Generative Adversarial Networks (GANs) utilize a dual neural network framework where a generator creates data while a discriminator evaluates its authenticity, leading to highly realistic synthetic outputs. Diffusion models generate data by reversing a gradual noising process, excelling in producing detailed and diverse images with stable training dynamics. Explore the unique strengths and applications of GANs and diffusion models to understand their impact on advancements in artificial intelligence.
Why it is important
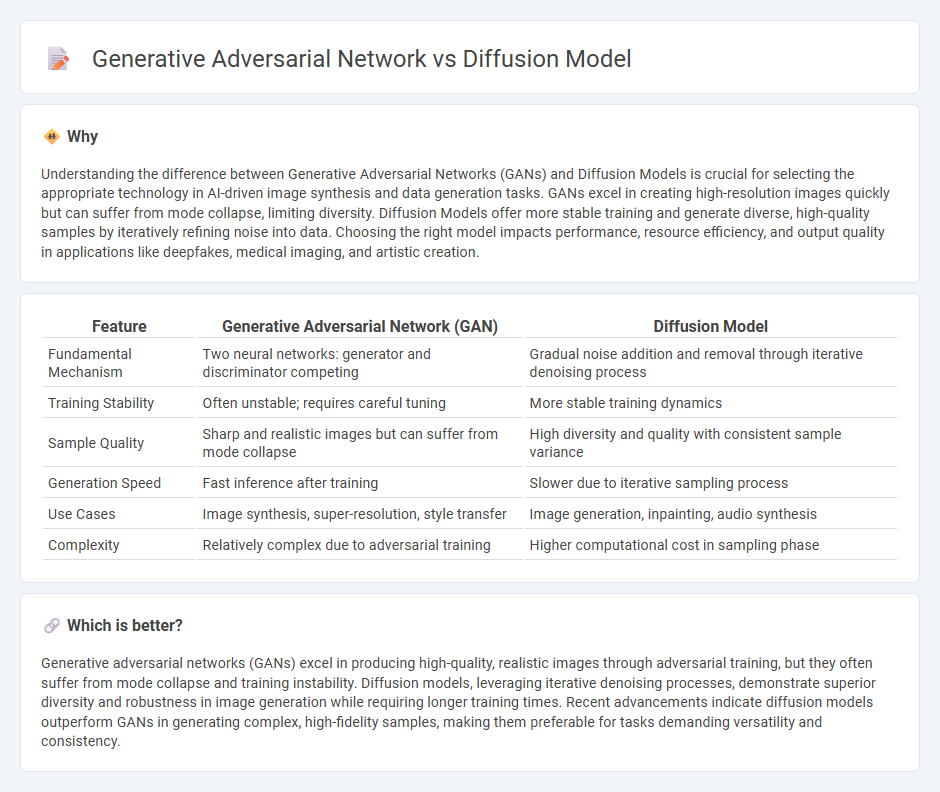
Understanding the difference between Generative Adversarial Networks (GANs) and Diffusion Models is crucial for selecting the appropriate technology in AI-driven image synthesis and data generation tasks. GANs excel in creating high-resolution images quickly but can suffer from mode collapse, limiting diversity. Diffusion Models offer more stable training and generate diverse, high-quality samples by iteratively refining noise into data. Choosing the right model impacts performance, resource efficiency, and output quality in applications like deepfakes, medical imaging, and artistic creation.
Comparison Table
| Feature | Generative Adversarial Network (GAN) | Diffusion Model |
|---|---|---|
| Fundamental Mechanism | Two neural networks: generator and discriminator competing | Gradual noise addition and removal through iterative denoising process |
| Training Stability | Often unstable; requires careful tuning | More stable training dynamics |
| Sample Quality | Sharp and realistic images but can suffer from mode collapse | High diversity and quality with consistent sample variance |
| Generation Speed | Fast inference after training | Slower due to iterative sampling process |
| Use Cases | Image synthesis, super-resolution, style transfer | Image generation, inpainting, audio synthesis |
| Complexity | Relatively complex due to adversarial training | Higher computational cost in sampling phase |
Which is better?
Generative adversarial networks (GANs) excel in producing high-quality, realistic images through adversarial training, but they often suffer from mode collapse and training instability. Diffusion models, leveraging iterative denoising processes, demonstrate superior diversity and robustness in image generation while requiring longer training times. Recent advancements indicate diffusion models outperform GANs in generating complex, high-fidelity samples, making them preferable for tasks demanding versatility and consistency.
Connection
Generative Adversarial Networks (GANs) and diffusion models both belong to the class of generative models designed to create realistic synthetic data by learning underlying data distributions. GANs operate through a competitive process between a generator and a discriminator to produce high-quality outputs, while diffusion models generate data by gradually denoising from random noise using a learned Markov chain. Both techniques have advanced state-of-the-art performance in image synthesis, with diffusion models gaining prominence for their stable training and ability to model complex distributions more effectively than traditional GANs.
Key Terms
Stochastic Process
Diffusion models utilize stochastic processes by gradually adding noise to data and learning to reverse this process to generate samples, contrasting with Generative Adversarial Networks (GANs) that employ a game-theoretic approach to train a generator and discriminator competitively. The stochastic nature of diffusion models leads to more stable training and often higher quality outputs in image generation tasks, while GANs may suffer from mode collapse and training instability. Explore the latest advancements in diffusion models and GANs for deeper insights into their stochastic mechanisms and applications.
Discriminator
The discriminator in a Generative Adversarial Network (GAN) functions as a binary classifier distinguishing between real and generated data, driving the generator to create realistic outputs by providing feedback. In contrast, diffusion models employ a denoising process where no explicit discriminator is used; instead, the model learns to reverse a gradual noise addition process to generate data. Discover how the discriminator's role impacts the training dynamics and output quality in these generative models.
Latent Space
Diffusion models and Generative Adversarial Networks (GANs) differ significantly in their approach to latent space representation; diffusion models gradually transform noise into data through iterative denoising steps, effectively exploring the latent space as a progressive refinement process. GANs consist of a generator mapping its latent space to data distribution directly, fostering adversarial learning dynamics that shape the latent manifold for realistic sample generation. Explore detailed comparisons of latent space structures and training dynamics to better understand their unique advantages and applications.
Source and External Links
Introduction to Diffusion Models for Machine Learning - Diffusion models are generative models that progressively add noise to data in a forward diffusion process and learn to reverse this process to generate new data, particularly images, by denoising Gaussian noise step-by-step.
How diffusion models work: the math from scratch - These state-of-the-art generative models create high-resolution images through many incremental denoising steps, enabling gradual self-correction of the output but making sampling slower compared to GANs.
What are Diffusion Models? | IBM - Inspired by physics, diffusion models treat pixels like molecules diffusing and learn to reverse noise diffusion in images, resulting in high-quality image generation and outperforming prior generative approaches like VAEs and GANs.