Differential privacy and K-anonymity are two prominent techniques used to protect individual privacy in data sharing and analysis. Differential privacy provides mathematical guarantees against identifying individuals by adding controlled noise to datasets, while K-anonymity achieves privacy by generalizing or suppressing data to ensure each person is indistinguishable from at least K-1 others. Explore the detailed differences and applications of these privacy models to enhance your data security understanding.
Why it is important
Understanding the difference between Differential Privacy and K-Anonymity is crucial for selecting the right privacy protection method in data analysis and sharing. Differential Privacy offers a mathematically robust guarantee by adding noise to datasets, minimizing the risk of individual re-identification even against adversaries with auxiliary information. In contrast, K-Anonymity masks individual identities by ensuring each person is indistinguishable within a group of k individuals but is vulnerable to homogeneity and background knowledge attacks. Choosing between these techniques impacts the balance between data utility and privacy risk in sectors like healthcare, finance, and technology innovation.
Comparison Table
| Feature | Differential Privacy | K-Anonymity |
|---|---|---|
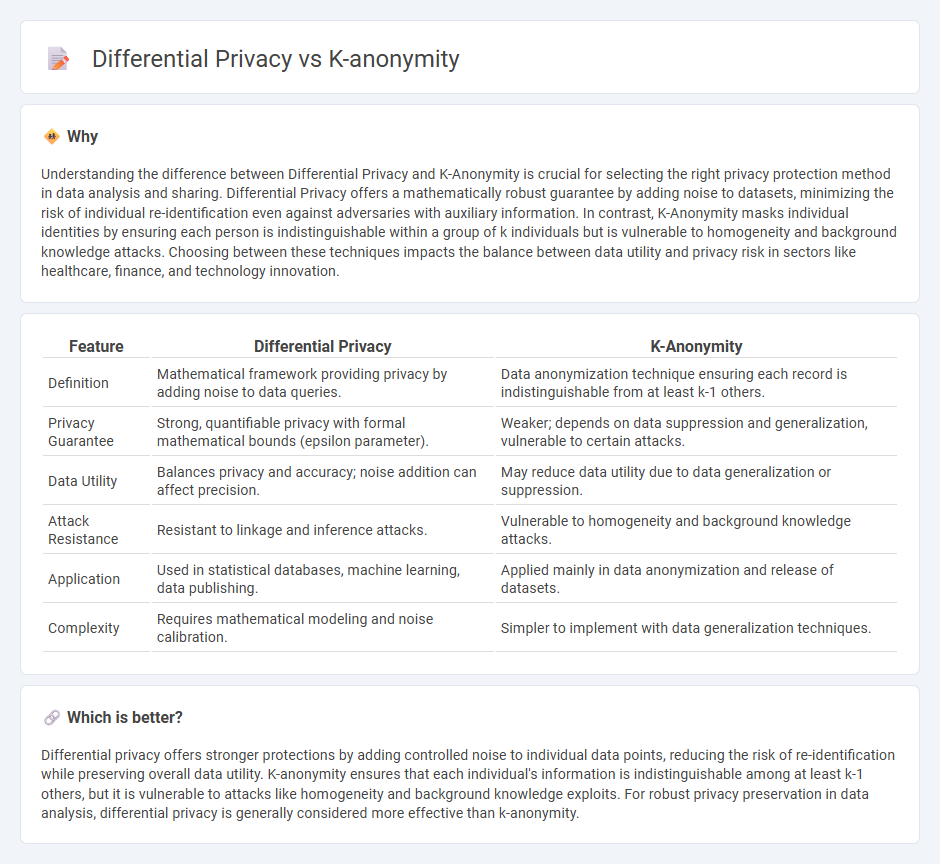
| Definition | Mathematical framework providing privacy by adding noise to data queries. | Data anonymization technique ensuring each record is indistinguishable from at least k-1 others. |
| Privacy Guarantee | Strong, quantifiable privacy with formal mathematical bounds (epsilon parameter). | Weaker; depends on data suppression and generalization, vulnerable to certain attacks. |
| Data Utility | Balances privacy and accuracy; noise addition can affect precision. | May reduce data utility due to data generalization or suppression. |
| Attack Resistance | Resistant to linkage and inference attacks. | Vulnerable to homogeneity and background knowledge attacks. |
| Application | Used in statistical databases, machine learning, data publishing. | Applied mainly in data anonymization and release of datasets. |
| Complexity | Requires mathematical modeling and noise calibration. | Simpler to implement with data generalization techniques. |
Which is better?
Differential privacy offers stronger protections by adding controlled noise to individual data points, reducing the risk of re-identification while preserving overall data utility. K-anonymity ensures that each individual's information is indistinguishable among at least k-1 others, but it is vulnerable to attacks like homogeneity and background knowledge exploits. For robust privacy preservation in data analysis, differential privacy is generally considered more effective than k-anonymity.
Connection
Differential privacy and K-anonymity are connected through their shared goal of protecting individual data privacy in datasets. K-anonymity achieves this by ensuring each record is indistinguishable from at least k-1 others, while differential privacy adds controlled noise to provide quantifiable privacy guarantees. Both techniques are fundamental in data anonymization and privacy-preserving data analysis frameworks.
Key Terms
Quasi-identifiers
K-anonymity protects privacy by ensuring that each individual is indistinguishable from at least k-1 others based on quasi-identifiers like age, ZIP code, and gender, effectively preventing re-identification from these attributes. Differential privacy provides a stronger, mathematically rigorous privacy guarantee by adding calibrated noise to data queries, which limits the impact of any single record's presence on the output, securing sensitive information even when quasi-identifiers are known. Explore detailed comparisons and use cases to understand how these models address privacy risks involving quasi-identifiers.
Noise addition
K-anonymity protects privacy by generalizing or suppressing data to ensure each individual is indistinguishable from at least k-1 others, while differential privacy achieves privacy by adding calibrated noise to the data or queries, effectively masking individual contributions. Noise addition in differential privacy is mathematically designed to provide quantifiable privacy guarantees, unlike the suppression or generalization methods in k-anonymity that may still be vulnerable to background knowledge attacks. Explore more about the mathematical foundations and practical applications of noise addition in differential privacy.
Privacy guarantee
K-anonymity ensures privacy by making each individual's data indistinguishable among at least k-1 others, reducing re-identification risks in datasets. Differential privacy provides a mathematically rigorous privacy guarantee by adding controlled noise to query results, protecting individual data contributions even against attackers with auxiliary knowledge. Explore the nuances of how these models safeguard privacy in various data-sharing scenarios to better understand their strengths and applications.
Source and External Links
Everything You Need to Know About K-Anonymity - K-anonymity is a data privacy technique that pools individuals with similar attributes so no single person can be uniquely identified, protecting against re-identification by ensuring each person's data is indistinguishable from at least k-1 others.
K-anonymity - First formalized in 1998, k-anonymity is a property of anonymized data where each individual's record cannot be distinguished from at least \(k-1\) others in the dataset, aiming to prevent re-identification while keeping the data useful.
What is K Anonymity and Why Data Pros Care - K-anonymity is achieved when, for every combination of identifying attributes in a dataset, there are at least k identical records, ensuring individuals remain unidentifiable within the group.