Liquid neural networks dynamically adapt their structure over time, allowing for enhanced flexibility in processing complex temporal data compared to gated recurrent units (GRUs), which rely on fixed gating mechanisms to manage information flow. Liquid neural networks excel in tasks requiring continuous adaptation and robustness to changing environments, outperforming traditional GRUs in scenarios like real-time sensor data analysis and autonomous systems. Explore the evolving landscape of neural architectures to understand how these innovations are shaping the future of artificial intelligence.
Why it is important
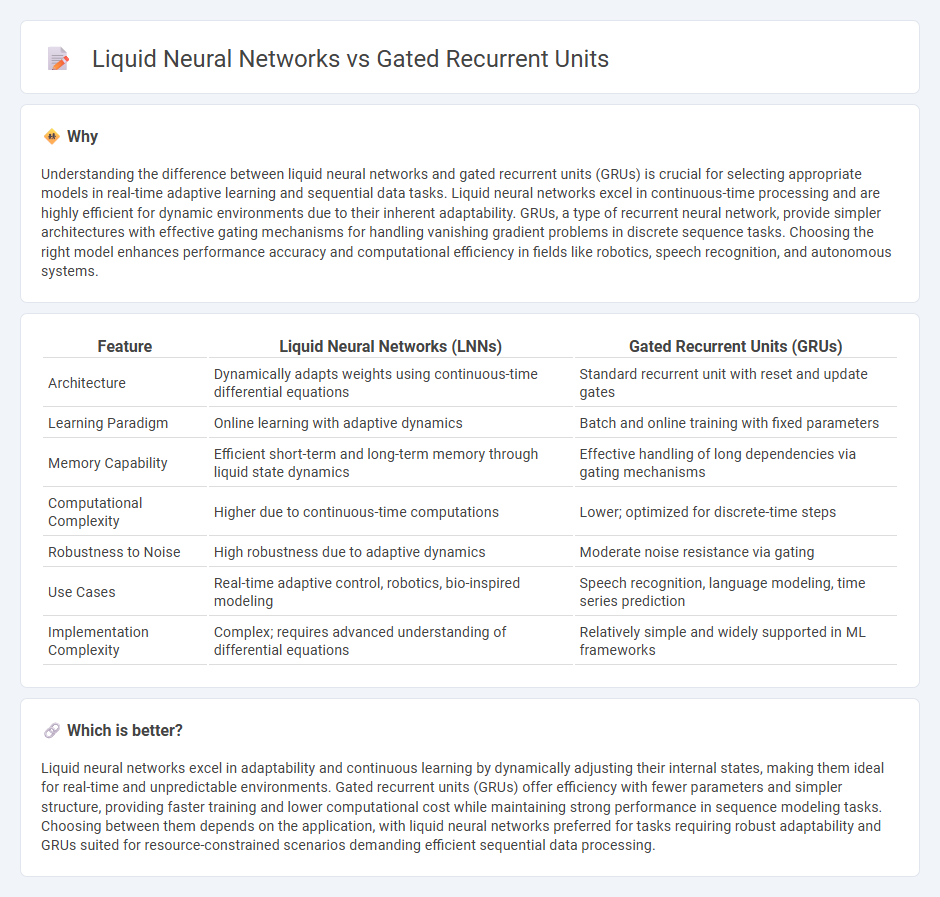
Understanding the difference between liquid neural networks and gated recurrent units (GRUs) is crucial for selecting appropriate models in real-time adaptive learning and sequential data tasks. Liquid neural networks excel in continuous-time processing and are highly efficient for dynamic environments due to their inherent adaptability. GRUs, a type of recurrent neural network, provide simpler architectures with effective gating mechanisms for handling vanishing gradient problems in discrete sequence tasks. Choosing the right model enhances performance accuracy and computational efficiency in fields like robotics, speech recognition, and autonomous systems.
Comparison Table
| Feature | Liquid Neural Networks (LNNs) | Gated Recurrent Units (GRUs) |
|---|---|---|
| Architecture | Dynamically adapts weights using continuous-time differential equations | Standard recurrent unit with reset and update gates |
| Learning Paradigm | Online learning with adaptive dynamics | Batch and online training with fixed parameters |
| Memory Capability | Efficient short-term and long-term memory through liquid state dynamics | Effective handling of long dependencies via gating mechanisms |
| Computational Complexity | Higher due to continuous-time computations | Lower; optimized for discrete-time steps |
| Robustness to Noise | High robustness due to adaptive dynamics | Moderate noise resistance via gating |
| Use Cases | Real-time adaptive control, robotics, bio-inspired modeling | Speech recognition, language modeling, time series prediction |
| Implementation Complexity | Complex; requires advanced understanding of differential equations | Relatively simple and widely supported in ML frameworks |
Which is better?
Liquid neural networks excel in adaptability and continuous learning by dynamically adjusting their internal states, making them ideal for real-time and unpredictable environments. Gated recurrent units (GRUs) offer efficiency with fewer parameters and simpler structure, providing faster training and lower computational cost while maintaining strong performance in sequence modeling tasks. Choosing between them depends on the application, with liquid neural networks preferred for tasks requiring robust adaptability and GRUs suited for resource-constrained scenarios demanding efficient sequential data processing.
Connection
Liquid neural networks and gated recurrent units (GRUs) both enhance sequential data processing by adapting their internal states dynamically over time. Liquid neural networks leverage continuous-time dynamics inspired by biological neurons, enabling flexible and efficient temporal representations. GRUs utilize gating mechanisms to control information flow within recurrent units, optimizing learning in time-dependent tasks such as speech recognition and natural language processing.
Key Terms
Memory Cells
Gated Recurrent Units (GRUs) utilize memory cells with reset and update gates to efficiently capture long-term dependencies in sequential data, optimizing state retention and computational efficiency. Liquid Neural Networks employ dynamic memory cells that continuously adapt and evolve based on incoming data streams, providing enhanced temporal flexibility and resilience to changing inputs. Explore further to understand which memory cell architecture best suits your temporal modeling needs.
Temporal Dynamics
Gated Recurrent Units (GRUs) excel at capturing temporal dependencies in sequential data through their gating mechanisms that regulate information flow and maintain long-term memory. Liquid Neural Networks adapt dynamically to time-varying inputs by employing continuous-time differential equations that model temporal dynamics with high sensitivity and stability. Explore the unique advantages of GRUs and Liquid Neural Networks in temporal processing to understand their applications in real-world time series analysis.
Network Architecture
Gated Recurrent Units (GRUs) utilize a fixed, gated architecture designed to control information flow through reset and update gates, enabling efficient handling of sequence data and mitigating vanishing gradient issues. In contrast, Liquid Neural Networks feature a dynamic, adaptable architecture that continuously evolves neuron states through liquid time-constant neurons, offering enhanced flexibility and temporal processing capabilities. Explore further to understand the distinct advantages of these architectures in various applications.
Source and External Links
Gated Recurrent Unit Networks - Machine Learning - GeeksforGeeks - GRUs are a simplified type of recurrent neural network introduced in 2014 that use two gating mechanisms, the update gate and reset gate, to selectively retain and forget information, providing efficient handling of sequential data without the complexity and computational cost of LSTMs.
GRU Explained - Gated Recurrent Unit - Papers With Code - GRUs are recurrent neural networks similar to LSTMs but with only two gates, the reset and update gates, which generally makes them faster and easier to train due to fewer parameters.
Gated recurrent unit - Wikipedia - GRUs are gating mechanisms within recurrent neural networks that lack an output gate, leading to fewer parameters than LSTMs yet achieving comparable performance on tasks like speech and language modeling, introduced by Kyunghyun Cho et al. in 2014.