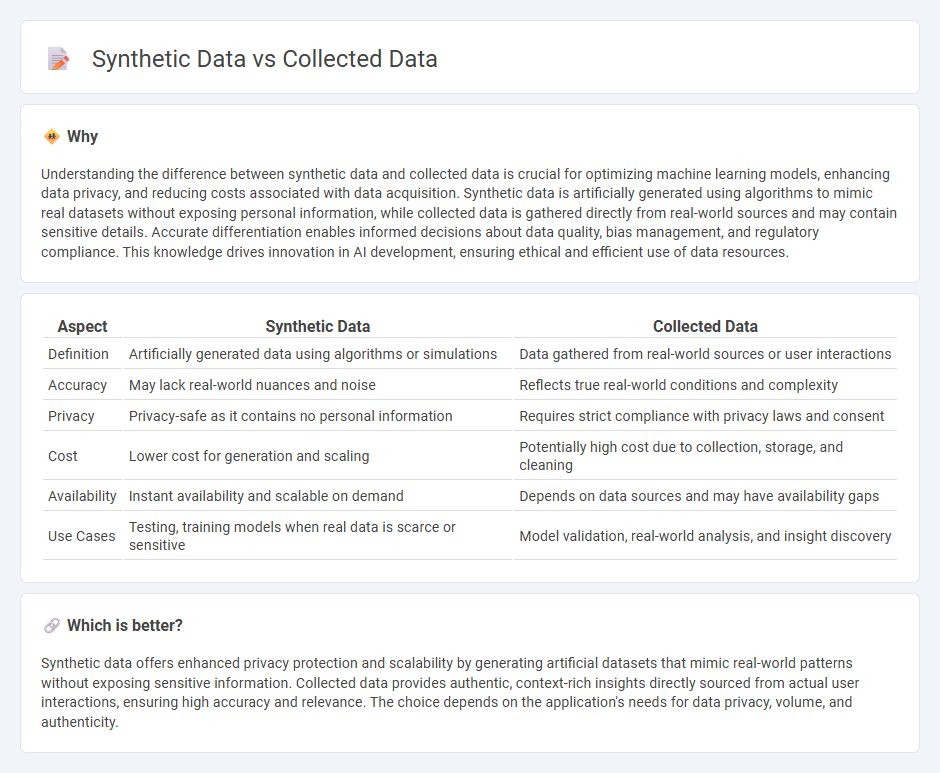
Understanding the difference between synthetic data and collected data is crucial for optimizing machine learning models, enhancing data privacy, and reducing costs associated with data acquisition. Synthetic data is artificially generated using algorithms to mimic real datasets without exposing personal information, while collected data is gathered directly from real-world sources and may contain sensitive details. Accurate differentiation enables informed decisions about data quality, bias management, and regulatory compliance. This knowledge drives innovation in AI development, ensuring ethical and efficient use of data resources.
Comparison Table
| Aspect | Synthetic Data | Collected Data |
|---|---|---|
| Definition | Artificially generated data using algorithms or simulations | Data gathered from real-world sources or user interactions |
| Accuracy | May lack real-world nuances and noise | Reflects true real-world conditions and complexity |
| Privacy | Privacy-safe as it contains no personal information | Requires strict compliance with privacy laws and consent |
| Cost | Lower cost for generation and scaling | Potentially high cost due to collection, storage, and cleaning |
| Availability | Instant availability and scalable on demand | Depends on data sources and may have availability gaps |
| Use Cases | Testing, training models when real data is scarce or sensitive | Model validation, real-world analysis, and insight discovery |
Which is better?
Synthetic data offers enhanced privacy protection and scalability by generating artificial datasets that mimic real-world patterns without exposing sensitive information. Collected data provides authentic, context-rich insights directly sourced from actual user interactions, ensuring high accuracy and relevance. The choice depends on the application's needs for data privacy, volume, and authenticity.
Connection
Synthetic data complements collected data by enhancing machine learning models when real datasets are limited or imbalanced, thus improving algorithm accuracy and robustness. The integration of synthetic data allows for extensive testing and validation without compromising privacy or security, which is crucial for sectors like healthcare and finance. Combining these data types creates a richer dataset, enabling more effective training and better performance in AI-driven technologies.
Key Terms
Data Sources
Collected data originates from real-world environments through sensors, surveys, or user interactions, providing authentic and context-rich information critical for accurate model training. Synthetic data is generated algorithmically or via simulations, offering scalable, customizable datasets that address privacy concerns and augment scarce or imbalanced real datasets. Explore comprehensive insights on data sources and their impactful roles in AI development.
Realism
Collected data offers unmatched realism by capturing authentic, real-world scenarios, reflecting actual user behaviors and environmental nuances. Synthetic data, while generated artificially, can be engineered to approximate real conditions but may lack the intricate variability found in genuine datasets. Explore how blending both data types can enhance model accuracy and robustness.
Bias
Collected data often contains inherent biases due to sampling methods, historical inequalities, or human errors, which can skew machine learning outcomes. Synthetic data is generated through algorithms designed to minimize these biases by creating balanced, diverse datasets that better represent underrepresented groups. Discover how leveraging synthetic data can improve fairness and accuracy in AI models.
Source and External Links
What Is Data Collection: Methods, Types, Tools - Simplilearn.com - Data collection is the process of gathering, measuring, and analyzing accurate data using primary methods such as surveys, interviews, observations, experiments, and focus groups directly from sources.
Data collection - Wikipedia - Data collection involves systematically gathering and measuring information on targeted variables to answer questions and evaluate outcomes across all study fields, emphasizing accuracy and integrity in the process.
What is data collection? - RudderStack - Data collection is the process of gathering qualitative or quantitative information from primary sources like surveys and interviews or secondary sources such as databases, with method choice depending on data type and resource availability.