Generative video technology leverages artificial intelligence to create entirely new video content from textual input or other data sources, enabling dynamic and customizable visuals. In contrast, video captioning uses machine learning algorithms to analyze video frames and generate accurate textual descriptions, improving accessibility and searchability. Explore the latest advancements to understand how these technologies transform video production and consumption.
Why it is important
Understanding the difference between Generative Video and Video Captioning is crucial for optimizing AI applications in media production and content accessibility. Generative Video uses artificial intelligence to create new video content from scratch, while Video Captioning involves analyzing existing videos to produce accurate textual descriptions. This distinction enables developers and marketers to select appropriate technologies for creative generation or enhancing user experience through improved video search and accessibility. Accurate knowledge of these technologies drives innovation in entertainment, education, and assistive media tools.
Comparison Table
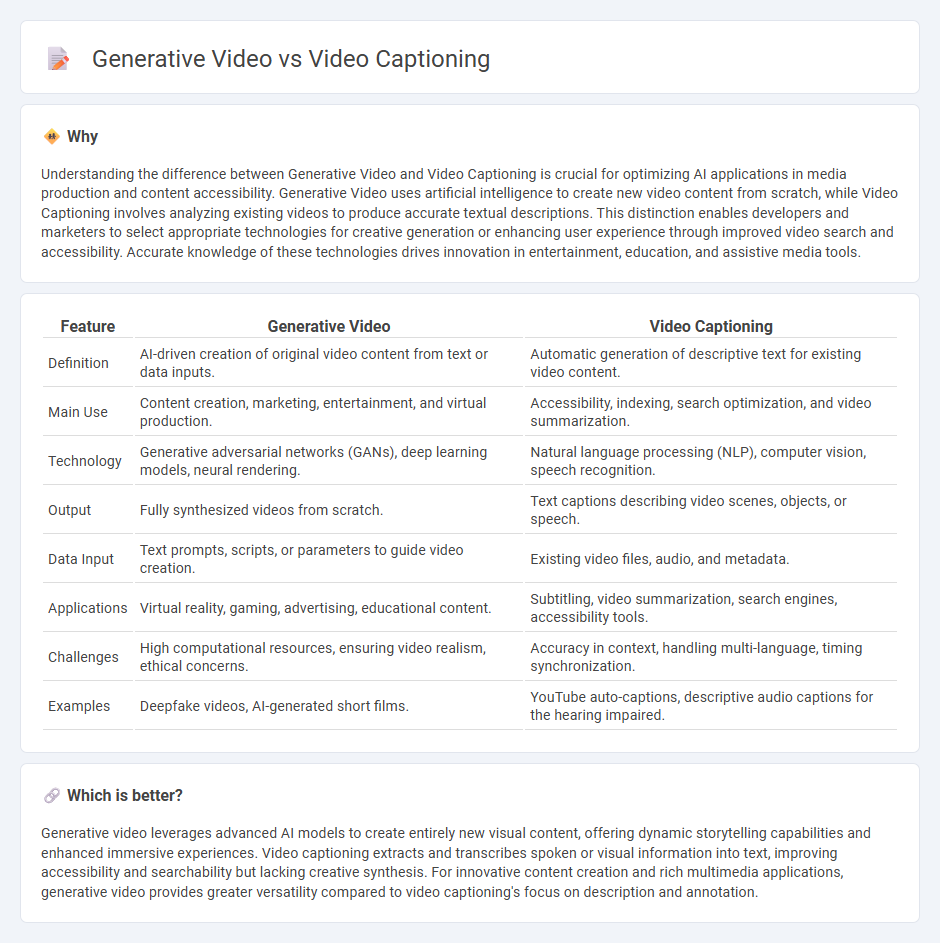
| Feature | Generative Video | Video Captioning |
|---|---|---|
| Definition | AI-driven creation of original video content from text or data inputs. | Automatic generation of descriptive text for existing video content. |
| Main Use | Content creation, marketing, entertainment, and virtual production. | Accessibility, indexing, search optimization, and video summarization. |
| Technology | Generative adversarial networks (GANs), deep learning models, neural rendering. | Natural language processing (NLP), computer vision, speech recognition. |
| Output | Fully synthesized videos from scratch. | Text captions describing video scenes, objects, or speech. |
| Data Input | Text prompts, scripts, or parameters to guide video creation. | Existing video files, audio, and metadata. |
| Applications | Virtual reality, gaming, advertising, educational content. | Subtitling, video summarization, search engines, accessibility tools. |
| Challenges | High computational resources, ensuring video realism, ethical concerns. | Accuracy in context, handling multi-language, timing synchronization. |
| Examples | Deepfake videos, AI-generated short films. | YouTube auto-captions, descriptive audio captions for the hearing impaired. |
Which is better?
Generative video leverages advanced AI models to create entirely new visual content, offering dynamic storytelling capabilities and enhanced immersive experiences. Video captioning extracts and transcribes spoken or visual information into text, improving accessibility and searchability but lacking creative synthesis. For innovative content creation and rich multimedia applications, generative video provides greater versatility compared to video captioning's focus on description and annotation.
Connection
Generative video technology leverages artificial intelligence to create or synthesize video content from text or images, while video captioning employs machine learning models to automatically generate descriptive text for videos. Both technologies use deep neural networks and natural language processing to bridge visual and textual information, enhancing content accessibility and creation. Integrating generative video with video captioning enables automated production of fully captioned video content, improving user engagement and supporting compliance with accessibility standards.
Key Terms
Temporal Modeling
Temporal modeling in video captioning involves analyzing sequential frames to generate accurate, context-aware descriptions that capture evolving actions and events over time. Generative video models, on the other hand, focus on synthesizing new video content by predicting temporal dynamics and spatial coherence to produce realistic motion and scene transitions. Explore the latest advancements in temporal modeling techniques to understand their impact on video captioning and generative video technology.
Multimodal Learning
Multimodal learning enhances video captioning by integrating visual and textual data to generate accurate and context-rich descriptions that improve accessibility and searchability. Generative video models leverage deep neural networks to create new video content by synthesizing information from multiple modalities such as images, text, and audio, advancing creative applications and media production. Explore the latest innovations in multimodal learning to understand how these technologies transform video analysis and generation.
Sequence Generation
Video captioning involves generating descriptive text sequences from video content by analyzing visual frames and extracting relevant semantic information, enabling accurate temporal alignment of words with visual events. Generative video, in contrast, focuses on synthesizing new video sequences from textual or visual inputs using advanced models like GANs or transformers, emphasizing coherent temporal and spatial sequence generation. Explore the intricacies of sequence generation techniques in video captioning and generative video to enhance multimedia understanding and creation.
Source and External Links
Add Subtitles to Video: Video Captions Generator - Canva - Canva's Captions tool allows you to automatically generate and customize subtitles for videos, making content more accessible and engaging without requiring video editing skills.
Shreyz-max/Video-Captioning - GitHub - This is a sequence-to-sequence encoder-decoder model project that generates descriptive captions from videos, useful for accessibility and video content classification purposes.
Add Captions to Videos Online for Free | Adobe Express - Adobe Express offers a free online tool to quickly generate, edit, and style captions for videos, helping videos be accessible and engaging even when watched without sound.