Retrieval Augmented Generation (RAG) integrates external knowledge bases to enhance language models' accuracy beyond their fixed training data, while Context Window Expansion increases the input size to capture more contextual information during generation. RAG relies on dynamic data retrieval to improve responses, whereas context window techniques focus on extending the model's memory span for better coherence. Explore these innovative AI methods to understand how they transform natural language understanding and generation.
Why it is important
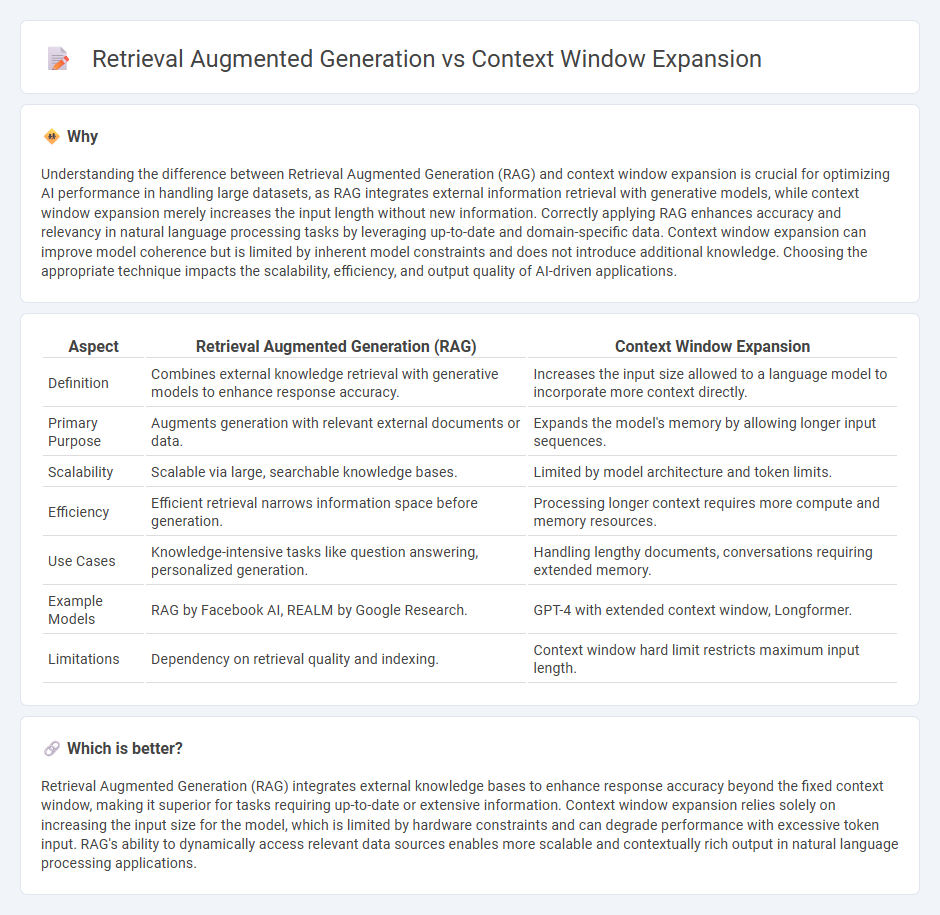
Understanding the difference between Retrieval Augmented Generation (RAG) and context window expansion is crucial for optimizing AI performance in handling large datasets, as RAG integrates external information retrieval with generative models, while context window expansion merely increases the input length without new information. Correctly applying RAG enhances accuracy and relevancy in natural language processing tasks by leveraging up-to-date and domain-specific data. Context window expansion can improve model coherence but is limited by inherent model constraints and does not introduce additional knowledge. Choosing the appropriate technique impacts the scalability, efficiency, and output quality of AI-driven applications.
Comparison Table
| Aspect | Retrieval Augmented Generation (RAG) | Context Window Expansion |
|---|---|---|
| Definition | Combines external knowledge retrieval with generative models to enhance response accuracy. | Increases the input size allowed to a language model to incorporate more context directly. |
| Primary Purpose | Augments generation with relevant external documents or data. | Expands the model's memory by allowing longer input sequences. |
| Scalability | Scalable via large, searchable knowledge bases. | Limited by model architecture and token limits. |
| Efficiency | Efficient retrieval narrows information space before generation. | Processing longer context requires more compute and memory resources. |
| Use Cases | Knowledge-intensive tasks like question answering, personalized generation. | Handling lengthy documents, conversations requiring extended memory. |
| Example Models | RAG by Facebook AI, REALM by Google Research. | GPT-4 with extended context window, Longformer. |
| Limitations | Dependency on retrieval quality and indexing. | Context window hard limit restricts maximum input length. |
Which is better?
Retrieval Augmented Generation (RAG) integrates external knowledge bases to enhance response accuracy beyond the fixed context window, making it superior for tasks requiring up-to-date or extensive information. Context window expansion relies solely on increasing the input size for the model, which is limited by hardware constraints and can degrade performance with excessive token input. RAG's ability to dynamically access relevant data sources enables more scalable and contextually rich output in natural language processing applications.
Connection
Retrieval-augmented generation (RAG) enhances language models by integrating external knowledge sources, effectively expanding the context window beyond the model's fixed input limits. By retrieving relevant documents or data, RAG supplements the context window with richer information, improving the accuracy and relevance of generated responses. This synergy allows models to handle larger and more dynamic knowledge bases without being constrained by token limits.
Key Terms
Token Limit
Context window expansion increases the number of tokens a model processes directly, allowing for larger inputs but often constrained by hardware and model architecture limitations. Retrieval augmented generation (RAG) complements this by dynamically fetching relevant external data, circumventing the strict token limits of the model's context window while enhancing response accuracy. Explore how combining these approaches can optimize token utilization and improve language model performance.
Vector Database
Context window expansion enhances language model performance by increasing the amount of directly accessible input text, allowing for more extensive contextual understanding within a single query. Retrieval Augmented Generation (RAG) leverages vector databases to dynamically fetch relevant external documents, integrating them into the generation process for up-to-date and scalable information retrieval. Explore how vector databases optimize these methods to revolutionize natural language processing and improve response accuracy.
Embedding
Context window expansion allows large language models to process more tokens simultaneously, enhancing understanding by increasing the amount of text embedded and analyzed in one pass, while retrieval-augmented generation (RAG) leverages external databases where embeddings of documents are compared to query embeddings to dynamically retrieve relevant information that supplements the model's limited context window. Embedding quality directly impacts both methods: richer, semantically meaningful embeddings improve the relevance of retrieved documents in RAG and the representation of extended context in window expansion, optimizing response accuracy and depth. Explore the latest advancements in embedding techniques to better understand how they transform language model capabilities.
Source and External Links
Understanding the Impact of Increasing LLM Context Windows - Expanding the context window allows models to process entire books, maintain long conversation histories, and improve reasoning with cached documents, but it comes with technical and computational challenges.
What is a context window? - IBM - A larger context window lets models remember and use more information in a single session, leading to better accuracy, coherence, and ability to handle longer documents, but increases compute costs and potential vulnerabilities.
Massive Context Windows Are Here - Hype or Game-changer? - Enormous context windows enable processing of large texts and datasets, but introduce major challenges in cost, performance, and information extraction, with models sometimes struggling to use information from the middle of large contexts.