Vector databases store and manage high-dimensional data representations essential for applications like machine learning, image recognition, and natural language processing, enabling efficient similarity searches using vector embeddings. Search engines index and retrieve text-based information from vast web sources, utilizing keyword matching, ranking algorithms, and user intent analysis to deliver relevant results quickly. Discover how vector databases and search engines differ in handling data to enhance your technology strategy.
Why it is important
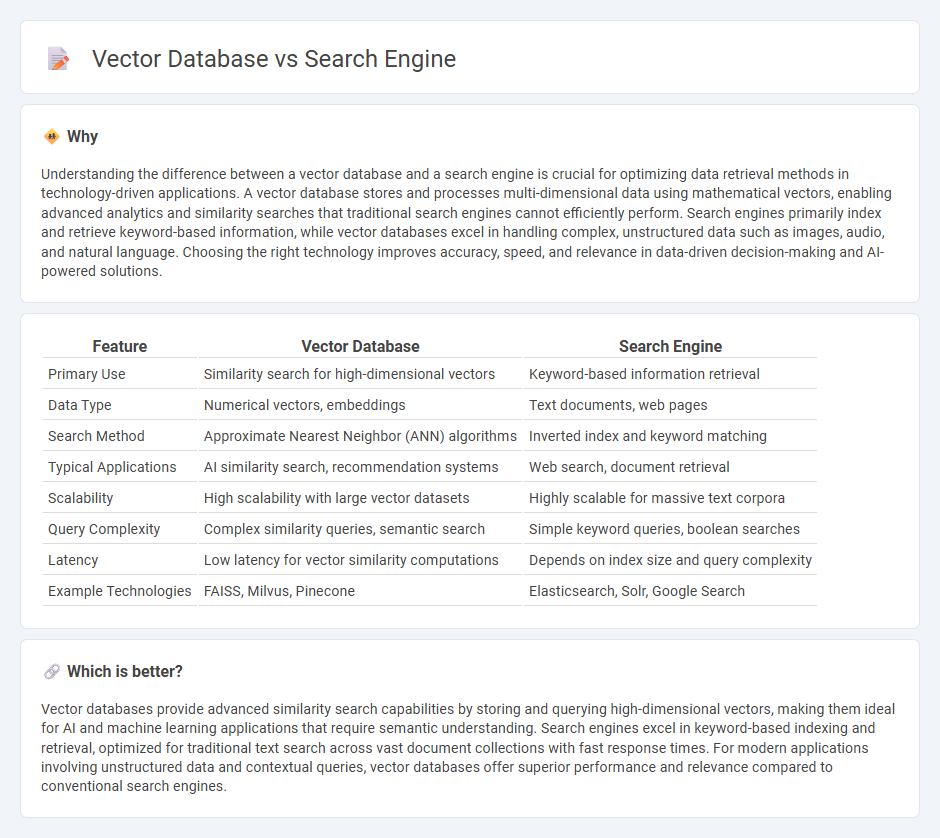
Understanding the difference between a vector database and a search engine is crucial for optimizing data retrieval methods in technology-driven applications. A vector database stores and processes multi-dimensional data using mathematical vectors, enabling advanced analytics and similarity searches that traditional search engines cannot efficiently perform. Search engines primarily index and retrieve keyword-based information, while vector databases excel in handling complex, unstructured data such as images, audio, and natural language. Choosing the right technology improves accuracy, speed, and relevance in data-driven decision-making and AI-powered solutions.
Comparison Table
| Feature | Vector Database | Search Engine |
|---|---|---|
| Primary Use | Similarity search for high-dimensional vectors | Keyword-based information retrieval |
| Data Type | Numerical vectors, embeddings | Text documents, web pages |
| Search Method | Approximate Nearest Neighbor (ANN) algorithms | Inverted index and keyword matching |
| Typical Applications | AI similarity search, recommendation systems | Web search, document retrieval |
| Scalability | High scalability with large vector datasets | Highly scalable for massive text corpora |
| Query Complexity | Complex similarity queries, semantic search | Simple keyword queries, boolean searches |
| Latency | Low latency for vector similarity computations | Depends on index size and query complexity |
| Example Technologies | FAISS, Milvus, Pinecone | Elasticsearch, Solr, Google Search |
Which is better?
Vector databases provide advanced similarity search capabilities by storing and querying high-dimensional vectors, making them ideal for AI and machine learning applications that require semantic understanding. Search engines excel in keyword-based indexing and retrieval, optimized for traditional text search across vast document collections with fast response times. For modern applications involving unstructured data and contextual queries, vector databases offer superior performance and relevance compared to conventional search engines.
Connection
Vector databases store high-dimensional vector representations of data, enabling efficient similarity search crucial for machine learning and AI applications. Search engines leverage these vector embeddings to improve semantic search accuracy by matching user queries with relevant content beyond keyword matching. This integration enhances information retrieval by understanding context and meaning at scale.
Key Terms
Indexing
Search engines utilize inverted indexing to enable rapid keyword lookups by mapping terms to their document occurrences, optimizing for exact match queries within large text corpora. Vector databases employ dense vector indexing methods such as HNSW or IVF to efficiently handle high-dimensional embeddings, enhancing semantic search and similarity retrieval accuracy. Explore further to understand how these indexing techniques impact search performance and application suitability.
Query Processing
Search engines process queries primarily through keyword matching and inverted indexing, enabling fast retrieval of relevant documents based on term frequency and relevance scores. Vector databases utilize embeddings and similarity measures like cosine or Euclidean distance to perform approximate nearest neighbor searches in high-dimensional spaces, enhancing semantic understanding and retrieval accuracy. Explore deeper insights into the differences in query processing techniques between search engines and vector databases.
Data Retrieval
Search engines utilize keyword indexing and Boolean logic to fetch relevant documents rapidly, making them effective for traditional text-based queries. Vector databases enhance data retrieval by leveraging high-dimensional vector embeddings to capture semantic relationships, enabling more accurate results for unstructured data like images, audio, and natural language. Explore further to understand how these technologies transform information access in various applications.
Source and External Links
Search engine - Wikipedia - A search engine is a software system that provides hyperlinks to web pages and other relevant information on the Web in response to a user's query, using complex indexing and automated web crawlers to deliver fast, accurate results.
Search Engines & SEO: 34 Most Popular Search Engines in 2025 - Search engines work through three main processes: crawling to discover web pages, indexing to store and organize content, and ranking to serve the most relevant results for each query.
DuckDuckGo - Protection. Privacy. Peace of mind. - DuckDuckGo is a privacy-focused search engine that does not track users' searches or browsing history, offering an alternative to Google with similar features but greater emphasis on user control and anonymity.