Vector databases specialize in storing and querying high-dimensional vector data, making them ideal for applications involving machine learning, image recognition, and natural language processing. Document databases store semi-structured data in formats like JSON or BSON, optimizing flexible, schema-less storage for web applications and content management. Explore further to understand which database architecture best suits your data management needs.
Why it is important
Understanding the difference between vector databases and document databases is crucial for optimizing data storage and retrieval based on use cases like machine learning or text search. Vector databases efficiently handle high-dimensional data such as embeddings for AI applications, enabling fast similarity searches. Document databases store structured or semi-structured data like JSON, supporting complex queries and indexing. Choosing the appropriate database type enhances system performance and scalability in technology-driven environments.
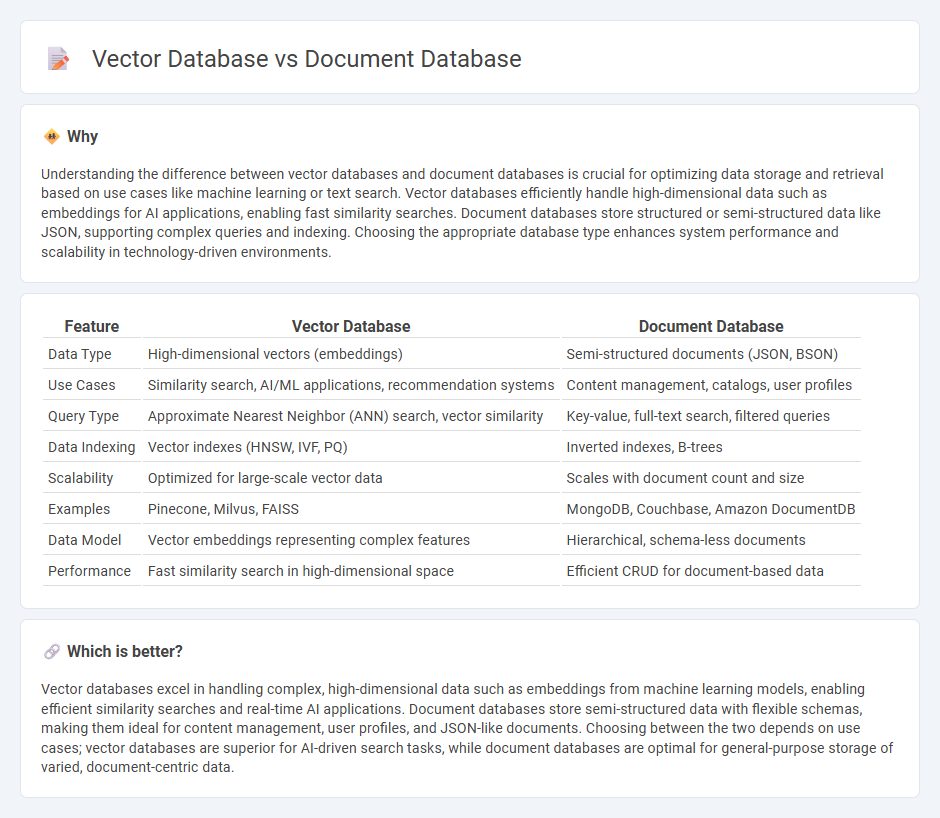
Comparison Table
| Feature | Vector Database | Document Database |
|---|---|---|
| Data Type | High-dimensional vectors (embeddings) | Semi-structured documents (JSON, BSON) |
| Use Cases | Similarity search, AI/ML applications, recommendation systems | Content management, catalogs, user profiles |
| Query Type | Approximate Nearest Neighbor (ANN) search, vector similarity | Key-value, full-text search, filtered queries |
| Data Indexing | Vector indexes (HNSW, IVF, PQ) | Inverted indexes, B-trees |
| Scalability | Optimized for large-scale vector data | Scales with document count and size |
| Examples | Pinecone, Milvus, FAISS | MongoDB, Couchbase, Amazon DocumentDB |
| Data Model | Vector embeddings representing complex features | Hierarchical, schema-less documents |
| Performance | Fast similarity search in high-dimensional space | Efficient CRUD for document-based data |
Which is better?
Vector databases excel in handling complex, high-dimensional data such as embeddings from machine learning models, enabling efficient similarity searches and real-time AI applications. Document databases store semi-structured data with flexible schemas, making them ideal for content management, user profiles, and JSON-like documents. Choosing between the two depends on use cases; vector databases are superior for AI-driven search tasks, while document databases are optimal for general-purpose storage of varied, document-centric data.
Connection
Vector databases and document databases intersect through their complementary roles in managing and retrieving unstructured data, with vector databases specializing in storing high-dimensional vector embeddings for similarity search and document databases organizing textual or semi-structured documents. Vector databases enhance document databases by enabling semantic search capabilities, allowing retrieval of documents based on contextual meaning rather than keyword matching. This synergy is particularly valuable in applications like natural language processing and recommendation systems, where understanding and querying data through its semantic content improves accuracy and relevance.
Key Terms
Data Structure
Document databases organize data as collections of JSON-like documents, enabling flexible schemas that accommodate nested fields and various data types for efficient querying and indexing. Vector databases store data as high-dimensional numeric vectors optimized for similarity search, using specialized indexing methods like HNSW or Annoy to rapidly find nearest neighbors in machine learning and AI applications. Explore the differences and use cases of document and vector databases to optimize your data storage strategy.
Query Mechanism
Document databases utilize structured queries such as JSON or SQL-like syntax to search and retrieve stored documents based on fields and criteria, emphasizing exact matches and indexing for efficient access. Vector databases employ similarity search algorithms that calculate distances between high-dimensional vectors representing unstructured data like text, images, or audio, enabling approximate nearest neighbor queries for semantic matching. Explore further to understand how these query mechanisms impact use cases and performance in modern data management.
Use Case
Document databases excel in storing and managing semi-structured data such as JSON, making them ideal for content management systems, e-commerce catalogs, and real-time analytics. Vector databases are optimized for similarity search tasks, supporting use cases like image recognition, recommendation systems, and natural language processing by handling high-dimensional vector embeddings. Explore detailed comparisons to understand which solution aligns best with your specific application needs.
Source and External Links
What Is a Document Database? - AWS - A document database is a type of NoSQL database that stores and queries data as JSON-like documents, allowing flexible schema configurations.
Document-oriented database - Wikipedia - A document-oriented database is a data storage system designed for storing, retrieving, and managing semi-structured data without a predefined schema.
A Guide to Document Databases | InfluxData - This guide provides an overview of document databases, how they work, their benefits, and common use cases, offering insights into agile data management.