Tiny machine learning enables efficient on-device AI by deploying compact models directly on microcontrollers, optimizing power consumption and latency. AutoML for microcontrollers automates the design and tuning of neural networks tailored for resource-constrained devices, accelerating model development without extensive expertise. Discover more about how these technologies transform embedded AI applications and enhance microcontroller performance.
Why it is important
Understanding the difference between tiny machine learning (TinyML) and AutoML for microcontrollers is crucial for optimizing resource-constrained devices. TinyML focuses on deploying efficient machine learning models directly on microcontrollers for real-time, low-power inference, while AutoML automates the model design process to achieve optimal performance and accuracy. Knowing these distinctions enables developers to select the right approach for scalable, energy-efficient edge AI applications. Proper application of TinyML and AutoML minimizes latency and maximizes device longevity in embedded systems.
Comparison Table
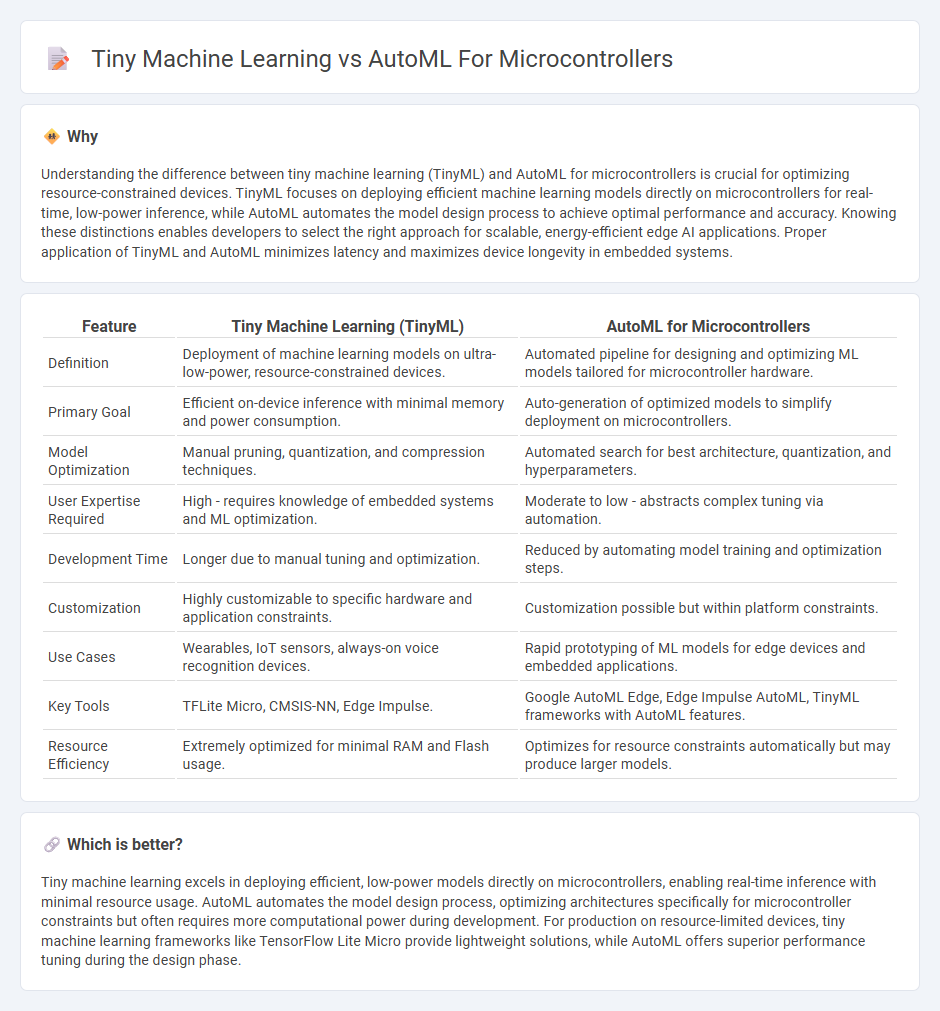
| Feature | Tiny Machine Learning (TinyML) | AutoML for Microcontrollers |
|---|---|---|
| Definition | Deployment of machine learning models on ultra-low-power, resource-constrained devices. | Automated pipeline for designing and optimizing ML models tailored for microcontroller hardware. |
| Primary Goal | Efficient on-device inference with minimal memory and power consumption. | Auto-generation of optimized models to simplify deployment on microcontrollers. |
| Model Optimization | Manual pruning, quantization, and compression techniques. | Automated search for best architecture, quantization, and hyperparameters. |
| User Expertise Required | High - requires knowledge of embedded systems and ML optimization. | Moderate to low - abstracts complex tuning via automation. |
| Development Time | Longer due to manual tuning and optimization. | Reduced by automating model training and optimization steps. |
| Customization | Highly customizable to specific hardware and application constraints. | Customization possible but within platform constraints. |
| Use Cases | Wearables, IoT sensors, always-on voice recognition devices. | Rapid prototyping of ML models for edge devices and embedded applications. |
| Key Tools | TFLite Micro, CMSIS-NN, Edge Impulse. | Google AutoML Edge, Edge Impulse AutoML, TinyML frameworks with AutoML features. |
| Resource Efficiency | Extremely optimized for minimal RAM and Flash usage. | Optimizes for resource constraints automatically but may produce larger models. |
Which is better?
Tiny machine learning excels in deploying efficient, low-power models directly on microcontrollers, enabling real-time inference with minimal resource usage. AutoML automates the model design process, optimizing architectures specifically for microcontroller constraints but often requires more computational power during development. For production on resource-limited devices, tiny machine learning frameworks like TensorFlow Lite Micro provide lightweight solutions, while AutoML offers superior performance tuning during the design phase.
Connection
Tiny machine learning (TinyML) leverages AutoML techniques to automate the design and optimization of machine learning models specifically tailored for resource-constrained microcontrollers. AutoML streamlines the model selection, hyperparameter tuning, and compression processes, enabling efficient deployment of AI applications on embedded devices with limited memory and processing power. This synergy accelerates the adoption of intelligent edge computing in IoT, wearables, and smart sensors by minimizing development time and maximizing performance on microcontroller platforms.
Key Terms
Model Compression
AutoML for microcontrollers leverages automated techniques to design models optimized for limited memory and processing power, focusing heavily on model compression strategies such as quantization and pruning. Tiny machine learning (TinyML) emphasizes deploying ultra-efficient models on edge devices with constrained resources, often utilizing specialized compression methods to minimize model size while maintaining accuracy. Explore advanced methods for maximizing ML efficiency on embedded systems by learning more about model compression techniques in AutoML and TinyML.
Edge Deployment
AutoML for microcontrollers streamlines the process of designing efficient ML models tailored specifically for resource-constrained devices, optimizing memory and power consumption. Tiny machine learning (TinyML) emphasizes deploying compact, low-latency models directly on edge devices, enabling real-time inference without reliance on cloud connectivity. Explore the nuances and advancements in these technologies to enhance edge deployment strategies.
Neural Architecture Search
Neural Architecture Search (NAS) plays a crucial role in both AutoML for microcontrollers and Tiny Machine Learning by optimizing model architectures for resource-constrained environments. AutoML frameworks specifically designed for microcontrollers leverage NAS to generate compact, energy-efficient models that meet strict latency and memory constraints, while TinyML emphasizes deploying these optimized models directly on edge devices with minimal computational overhead. Explore how NAS advancements enable scalable, efficient AI solutions for real-world embedded applications by learning more about these cutting-edge methodologies.
Source and External Links
Qeexo AutoML for Embedded Devices - Qeexo AutoML is a fully automated machine learning platform designed to build lightweight solutions for embedded devices, supporting Arm Cortex-M microcontrollers with low latency and power consumption.
Qeexo AutoML Enables Machine Learning on Arm Cortex-M0 - Qeexo AutoML supports machine learning on Arm Cortex-M0 and Cortex-M0+ processors, enabling data processing at the edge for small devices like sensors and microcontrollers.
How to Run Machine Learning Models on Microcontrollers - This article provides guidance on implementing Embedded Machine Learning (TinyML) on microcontrollers, focusing on model deployment, hardware selection, and essential frameworks for successful Embedded ML projects.