Vector databases store and manage high-dimensional data as vectors, enabling efficient similarity searches for applications like image recognition and natural language processing. Search engines index and retrieve documents based on keyword matching and relevance algorithms, optimized for broad text-based queries. Explore the differences to discover how each technology enhances modern data retrieval.
Why it is important
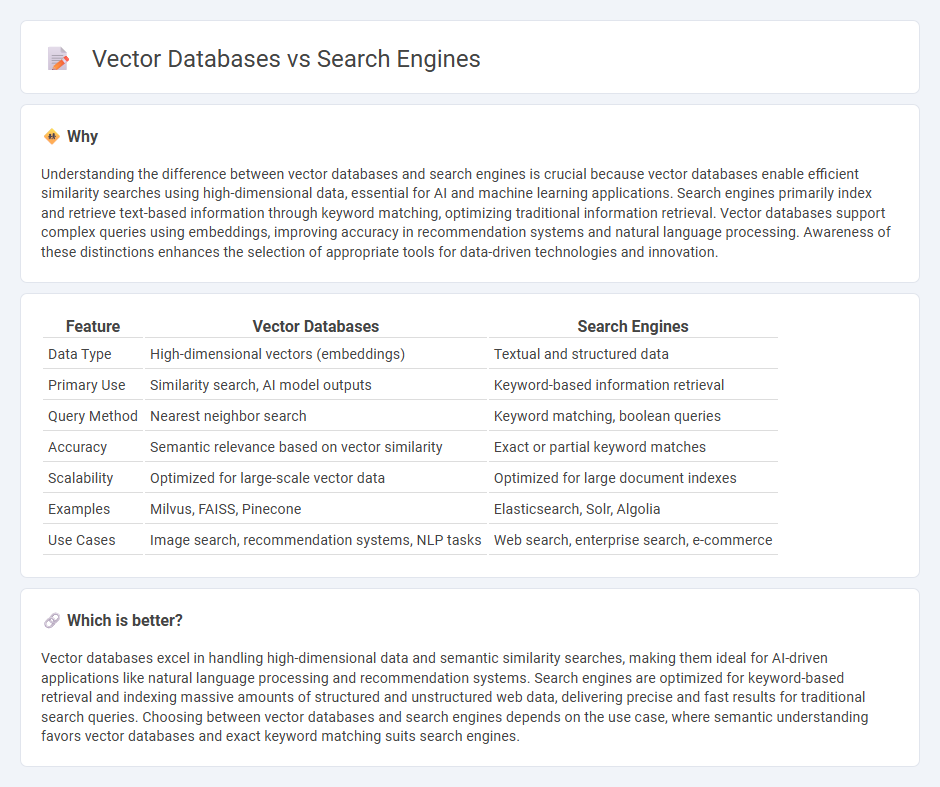
Understanding the difference between vector databases and search engines is crucial because vector databases enable efficient similarity searches using high-dimensional data, essential for AI and machine learning applications. Search engines primarily index and retrieve text-based information through keyword matching, optimizing traditional information retrieval. Vector databases support complex queries using embeddings, improving accuracy in recommendation systems and natural language processing. Awareness of these distinctions enhances the selection of appropriate tools for data-driven technologies and innovation.
Comparison Table
| Feature | Vector Databases | Search Engines |
|---|---|---|
| Data Type | High-dimensional vectors (embeddings) | Textual and structured data |
| Primary Use | Similarity search, AI model outputs | Keyword-based information retrieval |
| Query Method | Nearest neighbor search | Keyword matching, boolean queries |
| Accuracy | Semantic relevance based on vector similarity | Exact or partial keyword matches |
| Scalability | Optimized for large-scale vector data | Optimized for large document indexes |
| Examples | Milvus, FAISS, Pinecone | Elasticsearch, Solr, Algolia |
| Use Cases | Image search, recommendation systems, NLP tasks | Web search, enterprise search, e-commerce |
Which is better?
Vector databases excel in handling high-dimensional data and semantic similarity searches, making them ideal for AI-driven applications like natural language processing and recommendation systems. Search engines are optimized for keyword-based retrieval and indexing massive amounts of structured and unstructured web data, delivering precise and fast results for traditional search queries. Choosing between vector databases and search engines depends on the use case, where semantic understanding favors vector databases and exact keyword matching suits search engines.
Connection
Vector databases store high-dimensional vectors representing data features, enabling efficient similarity searches essential for modern search engines. Search engines leverage vector databases to improve relevance by matching user queries with semantically similar content using embeddings from machine learning models. This integration enhances information retrieval accuracy and supports advanced applications like natural language processing and personalized recommendations.
Key Terms
Indexing
Search engines utilize inverted indexes to efficiently map keywords to document locations, enabling rapid text retrieval across vast datasets. Vector databases employ specialized indexing structures like HNSW or IVF to handle high-dimensional vector representations, optimizing similarity searches for AI-driven applications. Explore the technical nuances of these indexing methods to enhance your data retrieval strategies.
Relevance Ranking
Search engines use keyword-based relevance ranking algorithms like TF-IDF and BM25 to match queries with indexed documents, focusing on exact term frequency and proximity for results accuracy. Vector databases employ dense vector embeddings and cosine similarity or approximate nearest neighbor search to capture semantic meaning for relevance ranking, enhancing retrieval of contextually related information. Explore further to understand how these approaches optimize information retrieval performance.
Embeddings
Search engines rely on keyword matching and traditional indexing methods to retrieve relevant documents, while vector databases leverage embeddings to represent semantic content as high-dimensional vectors, enabling more accurate similarity searches. Embeddings capture contextual meaning from text, images, or other data, allowing vector databases to identify relationships and patterns beyond exact keyword matches. Explore how embeddings transform data retrieval by diving deeper into the capabilities of vector databases.
Source and External Links
Search Engines & SEO: 34 Most Popular Search Engines in 2025 - Search engines work through three core processes: crawling, indexing, and ranking to deliver the most relevant web pages to users, with popular examples including Google, Bing, Yahoo, and DuckDuckGo.
In-Depth Guide to How Google Search Works | Documentation - Google Search is an automated system that uses web crawlers to discover and index web pages, then serves results based on relevance to user queries, without accepting payment for ranking boosts.
List of search engines - Wikipedia - There are many types of search engines besides web search, including those specialized in maps, multimedia, shopping, blogs, and other data types, highlighting the diversity of search tools available.