Edge inference processes data locally on hardware near the data source, reducing latency and improving real-time decision-making for IoT devices and autonomous systems. On-device inference executes AI models directly on mobile or embedded devices, enhancing privacy and minimizing dependence on cloud connectivity. Explore the advantages and applications of edge inference versus on-device inference to optimize your technology strategy.
Why it is important
Understanding the difference between edge inference and on-device inference is crucial for optimizing AI deployment, as edge inference processes data near the source on local edge servers, while on-device inference executes directly on the device hardware like smartphones. Edge inference enables faster processing and reduced latency by minimizing data transfer to central servers, benefiting applications requiring real-time analytics such as autonomous vehicles and industrial IoT. On-device inference enhances privacy and offline functionality by performing computations without cloud dependency, ideal for personal devices and healthcare monitoring. Choosing the appropriate inference method impacts system efficiency, security, and user experience in technology ecosystems.
Comparison Table
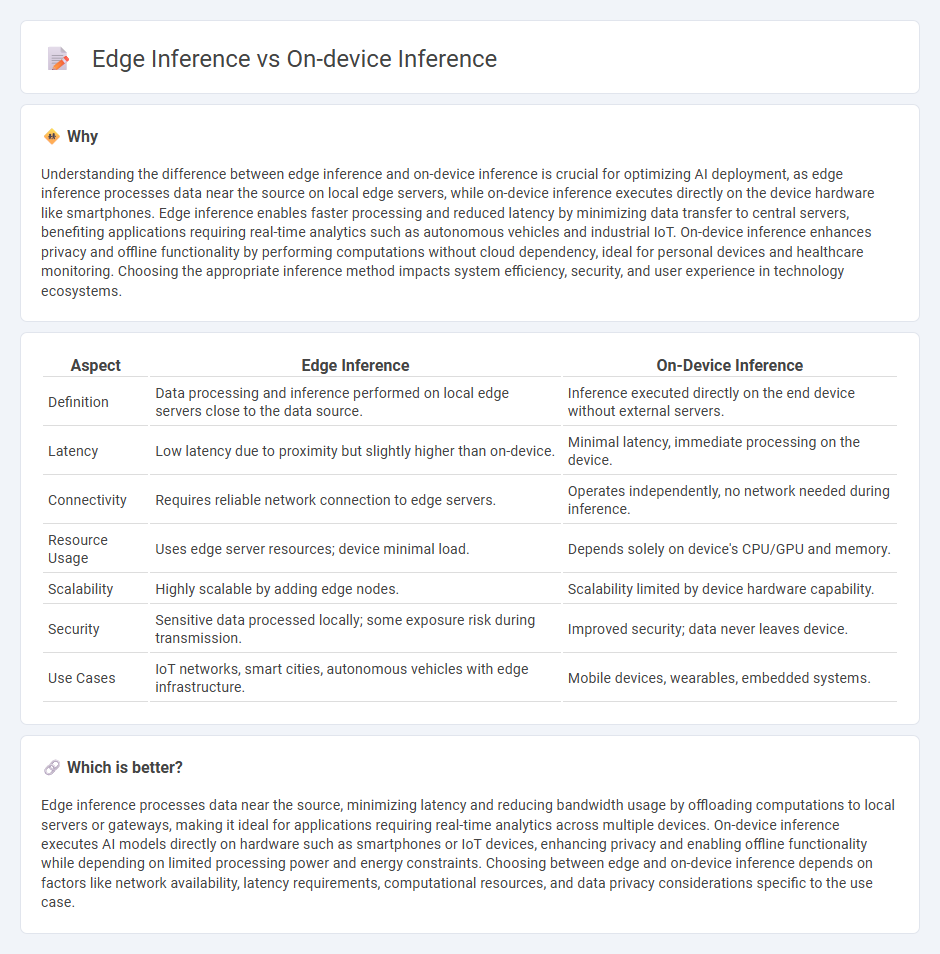
| Aspect | Edge Inference | On-Device Inference |
|---|---|---|
| Definition | Data processing and inference performed on local edge servers close to the data source. | Inference executed directly on the end device without external servers. |
| Latency | Low latency due to proximity but slightly higher than on-device. | Minimal latency, immediate processing on the device. |
| Connectivity | Requires reliable network connection to edge servers. | Operates independently, no network needed during inference. |
| Resource Usage | Uses edge server resources; device minimal load. | Depends solely on device's CPU/GPU and memory. |
| Scalability | Highly scalable by adding edge nodes. | Scalability limited by device hardware capability. |
| Security | Sensitive data processed locally; some exposure risk during transmission. | Improved security; data never leaves device. |
| Use Cases | IoT networks, smart cities, autonomous vehicles with edge infrastructure. | Mobile devices, wearables, embedded systems. |
Which is better?
Edge inference processes data near the source, minimizing latency and reducing bandwidth usage by offloading computations to local servers or gateways, making it ideal for applications requiring real-time analytics across multiple devices. On-device inference executes AI models directly on hardware such as smartphones or IoT devices, enhancing privacy and enabling offline functionality while depending on limited processing power and energy constraints. Choosing between edge and on-device inference depends on factors like network availability, latency requirements, computational resources, and data privacy considerations specific to the use case.
Connection
Edge inference and on-device inference both involve processing data locally on devices rather than relying on centralized cloud servers, reducing latency and enhancing privacy. Edge inference typically occurs at network edge devices like routers or gateways, while on-device inference happens directly on end-user devices such as smartphones or IoT sensors. This close integration enables faster decision-making and efficient use of computational resources in real-time applications like autonomous vehicles and smart home systems.
Key Terms
Latency
On-device inference processes data directly within the device's local hardware, significantly reducing latency by eliminating the need for data transmission to external servers. Edge inference, while also enhancing responsiveness, often depends on nearby edge servers, which introduces minimal network delay compared to cloud processing but still surpasses on-device speeds. Explore the latest benchmarks and technologies to understand how these inference methods impact real-time applications.
Data Privacy
On-device inference processes data locally on the user's device, minimizing the risk of data exposure by eliminating the need to send sensitive information to external servers. Edge inference involves data processing on nearby edge servers, offering faster computation than cloud-based methods but potentially increasing privacy risks due to data transmission. Explore how these approaches impact data privacy and compliance with regulations to choose the best solution for your application.
Compute Resource Location
On-device inference processes data directly on the user's device, leveraging localized compute resources such as smartphones or IoT devices to reduce latency and enhance privacy. Edge inference relies on nearby edge servers or gateways, offering more powerful computational capabilities while maintaining proximity to the data source for faster processing compared to cloud solutions. Explore in-depth comparisons to understand the optimal scenarios for deploying each inference approach.
Source and External Links
On-Device Neural Net Inference with Mobile GPUs - Google Research demonstrates leveraging mobile GPUs for efficient, real-time deep neural network inference on smartphones, enabling privacy and low latency through hardware accelerators.
[2407.11061] Exploring the Boundaries of On-Device Inference - This paper evaluates on-device inference performance, introduces Hierarchical Inference (HI) for offloading complex tasks, and measures accuracy, latency, and energy consumption on diverse edge devices.
Thematic Memo: Inference on Device - Citrini Research highlights Apple's advantage in edge AI via custom silicon and neural engines, positioning them for major advancements in smartphone AI capabilities.