Edge inference processes data locally on devices like smartphones and IoT sensors, reducing latency and enhancing privacy by minimizing data transmission to the cloud. Real-time inference focuses on delivering immediate analytical results, often leveraging cloud computing to handle complex models and large datasets quickly. Explore the specifics and advantages of each approach to optimize your AI deployment strategy.
Why it is important
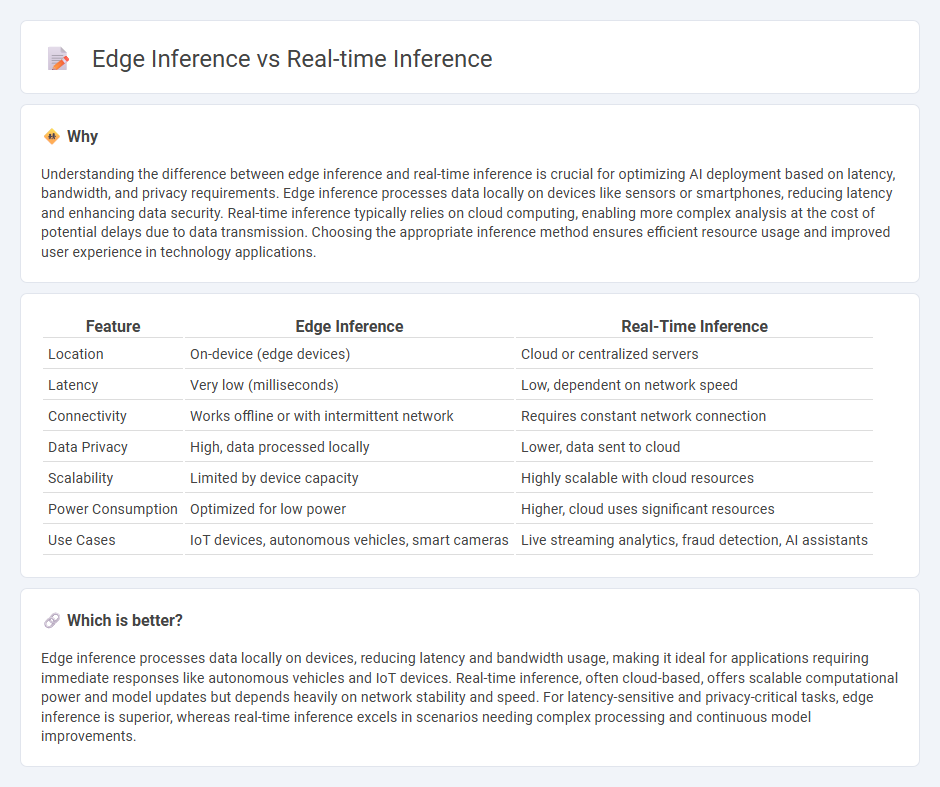
Understanding the difference between edge inference and real-time inference is crucial for optimizing AI deployment based on latency, bandwidth, and privacy requirements. Edge inference processes data locally on devices like sensors or smartphones, reducing latency and enhancing data security. Real-time inference typically relies on cloud computing, enabling more complex analysis at the cost of potential delays due to data transmission. Choosing the appropriate inference method ensures efficient resource usage and improved user experience in technology applications.
Comparison Table
| Feature | Edge Inference | Real-Time Inference |
|---|---|---|
| Location | On-device (edge devices) | Cloud or centralized servers |
| Latency | Very low (milliseconds) | Low, dependent on network speed |
| Connectivity | Works offline or with intermittent network | Requires constant network connection |
| Data Privacy | High, data processed locally | Lower, data sent to cloud |
| Scalability | Limited by device capacity | Highly scalable with cloud resources |
| Power Consumption | Optimized for low power | Higher, cloud uses significant resources |
| Use Cases | IoT devices, autonomous vehicles, smart cameras | Live streaming analytics, fraud detection, AI assistants |
Which is better?
Edge inference processes data locally on devices, reducing latency and bandwidth usage, making it ideal for applications requiring immediate responses like autonomous vehicles and IoT devices. Real-time inference, often cloud-based, offers scalable computational power and model updates but depends heavily on network stability and speed. For latency-sensitive and privacy-critical tasks, edge inference is superior, whereas real-time inference excels in scenarios needing complex processing and continuous model improvements.
Connection
Edge inference enables real-time inference by processing data locally on devices such as IoT sensors and mobile phones, minimizing latency and bandwidth usage. Real-time inference requires immediate data analysis and decision-making, which is made efficient through edge computing architectures that avoid reliance on centralized cloud servers. This synergy enhances applications in autonomous vehicles, smart manufacturing, and augmented reality by ensuring timely and efficient AI-driven insights.
Key Terms
Latency
Real-time inference prioritizes minimal latency by processing data instantaneously, often relying on powerful centralized servers to deliver rapid predictions. Edge inference reduces latency by performing computations directly on local devices near the data source, eliminating delays caused by data transmission to remote servers. Explore the latest innovations in latency optimization for real-time and edge inference to enhance your AI deployment strategies.
Bandwidth
Real-time inference relies on constant data transmission between devices and centralized servers, often consuming high bandwidth to process and analyze information promptly. Edge inference minimizes bandwidth usage by performing data processing directly on local devices, reducing latency and dependence on continuous network availability. Explore the advantages and challenges of each approach to optimize bandwidth efficiency in AI deployments.
Compute Location
Real-time inference processes data immediately as it is received, typically relying on centralized cloud servers to perform complex computations with high processing power. Edge inference shifts computational workloads to local devices or edge servers near the data source, reducing latency and bandwidth usage while enhancing privacy and responsiveness. Explore the advantages and use cases of each computing model to determine the optimal strategy for your AI applications.
Source and External Links
Real-time Inference: Definition, Use Cases - Ultralytics - Real-time inference refers to using a trained machine learning model to make predictions on live data with minimal delay, enabling instant, actionable results for time-sensitive applications like autonomous driving and video security.
Real-time inference - Amazon SageMaker AI - AWS Documentation - Real-time inference in AWS SageMaker is designed for workloads requiring interactive, low-latency predictions, allowing models to be deployed as fully managed endpoints that automatically scale based on demand.
Choosing between SageMaker AI Inference and Endpoint Type - Configuring real-time inference involves setting autoscaling policies, selecting compute resources, and choosing deployment modes (single model, multi-model, or inference pipeline) to meet high-throughput, low-latency requirements for applications like personalized recommendations.