Vector databases excel in managing high-dimensional data for AI and machine learning applications, offering efficient similarity searches and scalable storage. In-memory databases prioritize speed by storing data directly in RAM, enabling rapid transaction processing and real-time analytics. Explore the distinct advantages and use cases of vector and in-memory databases to optimize your data infrastructure.
Why it is important
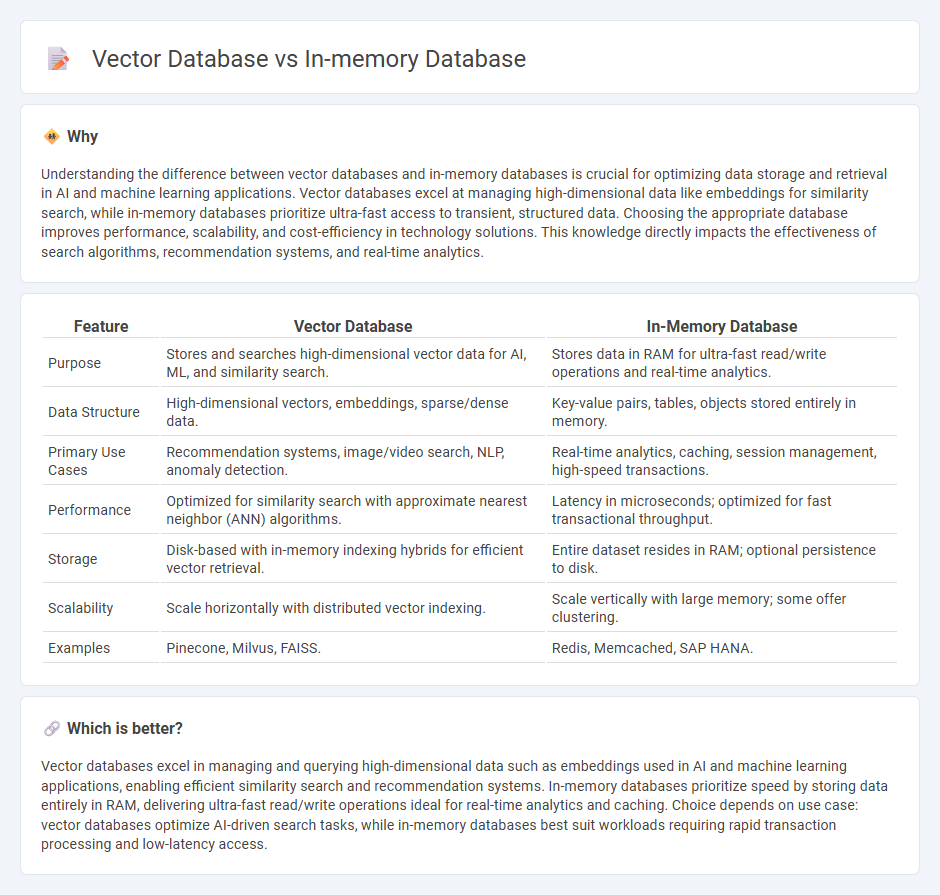
Understanding the difference between vector databases and in-memory databases is crucial for optimizing data storage and retrieval in AI and machine learning applications. Vector databases excel at managing high-dimensional data like embeddings for similarity search, while in-memory databases prioritize ultra-fast access to transient, structured data. Choosing the appropriate database improves performance, scalability, and cost-efficiency in technology solutions. This knowledge directly impacts the effectiveness of search algorithms, recommendation systems, and real-time analytics.
Comparison Table
| Feature | Vector Database | In-Memory Database |
|---|---|---|
| Purpose | Stores and searches high-dimensional vector data for AI, ML, and similarity search. | Stores data in RAM for ultra-fast read/write operations and real-time analytics. |
| Data Structure | High-dimensional vectors, embeddings, sparse/dense data. | Key-value pairs, tables, objects stored entirely in memory. |
| Primary Use Cases | Recommendation systems, image/video search, NLP, anomaly detection. | Real-time analytics, caching, session management, high-speed transactions. |
| Performance | Optimized for similarity search with approximate nearest neighbor (ANN) algorithms. | Latency in microseconds; optimized for fast transactional throughput. |
| Storage | Disk-based with in-memory indexing hybrids for efficient vector retrieval. | Entire dataset resides in RAM; optional persistence to disk. |
| Scalability | Scale horizontally with distributed vector indexing. | Scale vertically with large memory; some offer clustering. |
| Examples | Pinecone, Milvus, FAISS. | Redis, Memcached, SAP HANA. |
Which is better?
Vector databases excel in managing and querying high-dimensional data such as embeddings used in AI and machine learning applications, enabling efficient similarity search and recommendation systems. In-memory databases prioritize speed by storing data entirely in RAM, delivering ultra-fast read/write operations ideal for real-time analytics and caching. Choice depends on use case: vector databases optimize AI-driven search tasks, while in-memory databases best suit workloads requiring rapid transaction processing and low-latency access.
Connection
Vector databases and in-memory databases are connected through their ability to rapidly process and store high-dimensional data for advanced analytics and machine learning applications. Vector databases optimize similarity search by indexing complex data types like images and text embeddings, while in-memory databases provide ultra-fast data retrieval by storing information directly in RAM. Leveraging both technologies enables real-time AI-driven insights and efficient handling of large-scale vector data in sectors such as recommendation systems and natural language processing.
Key Terms
Data Storage Model
In-memory databases store data directly in the system's RAM, enabling ultra-fast access and low-latency transactions optimized for structured data and real-time analytics. Vector databases utilize specialized data structures to store high-dimensional vectors representing complex data such as images, text embeddings, or sensor signals, facilitating efficient similarity search and machine learning applications. Explore our detailed comparison to understand which data storage model best suits your AI-driven needs.
Query Processing
In-memory databases leverage RAM to enable ultra-fast query processing by minimizing disk I/O delays, making them ideal for real-time analytics and high-speed transactions. Vector databases optimize query processing through specialized indexing and similarity search algorithms designed for handling high-dimensional vector data, crucial for AI-driven applications such as recommendation systems and natural language processing. Explore the differences in query optimization techniques and use cases to understand which database is best suited for your needs.
Similarity Search
In-memory databases provide high-speed data retrieval by storing data directly in RAM, suitable for real-time analytics but limited in handling complex similarity searches involving high-dimensional vectors. Vector databases are optimized explicitly for similarity search, using advanced algorithms and indexing structures like HNSW or FAISS to efficiently process nearest neighbor searches in multi-dimensional spaces. Explore further to understand how each database type impacts similarity search performance and application use cases.
Source and External Links
In-memory database - Wikipedia - An in-memory database primarily relies on main memory (RAM) for data storage, enabling faster data access by eliminating the slower disk I/O operations found in traditional databases.
What Is a In Memory Database? - AWS - An in-memory database enables microsecond response times and high throughput, making it ideal for real-time applications like gaming leaderboards and analytics.
What Is an In-Memory Database? w/ Examples - Couchbase - In-memory databases keep all data in RAM for rapid retrieval and processing, and use techniques such as replication or disk backup to ensure data persistence despite the volatile nature of memory.