Biosignal decoding involves interpreting physiological signals such as EEG or EMG to understand neural or muscular activity, enabling advanced applications like brain-computer interfaces and prosthetic control. Speech recognition processes acoustic data to convert spoken language into text, powering virtual assistants and automated transcription services. Explore the nuances of these technologies and their transformative impacts on human-computer interaction.
Why it is important
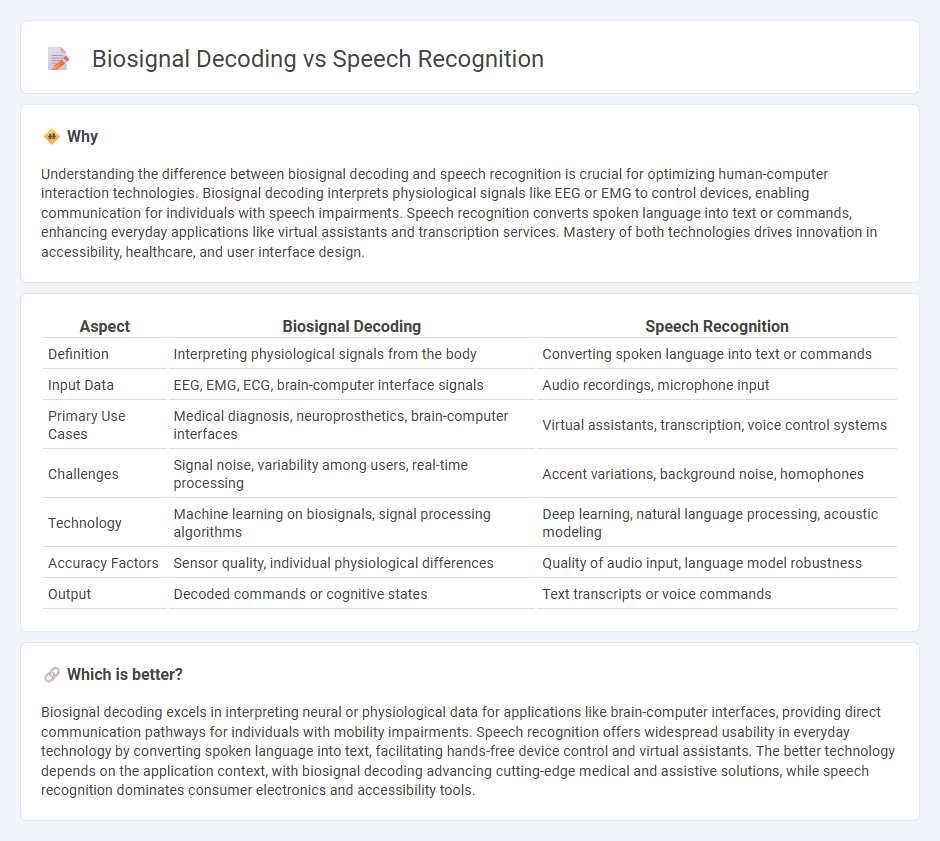
Understanding the difference between biosignal decoding and speech recognition is crucial for optimizing human-computer interaction technologies. Biosignal decoding interprets physiological signals like EEG or EMG to control devices, enabling communication for individuals with speech impairments. Speech recognition converts spoken language into text or commands, enhancing everyday applications like virtual assistants and transcription services. Mastery of both technologies drives innovation in accessibility, healthcare, and user interface design.
Comparison Table
| Aspect | Biosignal Decoding | Speech Recognition |
|---|---|---|
| Definition | Interpreting physiological signals from the body | Converting spoken language into text or commands |
| Input Data | EEG, EMG, ECG, brain-computer interface signals | Audio recordings, microphone input |
| Primary Use Cases | Medical diagnosis, neuroprosthetics, brain-computer interfaces | Virtual assistants, transcription, voice control systems |
| Challenges | Signal noise, variability among users, real-time processing | Accent variations, background noise, homophones |
| Technology | Machine learning on biosignals, signal processing algorithms | Deep learning, natural language processing, acoustic modeling |
| Accuracy Factors | Sensor quality, individual physiological differences | Quality of audio input, language model robustness |
| Output | Decoded commands or cognitive states | Text transcripts or voice commands |
Which is better?
Biosignal decoding excels in interpreting neural or physiological data for applications like brain-computer interfaces, providing direct communication pathways for individuals with mobility impairments. Speech recognition offers widespread usability in everyday technology by converting spoken language into text, facilitating hands-free device control and virtual assistants. The better technology depends on the application context, with biosignal decoding advancing cutting-edge medical and assistive solutions, while speech recognition dominates consumer electronics and accessibility tools.
Connection
Biosignal decoding translates neural and physiological signals into digital data, enabling devices to interpret human intentions and actions. Speech recognition relies on decoding vocal biosignals, such as electromyographic or brain signals, to identify spoken words and convert them into text or commands. Integrating biosignal decoding with speech recognition enhances communication technologies for individuals with speech impairments or in noisy environments.
Key Terms
Acoustic Modeling (Speech Recognition)
Acoustic modeling in speech recognition involves transforming audio signals into phonetic units using algorithms like Hidden Markov Models (HMM) or deep neural networks, which capture temporal and spectral features of speech. In contrast, biosignal decoding often processes physiological signals such as EEG or EMG to interpret neural or muscular activity patterns rather than acoustic data. Explore how acoustic modeling advances the accuracy of speech recognition systems and its applications in real-world scenarios.
Electrophysiological Signals (Biosignal Decoding)
Electrophysiological signals, such as EEG, EMG, and ECG, play a critical role in biosignal decoding by capturing neural and muscular activity for applications like brain-computer interfaces and medical diagnostics. Speech recognition relies primarily on acoustic signal processing to convert spoken language into text, whereas biosignal decoding interprets complex physiological patterns to understand intent or detect abnormalities. Explore the latest advancements in electrophysiological signal processing to unlock new potentials in human-machine interaction and healthcare monitoring.
Feature Extraction
Feature extraction in speech recognition primarily involves isolating acoustic features such as Mel-Frequency Cepstral Coefficients (MFCCs) or spectrograms to capture phonetic information and improve transcription accuracy. In biosignal decoding, feature extraction targets physiological signals like EEG, EMG, or ECG, extracting time-frequency patterns, waveform morphology, or statistical metrics to interpret neural activity or muscle response. Explore more about advanced feature extraction techniques and their impact on system performance.
Source and External Links
Speech Recognition - Wikipedia - Speech recognition, also known as automatic speech recognition, is a technology that converts spoken language into text using computer algorithms and machine learning models.
Speech Recognition | Definition from TechTarget - Speech recognition is a capability that allows machines to identify spoken words and convert them into readable text, often used in voice user interfaces and text-focused applications.
Speech-to-Text AI: speech recognition and transcription - This Google Cloud service uses AI to convert audio into text transcriptions, supporting extensive language options and optimized for various transcription needs.