Differential privacy and data masking are two critical techniques used to protect sensitive information in data processing and analytics. Differential privacy injects noise to datasets, ensuring individual privacy without significantly compromising data utility, while data masking alters or obscures data elements to prevent unauthorized access. Explore the key differences and applications of differential privacy versus data masking to enhance your data protection strategy.
Why it is important
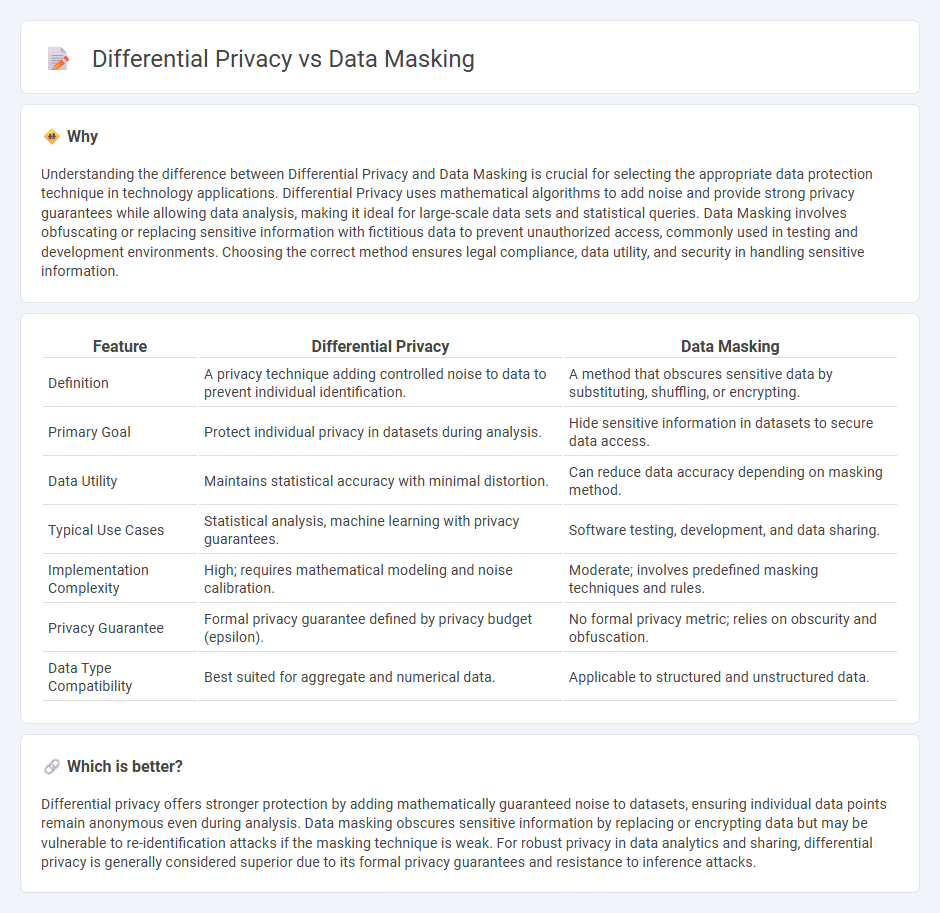
Understanding the difference between Differential Privacy and Data Masking is crucial for selecting the appropriate data protection technique in technology applications. Differential Privacy uses mathematical algorithms to add noise and provide strong privacy guarantees while allowing data analysis, making it ideal for large-scale data sets and statistical queries. Data Masking involves obfuscating or replacing sensitive information with fictitious data to prevent unauthorized access, commonly used in testing and development environments. Choosing the correct method ensures legal compliance, data utility, and security in handling sensitive information.
Comparison Table
| Feature | Differential Privacy | Data Masking |
|---|---|---|
| Definition | A privacy technique adding controlled noise to data to prevent individual identification. | A method that obscures sensitive data by substituting, shuffling, or encrypting. |
| Primary Goal | Protect individual privacy in datasets during analysis. | Hide sensitive information in datasets to secure data access. |
| Data Utility | Maintains statistical accuracy with minimal distortion. | Can reduce data accuracy depending on masking method. |
| Typical Use Cases | Statistical analysis, machine learning with privacy guarantees. | Software testing, development, and data sharing. |
| Implementation Complexity | High; requires mathematical modeling and noise calibration. | Moderate; involves predefined masking techniques and rules. |
| Privacy Guarantee | Formal privacy guarantee defined by privacy budget (epsilon). | No formal privacy metric; relies on obscurity and obfuscation. |
| Data Type Compatibility | Best suited for aggregate and numerical data. | Applicable to structured and unstructured data. |
Which is better?
Differential privacy offers stronger protection by adding mathematically guaranteed noise to datasets, ensuring individual data points remain anonymous even during analysis. Data masking obscures sensitive information by replacing or encrypting data but may be vulnerable to re-identification attacks if the masking technique is weak. For robust privacy in data analytics and sharing, differential privacy is generally considered superior due to its formal privacy guarantees and resistance to inference attacks.
Connection
Differential privacy and data masking both aim to protect sensitive information in datasets by minimizing the risk of exposing individual data points. Differential privacy applies mathematical mechanisms to add noise and ensure that aggregate data remains confidential, while data masking alters or hides specific data elements to prevent unauthorized access. Together, these techniques enhance data security frameworks by balancing usability with privacy in technology-driven environments.
Key Terms
Anonymization
Data masking anonymizes sensitive information by obscuring specific data elements within a dataset, ensuring that individual identities cannot be directly identified while maintaining the utility of the data for analysis. Differential privacy adds a mathematical guarantee to data anonymization by introducing controlled random noise, which protects individual privacy even against sophisticated inference attacks. Explore the detailed differences and use cases of these anonymization techniques to enhance your data privacy strategy.
Noise injection
Data masking replaces sensitive information with realistic but fictitious data to protect privacy, while differential privacy introduces mathematically calibrated noise to data queries to ensure individual data points cannot be reidentified. Noise injection in differential privacy is carefully designed to balance data utility and privacy guarantees, using techniques like Laplace or Gaussian mechanisms. Explore how these noise injection methods enhance data security and maintain analytical accuracy.
Re-identification risk
Data masking reduces re-identification risk by obscuring sensitive data elements through techniques like tokenization or encryption, which can limit data utility but protect individual privacy. Differential privacy provides mathematical guarantees by adding randomized noise to data or query results, significantly lowering re-identification risk even against adversaries with auxiliary information. Explore detailed comparisons to understand the nuanced trade-offs between these two privacy-preserving methods.
Source and External Links
Data Masking: 8 Techniques and How to Implement Them - Data masking is a technique to create a structurally similar version of data that hides sensitive information to allow safe use in testing, training, or by third parties, using methods like character shuffling, substitution, scrambling, deletion, or encryption to prevent reverse engineering.
What is Data Masking? - Perforce - Data masking protects sensitive data by replacing original values with realistic fictitious equivalents and includes types like static, dynamic, on-the-fly masking, obfuscation, redaction, scrambling, and tokenization, adapted for various data protection needs in non-production environments.
Data masking - Wikipedia - Data masking (or obfuscation) modifies sensitive data to minimize value to unauthorized users while maintaining usability for testing and development, addressing risks of unauthorized access outside production systems by applying consistent, realistic changes to protect personally identifiable information and critical data.