Synthetic data accelerates machine learning development by providing artificially generated datasets that mimic real-world scenarios without privacy concerns. Labeled data, on the other hand, consists of manually annotated samples essential for supervised learning accuracy but is often expensive and time-consuming to produce. Explore how balancing synthetic and labeled data can optimize AI training and performance.
Why it is important
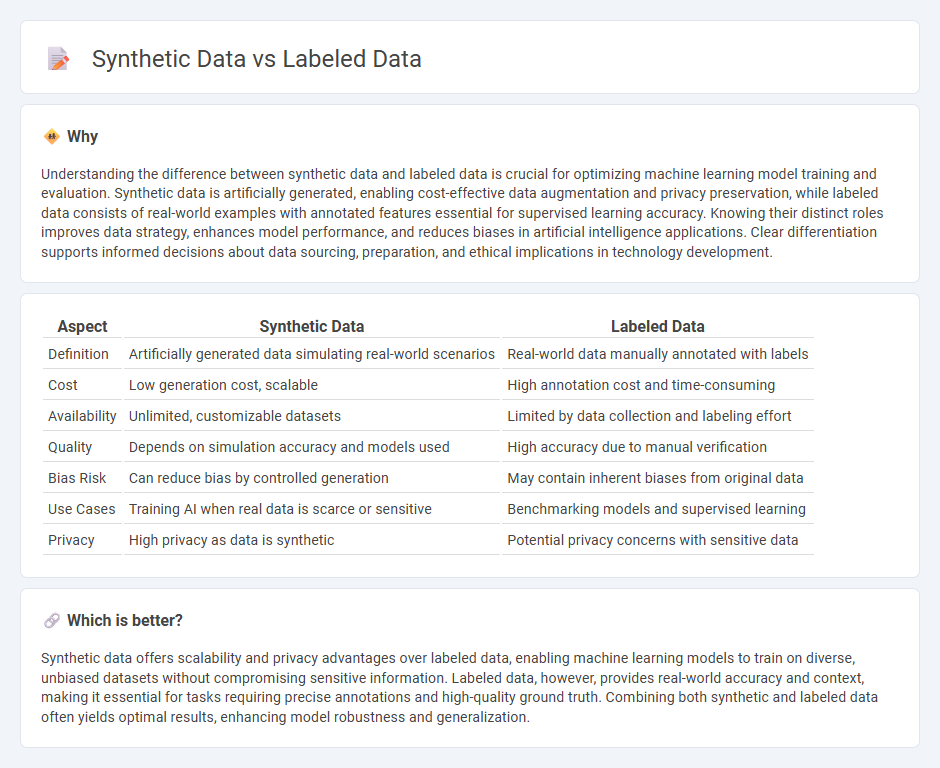
Understanding the difference between synthetic data and labeled data is crucial for optimizing machine learning model training and evaluation. Synthetic data is artificially generated, enabling cost-effective data augmentation and privacy preservation, while labeled data consists of real-world examples with annotated features essential for supervised learning accuracy. Knowing their distinct roles improves data strategy, enhances model performance, and reduces biases in artificial intelligence applications. Clear differentiation supports informed decisions about data sourcing, preparation, and ethical implications in technology development.
Comparison Table
| Aspect | Synthetic Data | Labeled Data |
|---|---|---|
| Definition | Artificially generated data simulating real-world scenarios | Real-world data manually annotated with labels |
| Cost | Low generation cost, scalable | High annotation cost and time-consuming |
| Availability | Unlimited, customizable datasets | Limited by data collection and labeling effort |
| Quality | Depends on simulation accuracy and models used | High accuracy due to manual verification |
| Bias Risk | Can reduce bias by controlled generation | May contain inherent biases from original data |
| Use Cases | Training AI when real data is scarce or sensitive | Benchmarking models and supervised learning |
| Privacy | High privacy as data is synthetic | Potential privacy concerns with sensitive data |
Which is better?
Synthetic data offers scalability and privacy advantages over labeled data, enabling machine learning models to train on diverse, unbiased datasets without compromising sensitive information. Labeled data, however, provides real-world accuracy and context, making it essential for tasks requiring precise annotations and high-quality ground truth. Combining both synthetic and labeled data often yields optimal results, enhancing model robustness and generalization.
Connection
Synthetic data and labeled data are interconnected as synthetic data generation techniques produce artificially created datasets complete with precise labels, enhancing the availability of high-quality labeled data for training machine learning models. This connection addresses challenges in data scarcity and privacy concerns by providing diverse, annotated datasets that replicate real-world scenarios. Leveraging synthetic data accelerates model development and improves performance in applications like computer vision, natural language processing, and autonomous systems.
Key Terms
Annotation
Annotation accuracy is crucial in labeled data, as human annotators provide precise, context-aware labels ensuring high-quality training sets for machine learning models. Synthetic data often relies on automated labeling during generation, which can introduce biases or errors if the simulation or algorithm lacks real-world complexity. Explore in-depth comparisons of annotation methods to understand their impact on model performance and data reliability.
Data Generation
Labeled data consists of real-world datasets annotated with human-verified tags, which ensures high accuracy but requires significant time and resources to collect. Synthetic data is artificially generated using algorithms or simulations, enabling rapid scalability and diversity while reducing costs and privacy concerns. Explore further to understand how these data generation methods impact machine learning model performance and applicability.
Ground Truth
Labeled data consists of real-world examples manually annotated to provide accurate ground truth, essential for training reliable machine learning models. Synthetic data is artificially generated with controlled ground truth, offering scalability and privacy benefits but may lack real-world complexity. Explore the advantages and challenges of both data types to optimize your model's performance.
Source and External Links
What is Labeled Data? - DataCamp - Labeled data is raw data assigned with meaningful labels or tags, used in supervised learning to help machine learning models learn accurate input-output relationships and improve prediction accuracy.
The difference between labeled and unlabeled data - Toloka - Labeled data is annotated with tags by humans to enable supervised learning, making it more valuable but harder and costlier to obtain than abundant unlabeled data.
What is the difference between labeled and unlabeled data? - GeeksforGeeks - Labeled data consists of data points assigned to categories indicating the ground truth used in supervised machine learning tasks such as classification and regression, though acquiring such data demands considerable time and human effort.