Vector databases excel in managing high-dimensional data like embeddings for AI and machine learning applications, enabling efficient similarity search and nearest neighbor queries. Multimodel databases support diverse data types such as documents, graphs, and key-value pairs within a single platform, offering flexibility for varied workloads across industries. Explore further to understand which database architecture best suits your data strategy and application needs.
Why it is important
Understanding the difference between vector databases and multimodel databases is crucial for selecting the right storage and retrieval system based on data types and use cases. Vector databases specialize in handling high-dimensional data such as embeddings from AI models, enabling efficient similarity search and machine learning applications. Multimodel databases support multiple data models like graph, document, and relational within a single platform, offering flexibility for diverse application requirements. Choosing the correct database type optimizes performance, scalability, and analytical capabilities in technology solutions.
Comparison Table
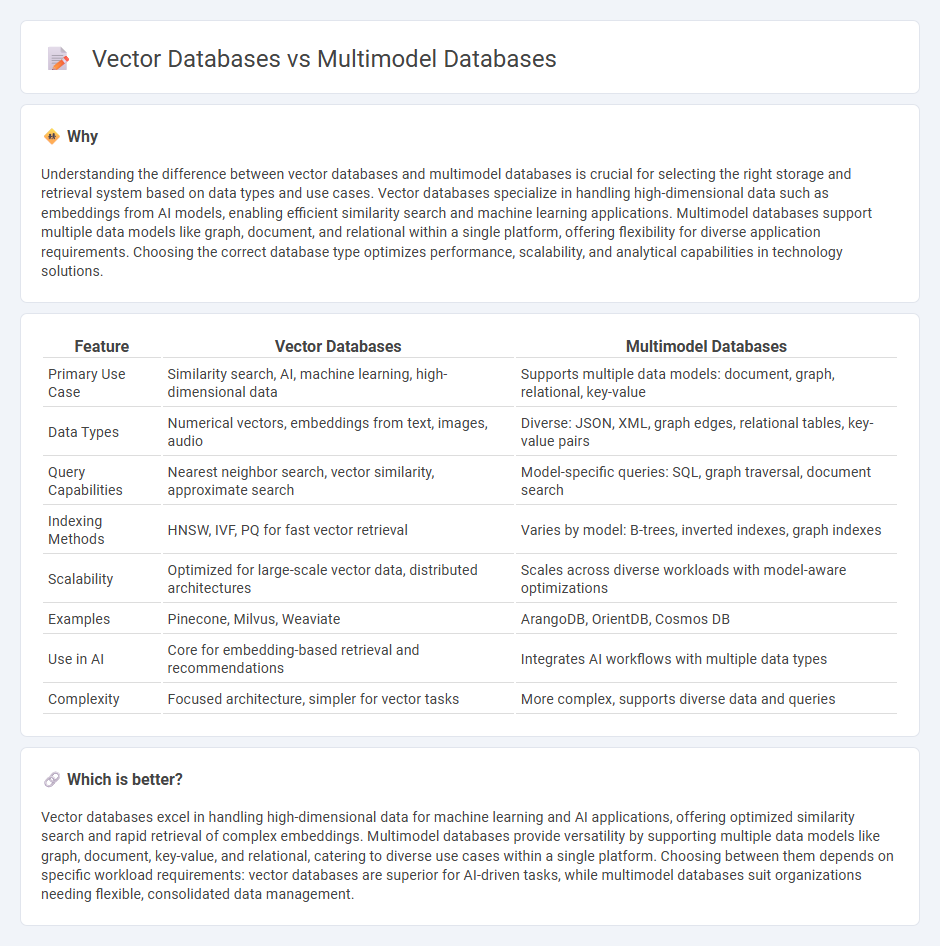
| Feature | Vector Databases | Multimodel Databases |
|---|---|---|
| Primary Use Case | Similarity search, AI, machine learning, high-dimensional data | Supports multiple data models: document, graph, relational, key-value |
| Data Types | Numerical vectors, embeddings from text, images, audio | Diverse: JSON, XML, graph edges, relational tables, key-value pairs |
| Query Capabilities | Nearest neighbor search, vector similarity, approximate search | Model-specific queries: SQL, graph traversal, document search |
| Indexing Methods | HNSW, IVF, PQ for fast vector retrieval | Varies by model: B-trees, inverted indexes, graph indexes |
| Scalability | Optimized for large-scale vector data, distributed architectures | Scales across diverse workloads with model-aware optimizations |
| Examples | Pinecone, Milvus, Weaviate | ArangoDB, OrientDB, Cosmos DB |
| Use in AI | Core for embedding-based retrieval and recommendations | Integrates AI workflows with multiple data types |
| Complexity | Focused architecture, simpler for vector tasks | More complex, supports diverse data and queries |
Which is better?
Vector databases excel in handling high-dimensional data for machine learning and AI applications, offering optimized similarity search and rapid retrieval of complex embeddings. Multimodel databases provide versatility by supporting multiple data models like graph, document, key-value, and relational, catering to diverse use cases within a single platform. Choosing between them depends on specific workload requirements: vector databases are superior for AI-driven tasks, while multimodel databases suit organizations needing flexible, consolidated data management.
Connection
Vector databases and multimodel databases intersect by enhancing data management capabilities through flexible data representation and retrieval. Vector databases excel in handling high-dimensional data like embeddings for AI applications, while multimodel databases support various data models such as graph, document, and relational in a single system. Integrating vector search within multimodel databases enables advanced similarity search and semantic querying across diverse data types, driving innovation in AI, recommendation systems, and knowledge graphs.
Key Terms
Data Model Flexibility
Multimodel databases support various data models such as document, graph, and key-value within a single integrated backend, offering unparalleled data model flexibility for diverse application needs. Vector databases specialize in storing and querying high-dimensional vectors, primarily used for similarity search and machine learning, thus providing optimized performance for vector data but limited data model variety. Explore more about how data model flexibility impacts database selection and application development strategies.
Indexing Methods
Multimodel databases employ diverse indexing methods such as B-trees, R-trees, and inverted indexes to efficiently manage various data types, including relational, document, graph, and key-value stores. Vector databases specialize in similarity search using approximate nearest neighbor (ANN) algorithms like HNSW, Faiss, and IVF, optimizing high-dimensional vector indexing for machine learning and AI applications. Explore the advantages and use cases of each indexing approach to determine the best fit for your data management needs.
Query Capabilities
Multimodel databases support diverse query languages and data models such as graph, document, and relational, enabling complex queries across heterogeneous datasets. Vector databases specialize in similarity search queries using high-dimensional vectors, optimizing tasks like AI-driven recommendations and image retrieval. Explore deeper insights on choosing the right database for advanced query capabilities.
Source and External Links
A Deep Dive into Multi-Model Databases: Hype vs. Reality - True multi-model databases support storing *any/all structured and unstructured data types* in a single representation and index, enabling relational, full-text search, and machine learning queries on the same data.
What is a multi-model database and why use it? | ArangoDB - Native multi-model databases like ArangoDB support multiple data models (key-value, document, graph, SQL) *simultaneously in one core system* with a single unified query language, eliminating complex data orchestration.
Multi-model database - Wikipedia - A multi-model database management system supports *multiple data models against a single, integrated backend*, enabling unified query languages and multi-model ACID transactions, with architectures varying from integrated engines to layered components.