Self-supervised learning leverages large amounts of unlabeled data to generate useful representations by predicting parts of the input, enhancing model performance without extensive labeled datasets. Few-shot learning focuses on enabling models to generalize from a limited number of labeled examples, often through meta-learning techniques or transfer learning. Explore the nuances and applications of these innovative machine learning approaches to understand their distinct advantages and challenges.
Why it is important
Understanding the difference between self-supervised learning and few-shot learning is crucial in technology because it enables more efficient model training and deployment. Self-supervised learning leverages vast unlabeled data to pre-train models, reducing the need for manual annotation. Few-shot learning focuses on adapting models to new tasks with very limited labeled examples, enhancing flexibility in real-world applications. Mastering these techniques drives innovation in AI by optimizing resource use and improving model performance across diverse scenarios.
Comparison Table
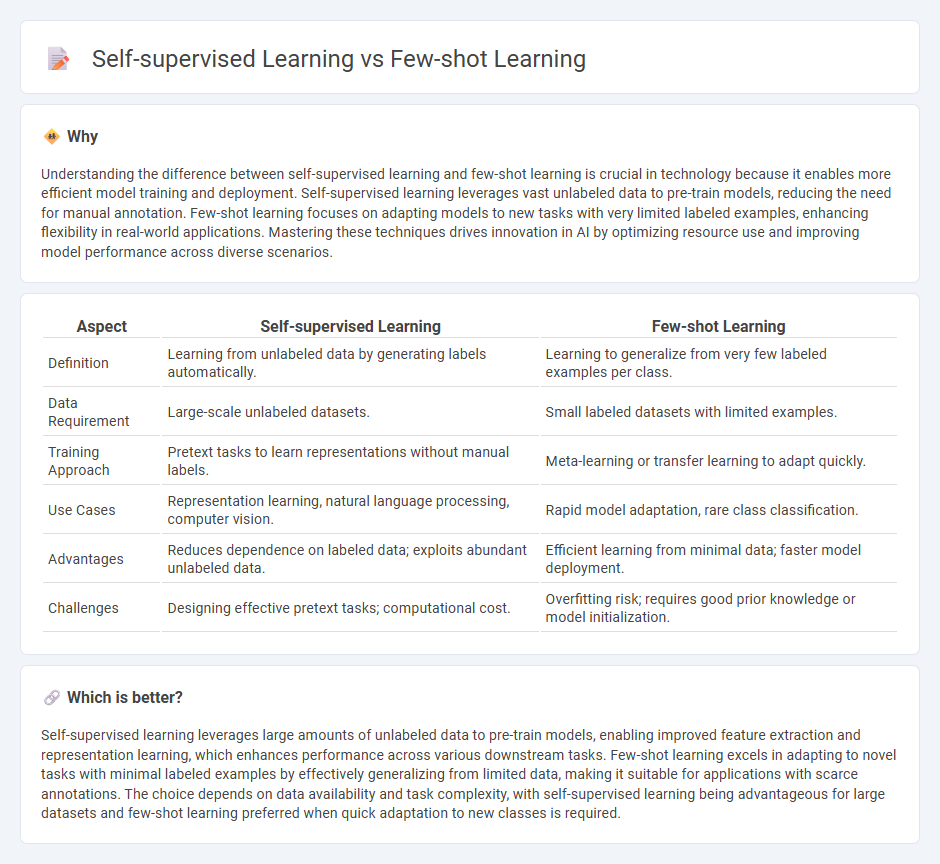
| Aspect | Self-supervised Learning | Few-shot Learning |
|---|---|---|
| Definition | Learning from unlabeled data by generating labels automatically. | Learning to generalize from very few labeled examples per class. |
| Data Requirement | Large-scale unlabeled datasets. | Small labeled datasets with limited examples. |
| Training Approach | Pretext tasks to learn representations without manual labels. | Meta-learning or transfer learning to adapt quickly. |
| Use Cases | Representation learning, natural language processing, computer vision. | Rapid model adaptation, rare class classification. |
| Advantages | Reduces dependence on labeled data; exploits abundant unlabeled data. | Efficient learning from minimal data; faster model deployment. |
| Challenges | Designing effective pretext tasks; computational cost. | Overfitting risk; requires good prior knowledge or model initialization. |
Which is better?
Self-supervised learning leverages large amounts of unlabeled data to pre-train models, enabling improved feature extraction and representation learning, which enhances performance across various downstream tasks. Few-shot learning excels in adapting to novel tasks with minimal labeled examples by effectively generalizing from limited data, making it suitable for applications with scarce annotations. The choice depends on data availability and task complexity, with self-supervised learning being advantageous for large datasets and few-shot learning preferred when quick adaptation to new classes is required.
Connection
Self-supervised learning enables models to generate meaningful representations from unlabeled data, which significantly improves performance in few-shot learning scenarios where labeled examples are scarce. By extracting rich feature embeddings through pretraining on large datasets without labels, self-supervised learning frameworks provide a strong initialization that allows few-shot learners to adapt quickly with minimal annotated samples. This synergy accelerates advancements in natural language processing, computer vision, and speech recognition by reducing dependency on extensive labeled datasets.
Key Terms
Task Adaptation
Few-shot learning emphasizes rapid task adaptation by leveraging limited labeled examples to generalize effectively to new tasks. Self-supervised learning exploits large volumes of unlabeled data to pretrain models, enabling improved feature representations that facilitate downstream task adaptation with minimal supervision. Explore deeper insights on how these paradigms enhance task adaptability in modern machine learning.
Representation Learning
Few-shot learning leverages limited labeled examples to rapidly adapt models by optimizing feature representations for new tasks with minimal data. Self-supervised learning harnesses vast amounts of unlabeled data to pretrain models, learning robust and generalizable representations through surrogate tasks like contrastive learning or masked prediction. Explore how these approaches advance representation learning for improved model generalization and efficiency.
Source and External Links
What is Few-Shot Learning? Unlocking Insights with Limited Data - Few-shot learning enables models to recognize patterns and make accurate predictions with only a small number of labeled examples, adapting quickly to new tasks by leveraging prior knowledge and similarity functions.
Everything you need to know about Few-Shot Learning - Few-shot learning is a machine learning framework that allows pre-trained models to generalize across new categories using only a few labeled examples, reducing the need for large datasets and extensive retraining.
A Summary of Approaches to Few-Shot Learning - Few-shot learning addresses the challenge of learning patterns from minimal training samples, offering solutions that combine meta-learning, transfer learning, and hybrid approaches to overcome data scarcity.