Vector databases specialize in storing and retrieving high-dimensional data, enabling efficient similarity searches crucial for AI and machine learning applications. Wide-column stores organize data in flexible, column-oriented structures optimized for large-scale, distributed database environments, often used in real-time analytics and big data processing. Explore the advantages and use cases of vector databases versus wide-column stores to determine the best fit for your technology needs.
Why it is important
Understanding the difference between vector databases and wide-column stores is crucial for selecting the right data management solution tailored to specific use cases like similarity search versus large-scale tabular data storage. Vector databases optimize searching and analyzing high-dimensional data generated by AI and machine learning, improving recommendation accuracy and image recognition. Wide-column stores excel at handling massive volumes of distributed, schema-flexible data with fast read and write capabilities in applications like IoT and real-time analytics. Choosing the appropriate database enhances performance, scalability, and relevancy of insights derived from complex datasets.
Comparison Table
| Feature | Vector Databases | Wide-Column Stores |
|---|---|---|
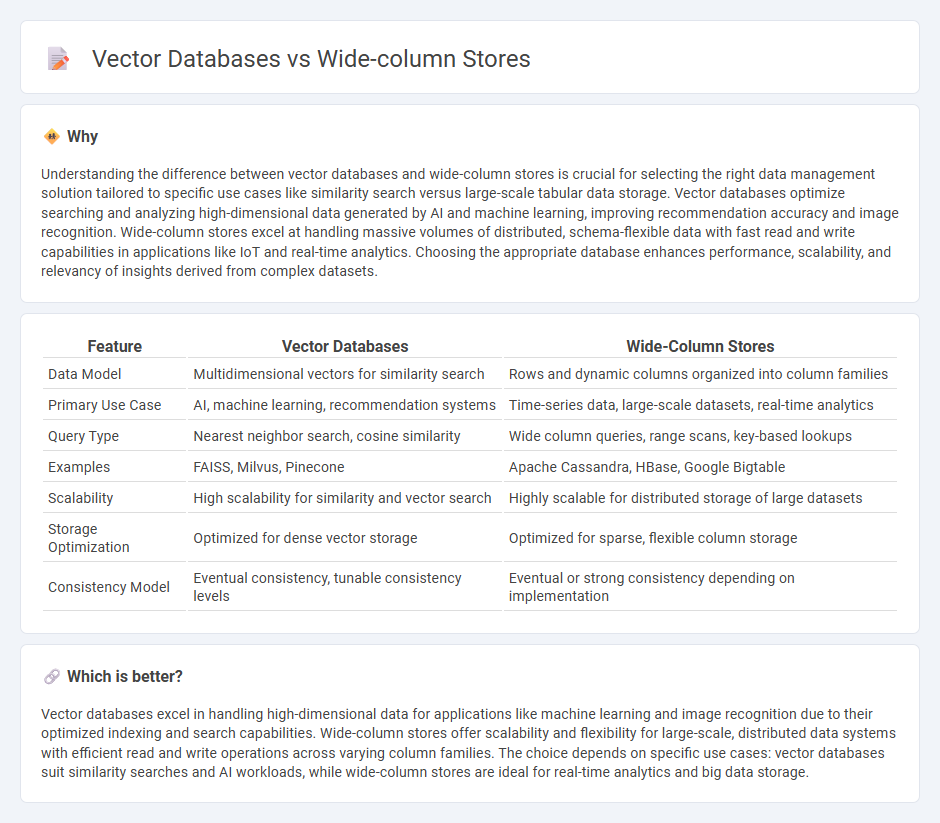
| Data Model | Multidimensional vectors for similarity search | Rows and dynamic columns organized into column families |
| Primary Use Case | AI, machine learning, recommendation systems | Time-series data, large-scale datasets, real-time analytics |
| Query Type | Nearest neighbor search, cosine similarity | Wide column queries, range scans, key-based lookups |
| Examples | FAISS, Milvus, Pinecone | Apache Cassandra, HBase, Google Bigtable |
| Scalability | High scalability for similarity and vector search | Highly scalable for distributed storage of large datasets |
| Storage Optimization | Optimized for dense vector storage | Optimized for sparse, flexible column storage |
| Consistency Model | Eventual consistency, tunable consistency levels | Eventual or strong consistency depending on implementation |
Which is better?
Vector databases excel in handling high-dimensional data for applications like machine learning and image recognition due to their optimized indexing and search capabilities. Wide-column stores offer scalability and flexibility for large-scale, distributed data systems with efficient read and write operations across varying column families. The choice depends on specific use cases: vector databases suit similarity searches and AI workloads, while wide-column stores are ideal for real-time analytics and big data storage.
Connection
Vector databases and wide-column stores both manage large-scale, high-dimensional data efficiently, enabling advanced machine learning and AI applications. Vector databases index and retrieve data based on mathematical vectors for semantic search, while wide-column stores organize data into flexible, scalable columns optimized for distributed storage. Their connection lies in complementing scalable data architectures, where vector databases often leverage wide-column stores to handle vast datasets and enhance query performance in modern technology ecosystems.
Key Terms
Schema Flexibility
Wide-column stores provide Schema Flexibility by allowing dynamic columns within rows, enabling efficient management of sparse data and heterogeneous attributes. Vector databases focus on schema-less storage optimized for high-dimensional data embeddings, facilitating rapid similarity searches without rigid structural constraints. Explore more to understand how schema flexibility impacts data modeling and query performance in these database types.
Data Retrieval
Wide-column stores like Apache Cassandra optimize data retrieval using partition keys and clustering columns to efficiently query large, sparse datasets with high throughput. Vector databases, such as Pinecone or Milvus, enhance retrieval by leveraging similarity search algorithms on multi-dimensional embeddings, ideal for unstructured data like images or text. Explore the unique data retrieval methods of both systems to determine the best match for your specific application needs.
Indexing Methods
Wide-column stores use sparse, multidimensional mapping to index data, typically leveraging primary keys and clustering keys for efficient query performance on large datasets. Vector databases employ similarity search indexing techniques such as Approximate Nearest Neighbor (ANN) algorithms, including HNSW, Faiss, or Annoy, to rapidly retrieve high-dimensional vector representations. Explore more about their indexing strategies to optimize data retrieval based on your application's specific needs.
Source and External Links
Wide-column store - A wide-column store is a type of NoSQL database that uses tables with flexible column structures, ideal for handling large datasets.
Wide Column Databases - NoSQL Databases Overview - This video provides an overview of wide-column databases, highlighting their structure and capabilities in handling large data volumes.
Tablestore: Wide Column model - Alibaba Cloud's Wide Column model supports schema-free data tables with features like wide columns and time to live (TTL) management, suitable for big data storage.