Synthetic data is artificially generated information that mimics real datasets without containing any actual personal details, enabling robust machine learning model training while preserving privacy. Anonymized data involves modifying real datasets to remove or obscure personally identifiable information, reducing re-identification risks but sometimes limiting analytical accuracy. Explore the key differences and applications of synthetic versus anonymized data to understand their impact on privacy and data utility.
Why it is important
Understanding the difference between synthetic data and anonymized data is crucial for ensuring privacy compliance and data accuracy in technology applications. Synthetic data is artificially generated to mimic real datasets without exposing personal information, whereas anonymized data is actual data stripped of identifiers to protect individual privacy. This distinction impacts data security strategies, machine learning model training, and regulatory adherence under laws like GDPR and CCPA. Choosing the correct type of data optimizes performance while minimizing risks of data breaches and legal penalties.
Comparison Table
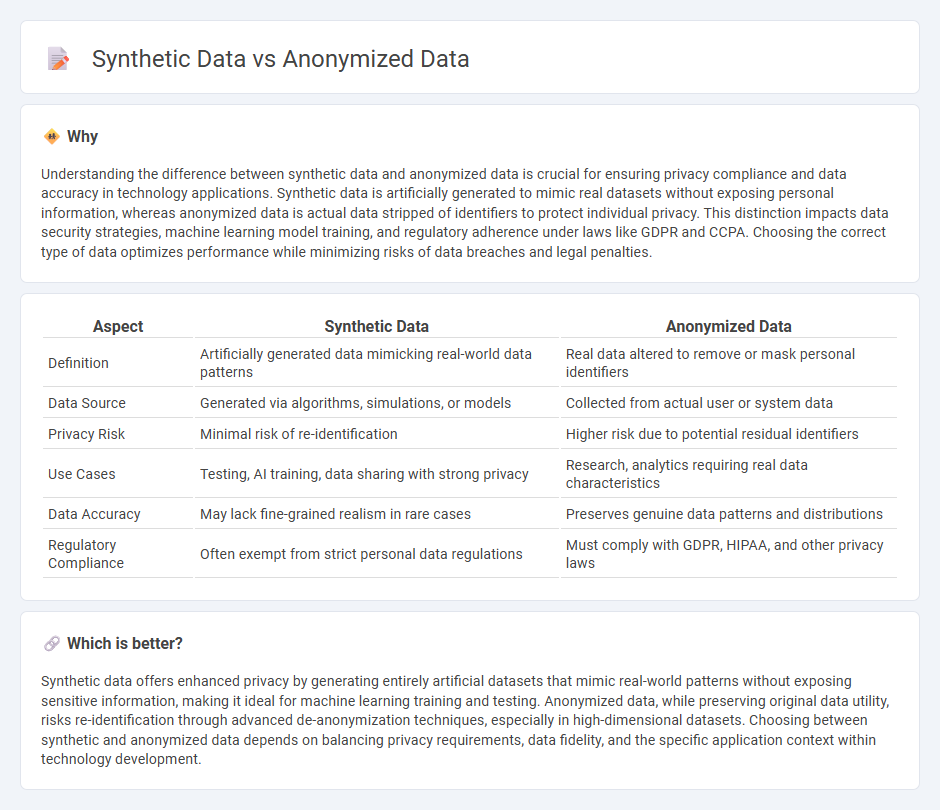
| Aspect | Synthetic Data | Anonymized Data |
|---|---|---|
| Definition | Artificially generated data mimicking real-world data patterns | Real data altered to remove or mask personal identifiers |
| Data Source | Generated via algorithms, simulations, or models | Collected from actual user or system data |
| Privacy Risk | Minimal risk of re-identification | Higher risk due to potential residual identifiers |
| Use Cases | Testing, AI training, data sharing with strong privacy | Research, analytics requiring real data characteristics |
| Data Accuracy | May lack fine-grained realism in rare cases | Preserves genuine data patterns and distributions |
| Regulatory Compliance | Often exempt from strict personal data regulations | Must comply with GDPR, HIPAA, and other privacy laws |
Which is better?
Synthetic data offers enhanced privacy by generating entirely artificial datasets that mimic real-world patterns without exposing sensitive information, making it ideal for machine learning training and testing. Anonymized data, while preserving original data utility, risks re-identification through advanced de-anonymization techniques, especially in high-dimensional datasets. Choosing between synthetic and anonymized data depends on balancing privacy requirements, data fidelity, and the specific application context within technology development.
Connection
Synthetic data and anonymized data both serve to protect user privacy by minimizing the exposure of real personal information in technology applications. Synthetic data is artificially generated to mimic the statistical properties of real datasets without containing actual user data, while anonymized data involves removing or masking personally identifiable information from real datasets. Both methods enhance data security and compliance with privacy regulations in machine learning, data analysis, and AI model training.
Key Terms
De-identification
Anonymized data involves removing or masking personal identifiers to ensure individuals cannot be re-identified, providing strong privacy protection for sensitive datasets. Synthetic data is artificially generated, simulating real data patterns without containing any actual personal information, which enhances data utility while maintaining privacy. Explore how de-identification techniques affect data privacy and utility to understand the best approach for your needs.
Data Generation
Anonymized data is derived by masking or removing personally identifiable information from real datasets to protect privacy while retaining data authenticity. Synthetic data is artificially generated using algorithms and models to simulate realistic data patterns without relying on any actual individual's information. Explore how both approaches impact data generation techniques and their applications in privacy-preserving analytics.
Privacy
Anonymized data undergoes processes to remove or mask personal identifiers, reducing privacy risks but remaining vulnerable to re-identification through data linkage. Synthetic data is artificially generated to mimic real datasets without containing any actual personal information, offering stronger privacy protection by eliminating direct ties to individuals. Explore deeper insights into how these methods impact privacy safeguards and data utility.
Source and External Links
Anonymized Data Definition, Explanation & Examples - Anonymized data is created by removing personally identifiable information, allowing analysis without exposing individual identities.
What Are the Top Data Anonymization Techniques? - Common anonymization techniques include data masking, pseudonymization, k-anonymization, encryption, and differential privacy to protect sensitive information.
What is Data Anonymization? A Practical Guide - Data anonymization procedures include data masking (replacing real values with fictional ones), pseudonymization (replacing identifiers with artificial substitutes), and synthetic data generation.