Synthetic data and simulated data both play crucial roles in technology by enhancing machine learning and testing environments. Synthetic data is artificially generated to mimic real-world data patterns, while simulated data is produced through models that replicate specific processes or systems. Explore the differences and applications of synthetic versus simulated data to optimize your tech solutions.
Why it is important
Understanding the difference between synthetic data and simulated data is crucial for developing accurate machine learning models and ensuring data privacy. Synthetic data is artificially generated based on real data patterns, preserving privacy while maintaining statistical relevance. Simulated data replicates real-world processes or scenarios through computational models to predict system behaviors. Proper distinction ensures effective application in fields like AI training, healthcare, and autonomous systems.
Comparison Table
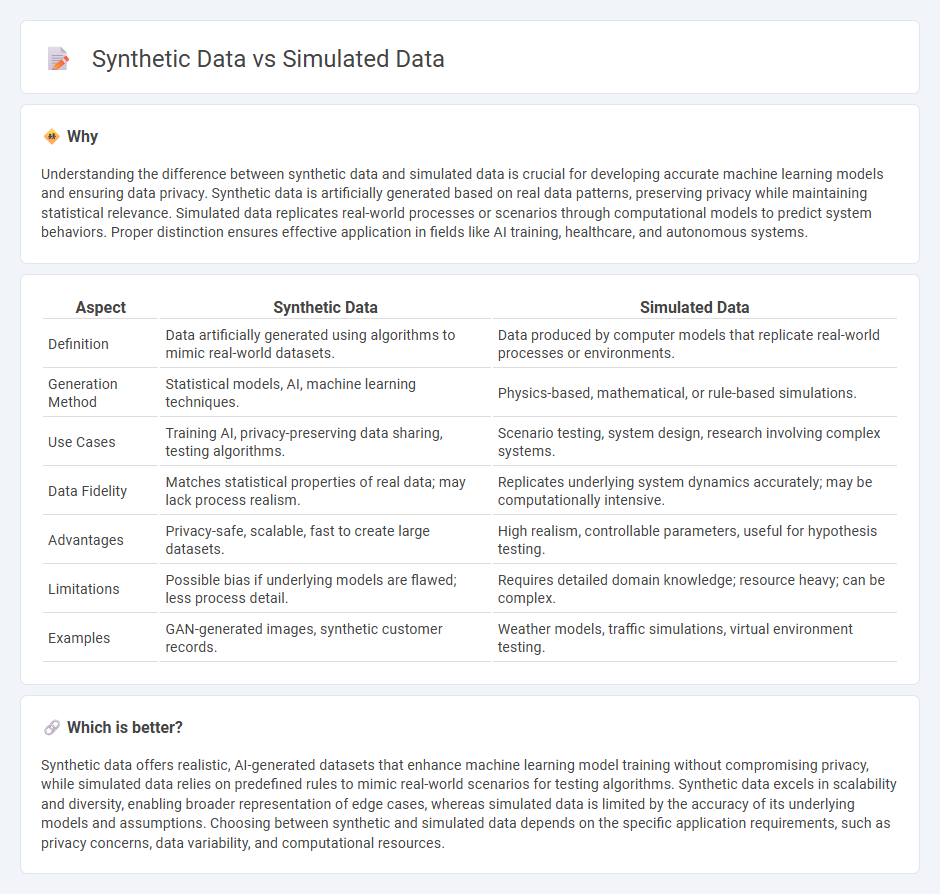
| Aspect | Synthetic Data | Simulated Data |
|---|---|---|
| Definition | Data artificially generated using algorithms to mimic real-world datasets. | Data produced by computer models that replicate real-world processes or environments. |
| Generation Method | Statistical models, AI, machine learning techniques. | Physics-based, mathematical, or rule-based simulations. |
| Use Cases | Training AI, privacy-preserving data sharing, testing algorithms. | Scenario testing, system design, research involving complex systems. |
| Data Fidelity | Matches statistical properties of real data; may lack process realism. | Replicates underlying system dynamics accurately; may be computationally intensive. |
| Advantages | Privacy-safe, scalable, fast to create large datasets. | High realism, controllable parameters, useful for hypothesis testing. |
| Limitations | Possible bias if underlying models are flawed; less process detail. | Requires detailed domain knowledge; resource heavy; can be complex. |
| Examples | GAN-generated images, synthetic customer records. | Weather models, traffic simulations, virtual environment testing. |
Which is better?
Synthetic data offers realistic, AI-generated datasets that enhance machine learning model training without compromising privacy, while simulated data relies on predefined rules to mimic real-world scenarios for testing algorithms. Synthetic data excels in scalability and diversity, enabling broader representation of edge cases, whereas simulated data is limited by the accuracy of its underlying models and assumptions. Choosing between synthetic and simulated data depends on the specific application requirements, such as privacy concerns, data variability, and computational resources.
Connection
Synthetic data and simulated data are intrinsically connected through their generation processes aimed at replicating real-world information without using actual datasets. Synthetic data is often produced using simulation techniques, enabling the creation of realistic, yet artificial, datasets for machine learning and AI model training. Both types serve crucial roles in enhancing data privacy, augmenting scarce data, and improving the robustness of algorithms in various technological applications.
Key Terms
Realism
Simulated data replicates real-world processes through computational models, often prioritizing accuracy and adherence to physical laws, whereas synthetic data is algorithmically generated to mimic statistical properties without strict grounding in real phenomena. Realism in simulated data is typically higher due to its basis in actual system behaviors, making it valuable for applications requiring faithful environmental representation. Explore detailed comparisons and use cases to understand the practical implications of each approach.
Generation Method
Simulated data is generated using computational models that mimic real-world processes based on established physical or mathematical principles, often requiring detailed domain knowledge. Synthetic data, however, is created through algorithmic approaches such as generative adversarial networks (GANs) or variational autoencoders (VAEs), focusing on replicating statistical properties without necessarily modeling underlying mechanisms. Explore the distinct advantages of each approach to optimize your data generation strategy.
Use Case
Simulated data replicates real-world processes using mathematical models, commonly applied in engineering and scientific research to test hypotheses and optimize systems. Synthetic data is artificially generated to mimic the statistical properties of real data sets, widely used in machine learning training, privacy preservation, and software testing. Explore detailed use cases to understand how simulated and synthetic data can drive innovation and improve data-driven decisions.
Source and External Links
What Is Data Simulation? | Benefits & Modeling - Datamation - Data simulation is the process of generating synthetic data that closely mimics real-world data, enabling cost-effective, flexible, and scalable testing and validation of analytics systems without the ethical and legal concerns of using real user data.
Data simulation: unlocking innovation & empowering organizations - Data simulation creates datasets with specified characteristics that imitate real data patterns, distributions, and correlations, allowing organizations to test algorithms, analyze behaviors, and improve fraud detection and customer engagement strategies in controlled environments.
Creating simulated data sets in R - Simulated data in R can be generated using functions like rnorm, runif, rbinom, and rpois, providing researchers with tools to explore statistical methods, plan experiments, and understand data visualization and analysis.