Vector databases efficiently handle high-dimensional data for AI and machine learning applications, enabling rapid similarity searches and semantic querying. In-memory databases store data entirely in RAM, delivering ultra-fast transaction processing and real-time analytics for enterprise systems. Explore the advantages and use cases of both technologies to optimize your data strategy.
Why it is important
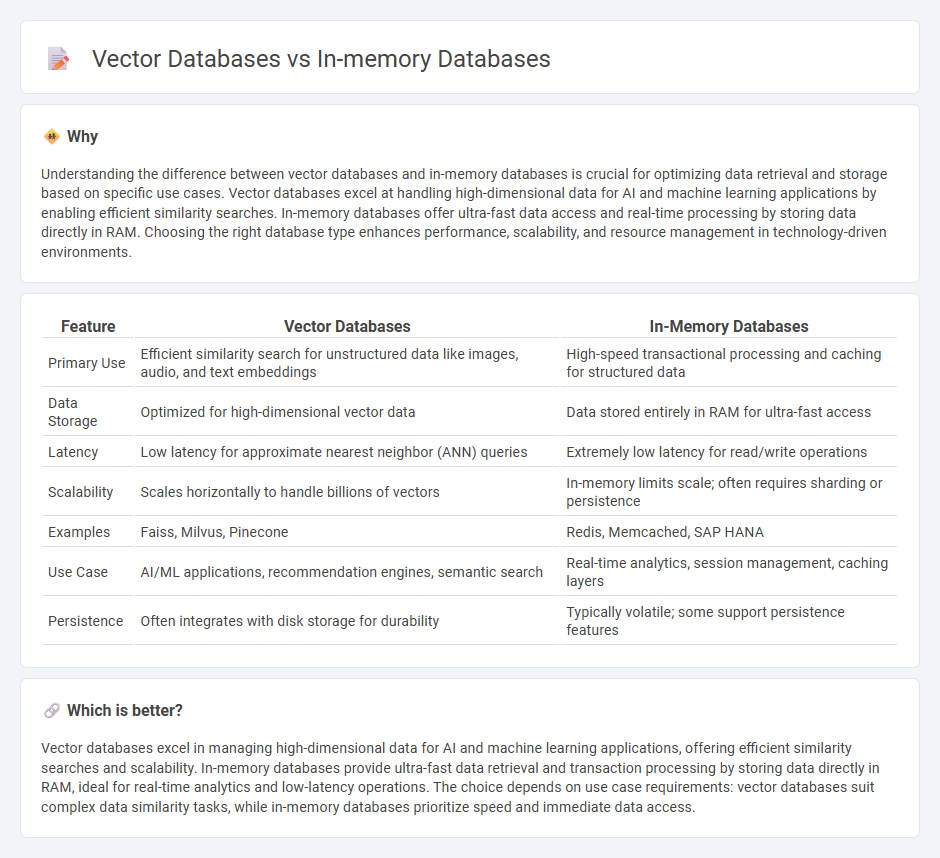
Understanding the difference between vector databases and in-memory databases is crucial for optimizing data retrieval and storage based on specific use cases. Vector databases excel at handling high-dimensional data for AI and machine learning applications by enabling efficient similarity searches. In-memory databases offer ultra-fast data access and real-time processing by storing data directly in RAM. Choosing the right database type enhances performance, scalability, and resource management in technology-driven environments.
Comparison Table
| Feature | Vector Databases | In-Memory Databases |
|---|---|---|
| Primary Use | Efficient similarity search for unstructured data like images, audio, and text embeddings | High-speed transactional processing and caching for structured data |
| Data Storage | Optimized for high-dimensional vector data | Data stored entirely in RAM for ultra-fast access |
| Latency | Low latency for approximate nearest neighbor (ANN) queries | Extremely low latency for read/write operations |
| Scalability | Scales horizontally to handle billions of vectors | In-memory limits scale; often requires sharding or persistence |
| Examples | Faiss, Milvus, Pinecone | Redis, Memcached, SAP HANA |
| Use Case | AI/ML applications, recommendation engines, semantic search | Real-time analytics, session management, caching layers |
| Persistence | Often integrates with disk storage for durability | Typically volatile; some support persistence features |
Which is better?
Vector databases excel in managing high-dimensional data for AI and machine learning applications, offering efficient similarity searches and scalability. In-memory databases provide ultra-fast data retrieval and transaction processing by storing data directly in RAM, ideal for real-time analytics and low-latency operations. The choice depends on use case requirements: vector databases suit complex data similarity tasks, while in-memory databases prioritize speed and immediate data access.
Connection
Vector databases optimize the storage and retrieval of high-dimensional data representations essential for machine learning and AI applications, while in-memory databases facilitate ultra-fast data access by storing data directly in RAM. Their connection lies in enhancing real-time processing capabilities, where vector databases leverage in-memory architectures to accelerate similarity searches and reduce latency. This synergy is crucial for applications like recommendation engines, natural language processing, and image recognition that demand rapid and efficient data handling.
Key Terms
Data Storage Model
In-memory databases store data primarily in the system's RAM, enabling rapid read and write operations suited for transactional and real-time processing workloads. Vector databases, on the other hand, organize data as high-dimensional vectors, optimized for similarity search and machine learning applications, often leveraging specialized indexes like HNSW or PQ. Explore the distinctions in storage architectures to determine the best fit for your data-intensive projects.
Query Processing
In-memory databases leverage RAM to accelerate query processing by minimizing disk I/O, enabling rapid transaction and real-time analytics with low latency. Vector databases optimize query performance by using specialized indexing methods like HNSW or IVFPQ to handle high-dimensional vector similarity searches efficiently. Explore our detailed comparison to understand how these technologies impact your specific data query requirements.
Indexing Mechanism
In-memory databases utilize RAM to store data for rapid access, implementing indexing mechanisms like B-trees or hash indexes to speed up query performance on structured data. Vector databases focus on indexing high-dimensional vectors using specialized structures such as HNSW (Hierarchical Navigable Small World) graphs or IVF (Inverted File) for efficient similarity search in AI and machine learning applications. Explore deeper insights on indexing techniques and use cases in specialized database systems.
Source and External Links
In-memory database - Wikipedia - In-memory databases store data primarily in the main memory of a computer for faster access and lower latency compared to traditional disk-based systems, making them ideal for applications requiring quick responses and real-time analytics.
What Is a In Memory Database? - AWS - In-memory databases rely on internal memory for storage, enabling minimal response times and high throughput, and are especially suited for scenarios like gaming leaderboards, session stores, and real-time analytics where instant data access is critical.
Top 27 In-Memory Databases Compared - Dragonfly - In-memory databases store all data in RAM, allowing for rapid data retrieval and processing, but require techniques such as replication and checkpointing to manage data durability and consistency due to the volatile nature of memory.