Vector databases excel at managing high-dimensional data such as embeddings from machine learning models, enabling efficient similarity searches and AI-driven applications. Document databases, on the other hand, store semi-structured data in flexible JSON-like formats, optimizing scalability and ease of querying for diverse business use cases. Explore the unique strengths and applications of vector and document databases to leverage the best technology for your data needs.
Why it is important
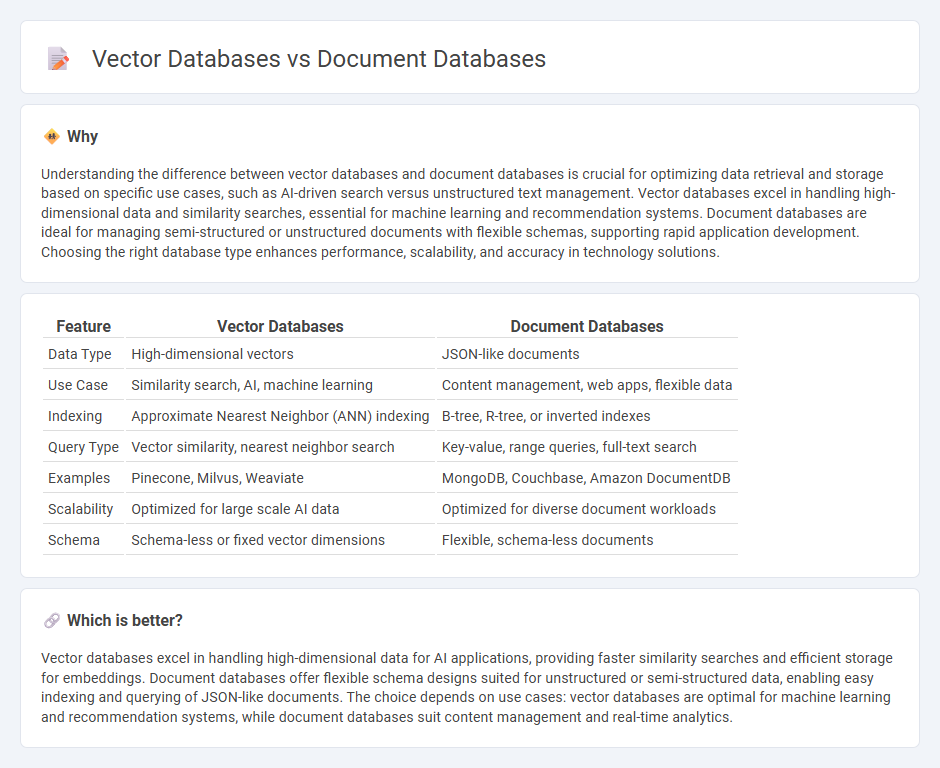
Understanding the difference between vector databases and document databases is crucial for optimizing data retrieval and storage based on specific use cases, such as AI-driven search versus unstructured text management. Vector databases excel in handling high-dimensional data and similarity searches, essential for machine learning and recommendation systems. Document databases are ideal for managing semi-structured or unstructured documents with flexible schemas, supporting rapid application development. Choosing the right database type enhances performance, scalability, and accuracy in technology solutions.
Comparison Table
| Feature | Vector Databases | Document Databases |
|---|---|---|
| Data Type | High-dimensional vectors | JSON-like documents |
| Use Case | Similarity search, AI, machine learning | Content management, web apps, flexible data |
| Indexing | Approximate Nearest Neighbor (ANN) indexing | B-tree, R-tree, or inverted indexes |
| Query Type | Vector similarity, nearest neighbor search | Key-value, range queries, full-text search |
| Examples | Pinecone, Milvus, Weaviate | MongoDB, Couchbase, Amazon DocumentDB |
| Scalability | Optimized for large scale AI data | Optimized for diverse document workloads |
| Schema | Schema-less or fixed vector dimensions | Flexible, schema-less documents |
Which is better?
Vector databases excel in handling high-dimensional data for AI applications, providing faster similarity searches and efficient storage for embeddings. Document databases offer flexible schema designs suited for unstructured or semi-structured data, enabling easy indexing and querying of JSON-like documents. The choice depends on use cases: vector databases are optimal for machine learning and recommendation systems, while document databases suit content management and real-time analytics.
Connection
Vector databases and document databases are connected through their ability to store, manage, and retrieve unstructured data efficiently, with vector databases focusing on embedding vectors for similarity search and document databases organizing text-based documents. Both systems leverage advanced indexing techniques, such as Approximate Nearest Neighbor (ANN) algorithms in vector databases and inverted indexes in document databases, to optimize query performance. This integration enhances applications like natural language processing and recommendation systems by combining semantic search capabilities with rich document metadata.
Key Terms
Schema
Document databases organize data using flexible schemas that store information in JSON-like documents, enabling dynamic and varied data structures. Vector databases primarily focus on managing high-dimensional vector representations, which often lack a traditional schema and prioritize similarity search over structured data organization. Explore more to understand how schema design impacts efficiency and use cases in both database types.
Indexing
Document databases utilize traditional indexing methods such as B-trees and inverted indexes to optimize query performance on structured and semi-structured data like JSON or XML documents. Vector databases implement specialized indexing techniques including approximate nearest neighbor (ANN) algorithms like HNSW or Faiss to efficiently search high-dimensional vector embeddings for similarity and pattern recognition. Explore the distinct indexing mechanisms to understand which database aligns best with your data retrieval needs.
Query Mechanism
Document databases utilize structured query languages like SQL or NoSQL queries to retrieve and index text-based documents effectively, supporting filters on specific document fields and metadata. Vector databases rely on similarity search algorithms and indexing techniques such as Approximate Nearest Neighbor (ANN) to perform fast, high-dimensional vector comparisons for unstructured data like embeddings from machine learning models. Explore the detailed differences in query mechanisms to identify the best solution for your data retrieval needs.
Source and External Links
Document-oriented database - Wikipedia - Document-oriented databases are a type of NoSQL database designed for storing, retrieving, and managing semi-structured data, typically as individual documents with flexible, schema-less structures.
Best Document Databases: User Reviews from July 2025 - G2 - Document databases support fast, flexible data access through features like ad hoc queries, rich indexing, and distributed architecture, making them ideal for handling unstructured or rapidly changing data at scale.
Document Database - NoSQL | MongoDB - A document database stores information in documents (often JSON or XML format), enabling each document to have a unique structure and eliminating the need for a fixed schema, which simplifies development and data evolution.