Tiny machine learning (TinyML) focuses on deploying machine learning models on edge devices with limited resources, enabling real-time data processing without internet dependency. In contrast, machine learning model compression reduces model size and computational requirements to improve deployment efficiency across various platforms. Explore how these advancements transform AI capabilities in resource-constrained environments.
Why it is important
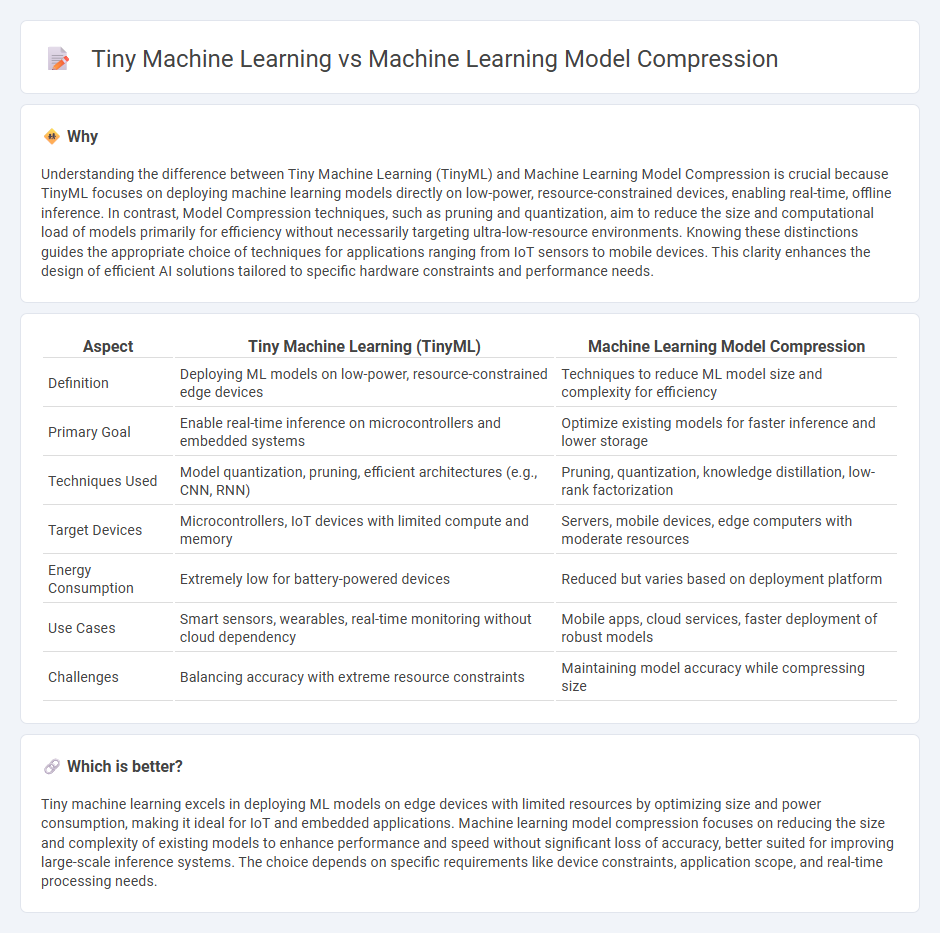
Understanding the difference between Tiny Machine Learning (TinyML) and Machine Learning Model Compression is crucial because TinyML focuses on deploying machine learning models directly on low-power, resource-constrained devices, enabling real-time, offline inference. In contrast, Model Compression techniques, such as pruning and quantization, aim to reduce the size and computational load of models primarily for efficiency without necessarily targeting ultra-low-resource environments. Knowing these distinctions guides the appropriate choice of techniques for applications ranging from IoT sensors to mobile devices. This clarity enhances the design of efficient AI solutions tailored to specific hardware constraints and performance needs.
Comparison Table
| Aspect | Tiny Machine Learning (TinyML) | Machine Learning Model Compression |
|---|---|---|
| Definition | Deploying ML models on low-power, resource-constrained edge devices | Techniques to reduce ML model size and complexity for efficiency |
| Primary Goal | Enable real-time inference on microcontrollers and embedded systems | Optimize existing models for faster inference and lower storage |
| Techniques Used | Model quantization, pruning, efficient architectures (e.g., CNN, RNN) | Pruning, quantization, knowledge distillation, low-rank factorization |
| Target Devices | Microcontrollers, IoT devices with limited compute and memory | Servers, mobile devices, edge computers with moderate resources |
| Energy Consumption | Extremely low for battery-powered devices | Reduced but varies based on deployment platform |
| Use Cases | Smart sensors, wearables, real-time monitoring without cloud dependency | Mobile apps, cloud services, faster deployment of robust models |
| Challenges | Balancing accuracy with extreme resource constraints | Maintaining model accuracy while compressing size |
Which is better?
Tiny machine learning excels in deploying ML models on edge devices with limited resources by optimizing size and power consumption, making it ideal for IoT and embedded applications. Machine learning model compression focuses on reducing the size and complexity of existing models to enhance performance and speed without significant loss of accuracy, better suited for improving large-scale inference systems. The choice depends on specific requirements like device constraints, application scope, and real-time processing needs.
Connection
Tiny machine learning enables deployment of machine learning models on resource-constrained devices by significantly reducing model size and computational requirements, a process achieved through machine learning model compression techniques such as quantization, pruning, and knowledge distillation. Model compression optimizes memory usage and energy efficiency, making complex neural networks accessible for edge computing applications including IoT sensors and wearable devices. This synergy enhances real-time data processing capabilities while maintaining predictive accuracy within the limited hardware environments of embedded systems.
Key Terms
Quantization
Quantization is a key technique in both machine learning model compression and Tiny Machine Learning (TinyML), significantly reducing model size and computational requirements by converting high-precision weights into lower-precision formats such as INT8 or FLOAT16. While model compression broadly includes pruning, knowledge distillation, and quantization to optimize large-scale ML models for deployment, TinyML specifically leverages quantization to enable AI inference on ultra-low-power devices with limited resources. Explore more about how quantization drives efficiency in embedded AI systems and its impact on edge computing applications.
Pruning
Pruning is a key technique in both machine learning model compression and Tiny Machine Learning (TinyML) that reduces model size by eliminating redundant or less important parameters, enhancing computational efficiency without significant loss of accuracy. In model compression, pruning focuses on optimizing large-scale neural networks for deployment on traditional hardware, while TinyML leverages pruning to enable ultra-low-power inference on resource-constrained edge devices like microcontrollers. Explore more to understand how pruning strategies vary between these domains and drive advancements in efficient AI deployment.
Edge Deployment
Model compression techniques reduce the size and complexity of machine learning models by pruning, quantization, and knowledge distillation, making them suitable for edge deployment with limited resources. Tiny Machine Learning (TinyML) specifically targets ultra-low-power devices by designing and optimizing models for microcontrollers and edge hardware, enabling real-time inference with minimal latency and energy consumption. Explore our detailed guide to understand the best practices and tools for deploying efficient AI on edge devices.
Source and External Links
Model compression - Wikipedia - Model compression is a machine learning technique for reducing the size of trained models, enabling efficient deployment on resource-constrained devices while aiming to preserve high accuracy.
4 Popular Model Compression Techniques Explained - Xailient - Model compression reduces neural network size without significantly compromising accuracy, using techniques like pruning (removing redundant parameters), quantization (reducing numerical precision), knowledge distillation (training smaller models to mimic larger ones), and low-rank factorization (decomposing weight matrices).
Model Compression: A Survey of Techniques, Tools, and Libraries - Model compression algorithms aim to reduce the size and memory requirements of neural networks, making them more efficient and cost-effective for deployment across environments like edge devices and cloud services.