Synthetic data is artificially generated information created through algorithms and simulations, often used to train machine learning models without relying on real-world data. Empirical data, on the other hand, is collected through direct observation or experimentation, providing authentic insights rooted in reality. Explore the differences and advantages of synthetic versus empirical data to enhance your technology strategies.
Why it is important
Understanding the difference between synthetic data and empirical data is crucial for technology development because synthetic data allows for scalable, privacy-preserving simulations while empirical data provides real-world accuracy and validation. Synthetic data is generated by algorithms to mimic real datasets without exposing sensitive information, making it valuable in training machine learning models when empirical data is scarce or restricted. Empirical data, collected from actual observations and experiments, ensures that models and systems are grounded in reality and perform reliably in practical applications. This distinction impacts data quality, model performance, ethical considerations, and the feasibility of technological innovation.
Comparison Table
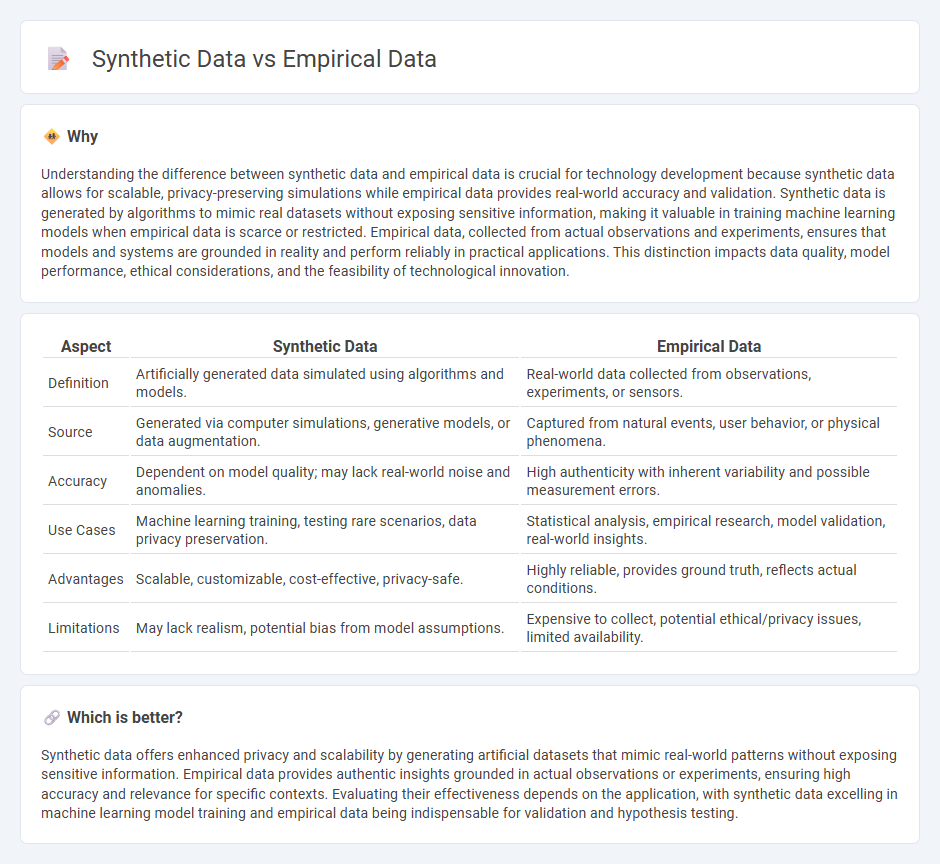
| Aspect | Synthetic Data | Empirical Data |
|---|---|---|
| Definition | Artificially generated data simulated using algorithms and models. | Real-world data collected from observations, experiments, or sensors. |
| Source | Generated via computer simulations, generative models, or data augmentation. | Captured from natural events, user behavior, or physical phenomena. |
| Accuracy | Dependent on model quality; may lack real-world noise and anomalies. | High authenticity with inherent variability and possible measurement errors. |
| Use Cases | Machine learning training, testing rare scenarios, data privacy preservation. | Statistical analysis, empirical research, model validation, real-world insights. |
| Advantages | Scalable, customizable, cost-effective, privacy-safe. | Highly reliable, provides ground truth, reflects actual conditions. |
| Limitations | May lack realism, potential bias from model assumptions. | Expensive to collect, potential ethical/privacy issues, limited availability. |
Which is better?
Synthetic data offers enhanced privacy and scalability by generating artificial datasets that mimic real-world patterns without exposing sensitive information. Empirical data provides authentic insights grounded in actual observations or experiments, ensuring high accuracy and relevance for specific contexts. Evaluating their effectiveness depends on the application, with synthetic data excelling in machine learning model training and empirical data being indispensable for validation and hypothesis testing.
Connection
Synthetic data enhances empirical data by providing large-scale, diverse datasets that address privacy concerns and fill gaps in real-world data collection. Empirical data validates and calibrates synthetic datasets, ensuring their accuracy and applicability in machine learning models. Combining both data types improves model robustness and accelerates AI development across various technology sectors.
Key Terms
Real-world observations
Empirical data derives from real-world observations and actual measurements, ensuring accuracy and relevance in practical applications such as clinical trials and market research. Synthetic data, generated through algorithms and simulations, offers scalability and privacy benefits but may lack the authenticity and unpredictability present in genuine datasets. Explore more to understand when to leverage empirical data versus synthetic data effectively.
Data generation algorithms
Empirical data originates from actual observations or measurements collected from real-world events, relying heavily on data generation algorithms to extract, preprocess, and structure this information accurately for analysis. Synthetic data is produced through advanced data generation algorithms that simulate realistic datasets by creating artificial instances based on statistical models, machine learning techniques, or generative adversarial networks, enabling privacy preservation and handling data scarcity. Explore further to understand the strengths and applications of these data generation algorithms in different domains.
Model validation
Empirical data, derived from real-world observations, provides authentic scenarios for model validation, ensuring that performance metrics reflect actual conditions and variability. Synthetic data, generated through algorithms, offers controlled environments to test models against rare or extreme cases, enhancing robustness and generalization. Explore more about leveraging both data types for comprehensive model validation strategies.
Source and External Links
Empirical research - Wikipedia - Empirical data is gathered using observable evidence through the senses, and statistical methods are used in scientific studies to analyze such data to support or reject hypotheses without claiming absolute proof.
Empirical Evidence | Definition, Types & Examples - Lesson - Empirical data is information collected from direct observations or experiments using the five senses, providing objective evidence that can be consistently replicated under the same conditions.
What is empirical analysis and how does it work? - TechTarget - Empirical data can be gathered through quantitative or qualitative research methods, involving measurements or observations that can be verified by experience or senses to inform analysis.