Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are advanced deep learning models used for generating realistic synthetic data. GANs consist of two neural networks--a generator and a discriminator--that compete to produce highly accurate data representations, while VAEs rely on probabilistic encodings to generate variations from latent spaces. Explore the differences in architecture and applications to understand how these models revolutionize fields like image synthesis and data augmentation.
Why it is important
Understanding the difference between Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) is crucial for selecting the right model in technology applications such as image synthesis, data augmentation, and anomaly detection. GANs generate high-quality, realistic samples by training two neural networks in opposition, while VAEs focus on learning latent representations and reconstructing data with probabilistic encoding. Knowing their structural and functional differences enables optimized performance and resource allocation in machine learning projects. This knowledge directly impacts innovation in AI-driven technology development and deployment.
Comparison Table
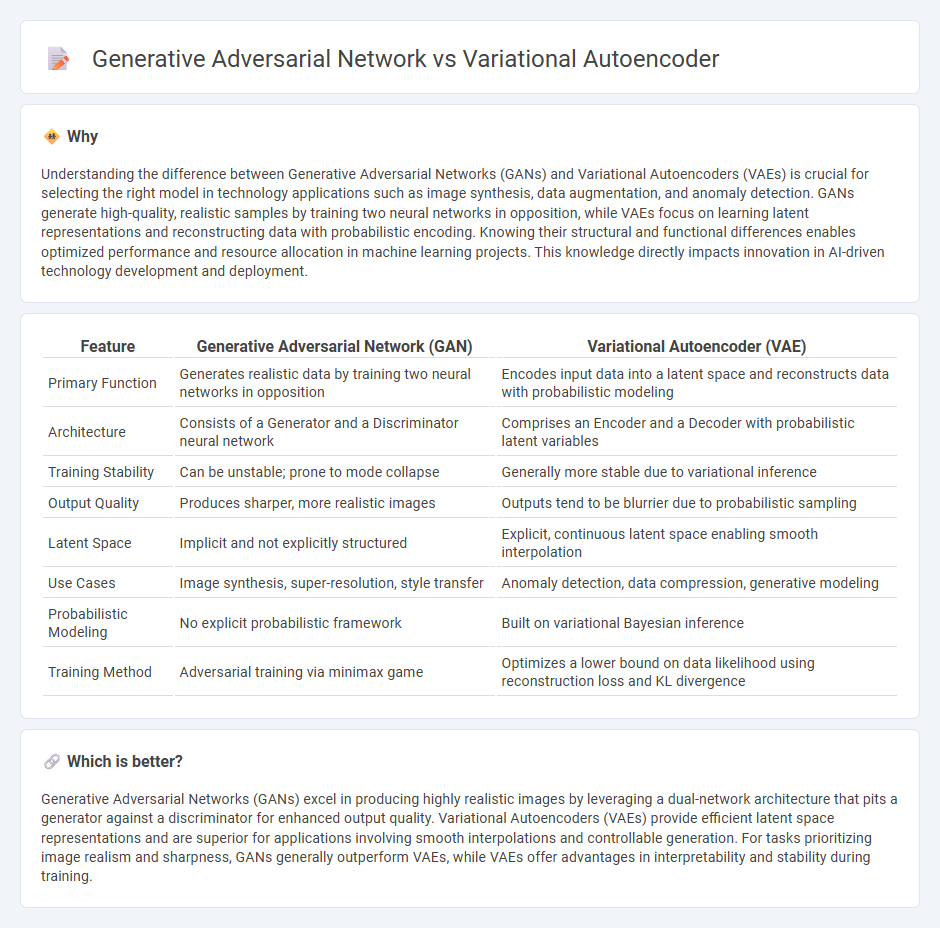
| Feature | Generative Adversarial Network (GAN) | Variational Autoencoder (VAE) |
|---|---|---|
| Primary Function | Generates realistic data by training two neural networks in opposition | Encodes input data into a latent space and reconstructs data with probabilistic modeling |
| Architecture | Consists of a Generator and a Discriminator neural network | Comprises an Encoder and a Decoder with probabilistic latent variables |
| Training Stability | Can be unstable; prone to mode collapse | Generally more stable due to variational inference |
| Output Quality | Produces sharper, more realistic images | Outputs tend to be blurrier due to probabilistic sampling |
| Latent Space | Implicit and not explicitly structured | Explicit, continuous latent space enabling smooth interpolation |
| Use Cases | Image synthesis, super-resolution, style transfer | Anomaly detection, data compression, generative modeling |
| Probabilistic Modeling | No explicit probabilistic framework | Built on variational Bayesian inference |
| Training Method | Adversarial training via minimax game | Optimizes a lower bound on data likelihood using reconstruction loss and KL divergence |
Which is better?
Generative Adversarial Networks (GANs) excel in producing highly realistic images by leveraging a dual-network architecture that pits a generator against a discriminator for enhanced output quality. Variational Autoencoders (VAEs) provide efficient latent space representations and are superior for applications involving smooth interpolations and controllable generation. For tasks prioritizing image realism and sharpness, GANs generally outperform VAEs, while VAEs offer advantages in interpretability and stability during training.
Connection
Generative adversarial networks (GANs) and variational autoencoders (VAEs) are both advanced generative models used in artificial intelligence to create new data samples by learning underlying data distributions. GANs consist of a generator and a discriminator network that compete to improve data generation, while VAEs encode input data into a probabilistic latent space and decode it back to reconstruct the input, optimizing for both reconstruction loss and regularization. Both models address challenges in unsupervised learning and representation learning, often complementing each other in applications like image synthesis and anomaly detection.
Key Terms
Latent Space
Variational Autoencoders (VAEs) encode input data into a continuous, structured latent space defined by mean and variance parameters, enabling smooth interpolation and meaningful representation learning. Generative Adversarial Networks (GANs) utilize a latent space primarily as a random noise vector, focusing on generating high-fidelity samples without explicit encoding of data distributions. Explore the nuances and applications of latent space representations in VAEs and GANs to enhance generative modeling techniques.
Encoder-Decoder
Variational Autoencoders (VAEs) utilize an Encoder-Decoder architecture to learn probabilistic latent representations, allowing for efficient data reconstruction and smooth interpolation in the latent space. In contrast, Generative Adversarial Networks (GANs) typically lack an explicit encoder and rely on a generator and discriminator competing to produce realistic outputs, which can result in sharper images but less structured latent spaces. Explore the technical nuances and training methodologies of these models to better understand their applications and strengths.
Discriminator
The Discriminator in Generative Adversarial Networks (GANs) serves as a binary classifier distinguishing between real and generated data, providing crucial feedback that helps the Generator improve. Variational Autoencoders (VAEs) do not include a Discriminator; instead, they rely on a probabilistic framework optimizing the evidence lower bound (ELBO) to generate data. Explore further to understand how the Discriminator's role influences generative model performance and applications.
Source and External Links
What is a Variational Autoencoder? - Variational autoencoders (VAEs) are generative deep learning models that encode input data into a continuous probabilistic latent space, enabling both accurate reconstruction and generation of new data samples via variational inference and the reparameterization trick.
Variational AutoEncoders - VAEs are generative models that learn a continuous, probabilistic representation of data by encoding inputs into mean and standard deviation vectors, sampling from this range to generate new, realistic data samples.
Variational autoencoder - A VAE is a neural network architecture that maps input data to a probability distribution in a latent space, allowing it to generate new data by decoding from this distribution, and avoids overfitting through probabilistic encoding and the reparameterization trick.