Synthetic data is artificially generated information created using algorithms and simulations, designed to replicate real-world data patterns without exposing sensitive details. Real data consists of information collected from actual events or observations, reflecting true occurrences and inherent variability. Explore the nuances between synthetic and real data to enhance your understanding of their applications and implications in technology.
Why it is important
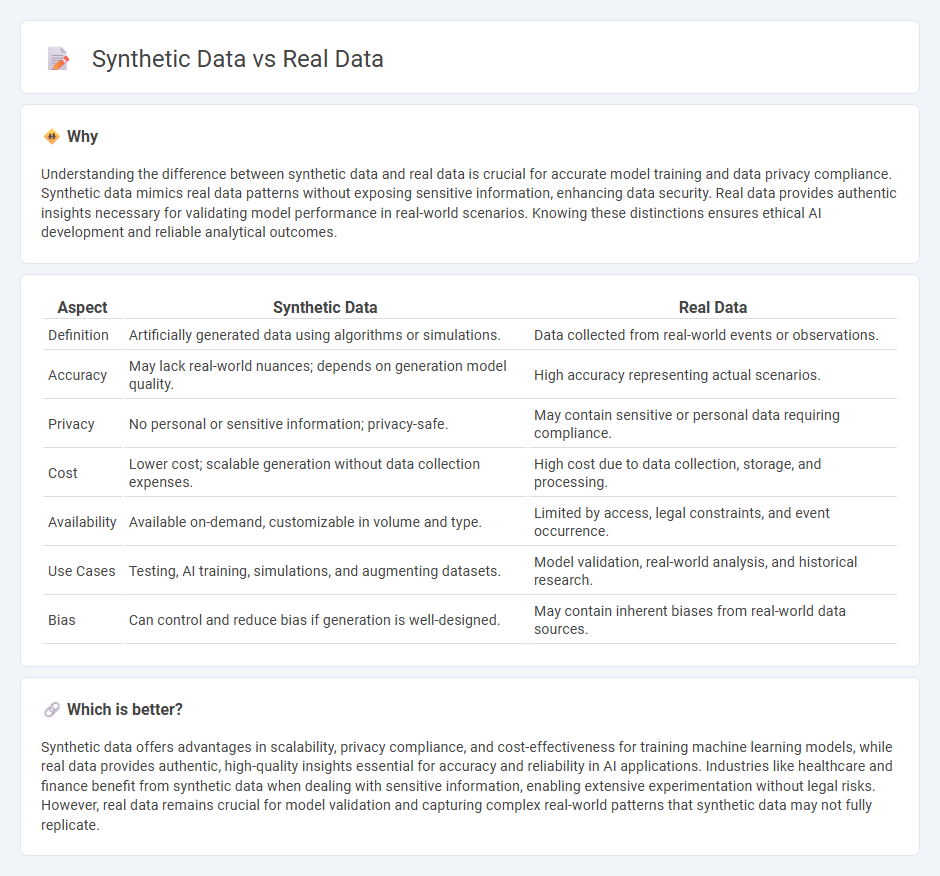
Understanding the difference between synthetic data and real data is crucial for accurate model training and data privacy compliance. Synthetic data mimics real data patterns without exposing sensitive information, enhancing data security. Real data provides authentic insights necessary for validating model performance in real-world scenarios. Knowing these distinctions ensures ethical AI development and reliable analytical outcomes.
Comparison Table
| Aspect | Synthetic Data | Real Data |
|---|---|---|
| Definition | Artificially generated data using algorithms or simulations. | Data collected from real-world events or observations. |
| Accuracy | May lack real-world nuances; depends on generation model quality. | High accuracy representing actual scenarios. |
| Privacy | No personal or sensitive information; privacy-safe. | May contain sensitive or personal data requiring compliance. |
| Cost | Lower cost; scalable generation without data collection expenses. | High cost due to data collection, storage, and processing. |
| Availability | Available on-demand, customizable in volume and type. | Limited by access, legal constraints, and event occurrence. |
| Use Cases | Testing, AI training, simulations, and augmenting datasets. | Model validation, real-world analysis, and historical research. |
| Bias | Can control and reduce bias if generation is well-designed. | May contain inherent biases from real-world data sources. |
Which is better?
Synthetic data offers advantages in scalability, privacy compliance, and cost-effectiveness for training machine learning models, while real data provides authentic, high-quality insights essential for accuracy and reliability in AI applications. Industries like healthcare and finance benefit from synthetic data when dealing with sensitive information, enabling extensive experimentation without legal risks. However, real data remains crucial for model validation and capturing complex real-world patterns that synthetic data may not fully replicate.
Connection
Synthetic data complements real data by enhancing machine learning models where real data is limited or sensitive, generating diverse and balanced datasets that improve algorithm accuracy. It replicates the statistical properties and patterns of real data without exposing personal information, ensuring privacy compliance in data-driven applications. Integrating synthetic data with real data enables robust training environments, accelerating innovation in AI and predictive analytics.
Key Terms
Authenticity
Real data offers unmatched authenticity as it is collected from actual events and human behavior, ensuring high reliability for training accurate machine learning models. Synthetic data, generated algorithmically, often lacks the nuanced patterns found in real-world scenarios, which can limit its effectiveness in applications requiring genuine data variability. Explore more to understand the critical impact of data authenticity on AI model performance.
Generation
Real data consists of authentic information collected from actual events or observations, offering high fidelity but limited by privacy and availability constraints. Synthetic data is artificially generated using algorithms or models like GANs and variational autoencoders, enabling scalability and customization with reduced privacy risks. Explore deeper insights on data generation techniques and their impacts on machine learning models.
Bias
Real data reflects authentic patterns but often contains inherent biases from human behavior, sampling, or collection methods, which can skew machine learning outcomes. Synthetic data, generated through algorithms, allows for controlled manipulation of bias, potentially reducing unfairness but may introduce artificial artifacts not present in real-world scenarios. Explore how balancing bias in real and synthetic data can improve model fairness and accuracy in your applications.
Source and External Links
Real Data - Provides real estate data analysis and statistical reporting across multiple markets, using advanced machine learning and manual number crunching to create informative reports for realtors and consumers.
Real Data Type - A data type used to represent an approximation of real numbers in computer programs, often utilizing rational, fixed-point, floating-point, or decimal number systems.
REaL Data - Captures information on patients' race, ethnicity, and language preferences to enhance culturally competent care and address healthcare disparities.