Differentiable programming enables the optimization of complex models by leveraging automatic differentiation to adjust parameters through gradient-based methods, enhancing accuracy in tasks like neural network training. Reinforcement learning focuses on agents learning optimal behaviors by receiving rewards or penalties from interactions within an environment, optimizing decision-making over time. Explore more to understand how these paradigms revolutionize artificial intelligence and machine learning.
Why it is important
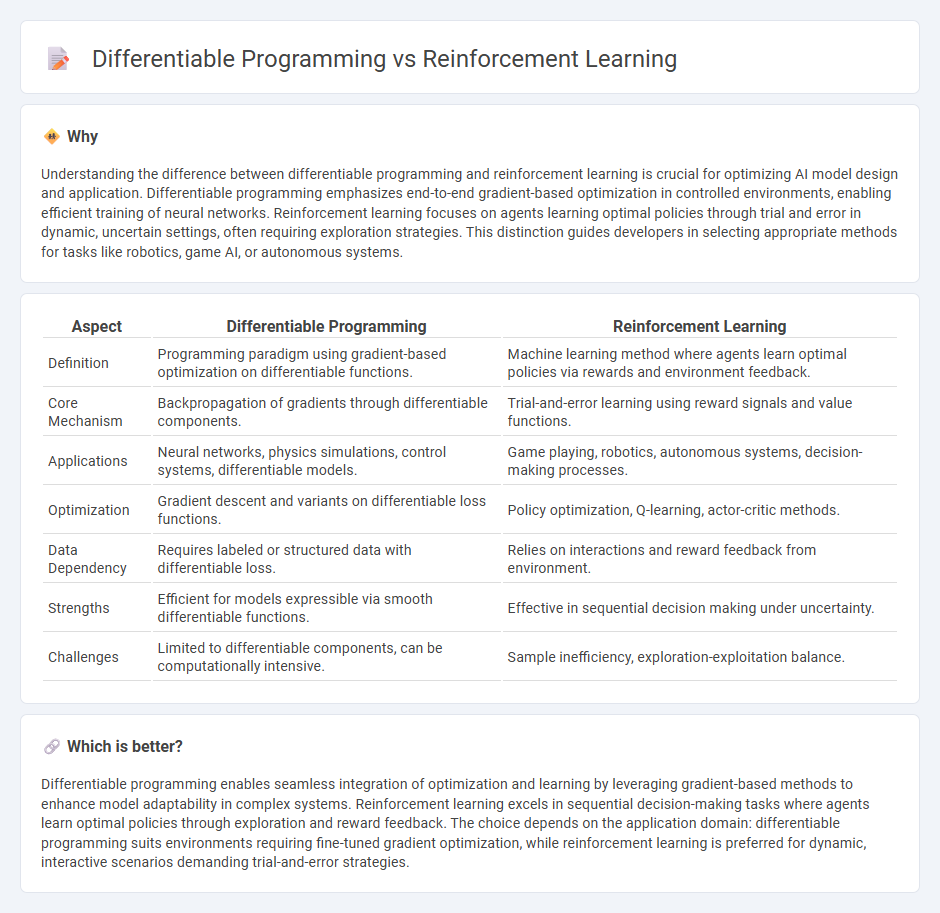
Understanding the difference between differentiable programming and reinforcement learning is crucial for optimizing AI model design and application. Differentiable programming emphasizes end-to-end gradient-based optimization in controlled environments, enabling efficient training of neural networks. Reinforcement learning focuses on agents learning optimal policies through trial and error in dynamic, uncertain settings, often requiring exploration strategies. This distinction guides developers in selecting appropriate methods for tasks like robotics, game AI, or autonomous systems.
Comparison Table
| Aspect | Differentiable Programming | Reinforcement Learning |
|---|---|---|
| Definition | Programming paradigm using gradient-based optimization on differentiable functions. | Machine learning method where agents learn optimal policies via rewards and environment feedback. |
| Core Mechanism | Backpropagation of gradients through differentiable components. | Trial-and-error learning using reward signals and value functions. |
| Applications | Neural networks, physics simulations, control systems, differentiable models. | Game playing, robotics, autonomous systems, decision-making processes. |
| Optimization | Gradient descent and variants on differentiable loss functions. | Policy optimization, Q-learning, actor-critic methods. |
| Data Dependency | Requires labeled or structured data with differentiable loss. | Relies on interactions and reward feedback from environment. |
| Strengths | Efficient for models expressible via smooth differentiable functions. | Effective in sequential decision making under uncertainty. |
| Challenges | Limited to differentiable components, can be computationally intensive. | Sample inefficiency, exploration-exploitation balance. |
Which is better?
Differentiable programming enables seamless integration of optimization and learning by leveraging gradient-based methods to enhance model adaptability in complex systems. Reinforcement learning excels in sequential decision-making tasks where agents learn optimal policies through exploration and reward feedback. The choice depends on the application domain: differentiable programming suits environments requiring fine-tuned gradient optimization, while reinforcement learning is preferred for dynamic, interactive scenarios demanding trial-and-error strategies.
Connection
Differentiable programming enhances reinforcement learning by enabling gradient-based optimization of policies through neural networks, improving learning efficiency and adaptability. Reinforcement learning leverages differentiable models to calculate gradients of reward functions, facilitating policy updates in complex environments. This connection accelerates the development of sophisticated AI agents capable of continuous learning and decision-making.
Key Terms
Policy Optimization
Reinforcement learning uses policy optimization methods like Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO) to improve decision-making in dynamic environments through trial-and-error feedback. Differentiable programming integrates gradient-based optimization directly into policy learning, enabling more efficient and flexible updates in complex neural architectures. Explore how these approaches differ in scalability and applicability to advanced AI tasks for a deeper understanding.
Automatic Differentiation
Reinforcement learning relies on trial-and-error interactions to optimize policies, whereas differentiable programming leverages automatic differentiation (AD) to compute gradients of complex models efficiently. Automatic differentiation in differentiable programming enables precise gradient calculations for nested functions, facilitating seamless end-to-end optimization in machine learning models. Explore how integrating AD transforms learning frameworks for advanced AI applications.
Reward Function
Reinforcement learning relies heavily on a well-defined reward function to guide the agent's behavior towards optimal decisions by maximizing cumulative rewards over time. Differentiable programming integrates reward signals directly into gradient-based optimization processes, enabling end-to-end learning with continuous feedback. Explore the nuances and implementations of reward functions in both paradigms to enhance your understanding of advanced machine learning techniques.
Source and External Links
Reinforcement learning - Wikipedia - Reinforcement learning (RL) is a machine learning approach where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards through trial and error, using feedback in the form of rewards or punishments.
What is Reinforcement Learning? - AWS - In reinforcement learning, an agent (software) learns optimal actions by exploring an environment, receiving rewards or penalties, and developing policies to maximize long-term cumulative reward, balancing exploration of new actions with exploitation of known high-reward actions.
What is reinforcement learning? - Blog - York Online Masters degrees - Unlike supervised and unsupervised learning, reinforcement learning involves an agent learning through direct interaction with an environment, receiving only feedback in the form of rewards or punishments, and aims to discover the best action sequence to maximize total reward without predefined training data.