Tiny Machine Learning (TinyML) enables the deployment of machine learning models on resource-constrained devices by optimizing for low power and memory usage, while Quantized Neural Networks (QNNs) reduce model size and computational complexity through lower-precision representations of weights and activations. Both TinyML and QNNs address the challenges of running AI on edge devices but differ in their focus: TinyML emphasizes system-level optimization and energy efficiency, whereas QNNs primarily target model compression and inference speed. Explore the distinctions and applications of TinyML and Quantized Neural Networks to understand their impact on edge computing innovation.
Why it is important
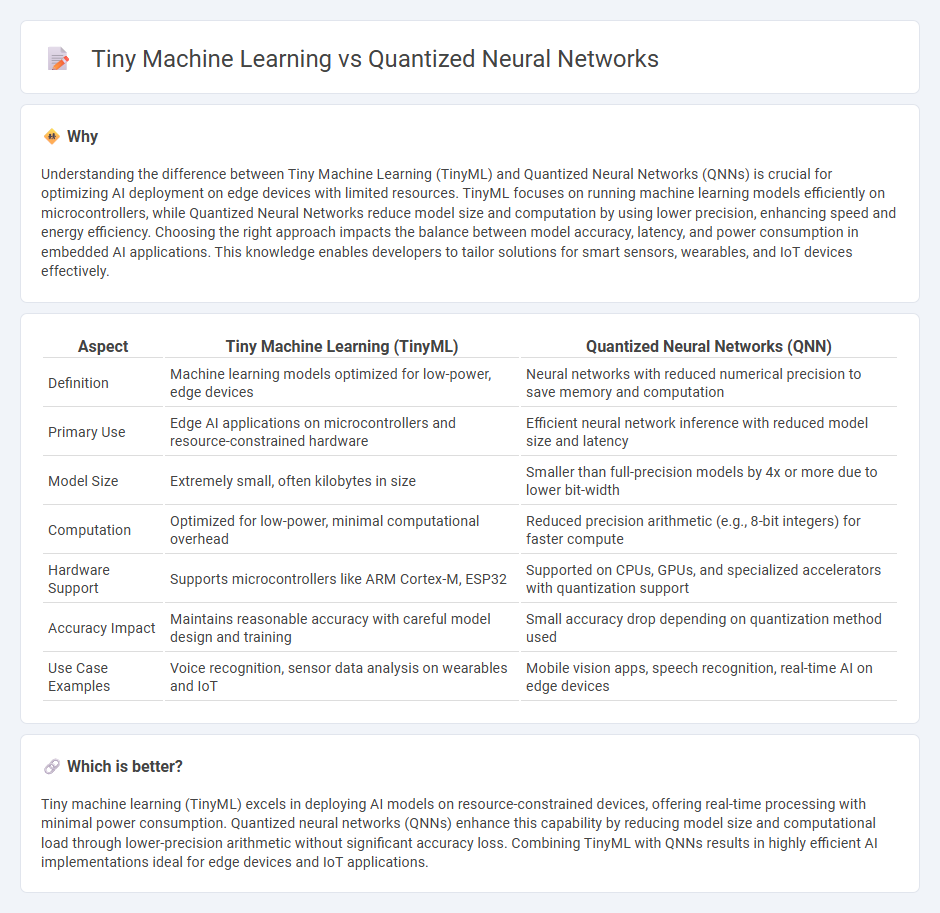
Understanding the difference between Tiny Machine Learning (TinyML) and Quantized Neural Networks (QNNs) is crucial for optimizing AI deployment on edge devices with limited resources. TinyML focuses on running machine learning models efficiently on microcontrollers, while Quantized Neural Networks reduce model size and computation by using lower precision, enhancing speed and energy efficiency. Choosing the right approach impacts the balance between model accuracy, latency, and power consumption in embedded AI applications. This knowledge enables developers to tailor solutions for smart sensors, wearables, and IoT devices effectively.
Comparison Table
| Aspect | Tiny Machine Learning (TinyML) | Quantized Neural Networks (QNN) |
|---|---|---|
| Definition | Machine learning models optimized for low-power, edge devices | Neural networks with reduced numerical precision to save memory and computation |
| Primary Use | Edge AI applications on microcontrollers and resource-constrained hardware | Efficient neural network inference with reduced model size and latency |
| Model Size | Extremely small, often kilobytes in size | Smaller than full-precision models by 4x or more due to lower bit-width |
| Computation | Optimized for low-power, minimal computational overhead | Reduced precision arithmetic (e.g., 8-bit integers) for faster compute |
| Hardware Support | Supports microcontrollers like ARM Cortex-M, ESP32 | Supported on CPUs, GPUs, and specialized accelerators with quantization support |
| Accuracy Impact | Maintains reasonable accuracy with careful model design and training | Small accuracy drop depending on quantization method used |
| Use Case Examples | Voice recognition, sensor data analysis on wearables and IoT | Mobile vision apps, speech recognition, real-time AI on edge devices |
Which is better?
Tiny machine learning (TinyML) excels in deploying AI models on resource-constrained devices, offering real-time processing with minimal power consumption. Quantized neural networks (QNNs) enhance this capability by reducing model size and computational load through lower-precision arithmetic without significant accuracy loss. Combining TinyML with QNNs results in highly efficient AI implementations ideal for edge devices and IoT applications.
Connection
Tiny machine learning leverages quantized neural networks to efficiently run AI models on resource-constrained devices by reducing model size and computational requirements. Quantized neural networks convert floating-point weights into lower-bit representations, enabling faster inference and lower power consumption, crucial for edge computing applications. This synergy allows deployment of intelligent applications in wearable devices, IoT sensors, and embedded systems with limited memory and processing power.
Key Terms
Model Compression
Quantized neural networks dramatically reduce model size and computational complexity by representing weights and activations with lower precision, typically using 8-bit or fewer bits, enabling deployment on resource-constrained devices. Tiny Machine Learning (TinyML) emphasizes running compact models directly on microcontrollers and edge devices, leveraging various model compression techniques like pruning, quantization, and knowledge distillation to achieve efficient inference. Explore how these approaches transform AI deployment in ultra-low-power environments by learning more about cutting-edge model compression strategies.
Edge Deployment
Quantized neural networks reduce model size and computational load by representing weights and activations with lower precision, making them highly suitable for edge deployment in resource-constrained environments. Tiny Machine Learning (TinyML) encompasses the broader scope of running machine learning models on ultra-low-power devices, often leveraging techniques like quantization, pruning, and efficient model architectures for real-time inference. Explore detailed comparisons and deployment strategies to optimize AI performance on edge devices.
Resource Efficiency
Quantized neural networks significantly reduce model size and computational complexity by representing weights and activations with lower bit-widths, thereby enhancing resource efficiency for embedded devices. Tiny machine learning emphasizes deploying ultra-small models optimized for constrained hardware environments, integrating techniques such as model pruning, compression, and quantization to minimize memory footprint and power consumption. Explore in-depth comparisons and practical applications of quantized neural networks and TinyML to maximize efficiency in edge AI deployments.
Source and External Links
A White Paper on Neural Network Quantization - Explains both post-training and quantization-aware training approaches, detailing standard pipelines for quantizing modern neural networks with minimal accuracy loss and practical debugging workflows.
Training Neural Networks with Low Precision Weights - Demonstrates that neural networks can be trained and inferenced with extremely low bit-widths (e.g., 1-bit weights), achieving comparable accuracy to full-precision models while drastically reducing memory usage and power consumption.
Neural Network Quantization: What Is It and How Does It Relate to Tiny Machine Learning? - Describes quantization as reducing precision of weights, biases, and activations from 32-bit floats to smaller formats (e.g., 8-bit integers), yielding significant memory savings, faster inference, and improved power efficiency.