Synthetic data is artificially generated information created using algorithms and simulations, enabling scalable and privacy-preserving data sets for machine learning models. Crowdsourced data involves collecting real-world inputs from a large group of people to provide diverse and authentic datasets, often subject to variability and privacy concerns. Explore the benefits and challenges of synthetic versus crowdsourced data to enhance your data-driven projects.
Why it is important
Understanding the difference between synthetic data and crowdsourced data is crucial for optimizing data quality and privacy compliance in AI training. Synthetic data is artificially generated using algorithms, ensuring controlled environments and reduction of personally identifiable information risks. Crowdsourced data originates from diverse human contributors, providing real-world variability but posing challenges in consistency and data bias. Knowing these distinctions enables better decisions in data acquisition strategies and model performance enhancement.
Comparison Table
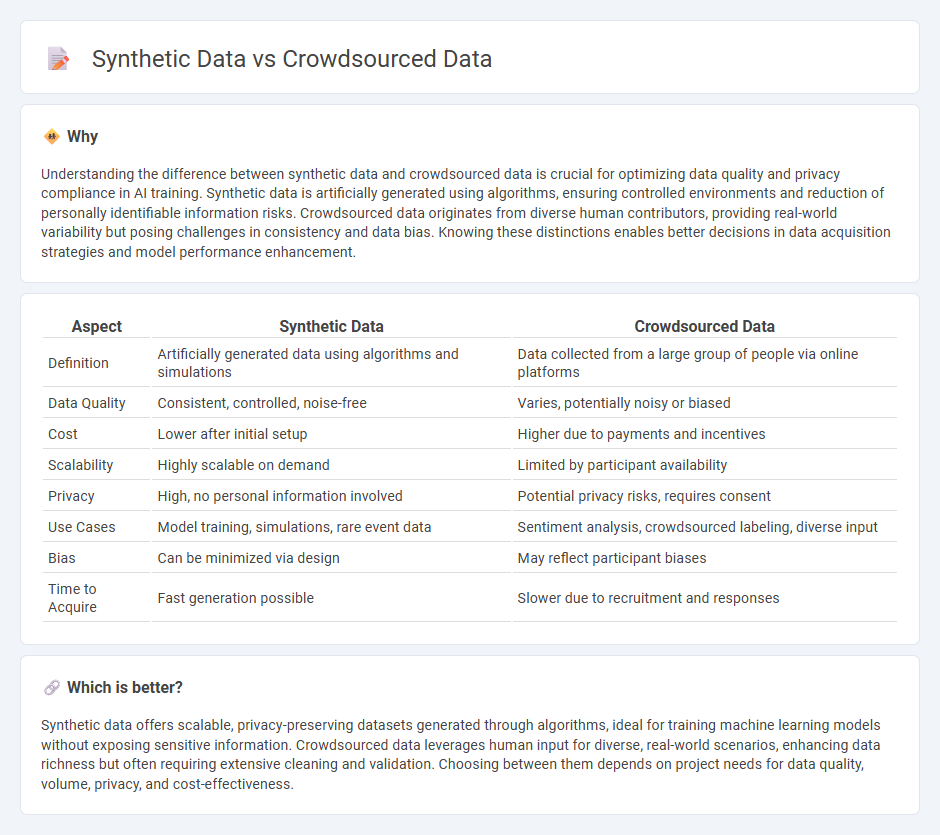
| Aspect | Synthetic Data | Crowdsourced Data |
|---|---|---|
| Definition | Artificially generated data using algorithms and simulations | Data collected from a large group of people via online platforms |
| Data Quality | Consistent, controlled, noise-free | Varies, potentially noisy or biased |
| Cost | Lower after initial setup | Higher due to payments and incentives |
| Scalability | Highly scalable on demand | Limited by participant availability |
| Privacy | High, no personal information involved | Potential privacy risks, requires consent |
| Use Cases | Model training, simulations, rare event data | Sentiment analysis, crowdsourced labeling, diverse input |
| Bias | Can be minimized via design | May reflect participant biases |
| Time to Acquire | Fast generation possible | Slower due to recruitment and responses |
Which is better?
Synthetic data offers scalable, privacy-preserving datasets generated through algorithms, ideal for training machine learning models without exposing sensitive information. Crowdsourced data leverages human input for diverse, real-world scenarios, enhancing data richness but often requiring extensive cleaning and validation. Choosing between them depends on project needs for data quality, volume, privacy, and cost-effectiveness.
Connection
Synthetic data and crowdsourced data are connected through their use in enhancing machine learning model training by providing diverse and scalable datasets. Crowdsourced data offers real-world variability and human-generated labels, while synthetic data supplements gaps by generating artificial yet realistic data points to improve model robustness. Integrating both approaches optimizes data quality and volume, crucial for advancing AI-driven technology applications.
Key Terms
Data Generation
Crowdsourced data leverages real user inputs from diverse sources, ensuring high variability and authenticity in data generation, essential for training robust machine learning models. Synthetic data is artificially created using algorithms and simulations, enabling the generation of vast datasets while preserving privacy and reducing collection costs. Explore further to understand how each method impacts data quality, scalability, and use case applicability in AI development.
Data Quality
Crowdsourced data often exhibits variability in quality due to diverse contributor expertise and inconsistent data collection methods, impacting its reliability for machine learning models. Synthetic data, generated through algorithms and simulations, ensures consistent quality control and privacy compliance but may lack the nuanced complexity of real-world scenarios. Explore more about optimizing data quality through hybrid approaches leveraging both crowdsourced and synthetic data.
Scalability
Crowdsourced data enables large-scale data collection by leveraging diverse contributors worldwide, but it often faces challenges in consistency and quality control. Synthetic data offers high scalability by generating vast amounts of uniform, customizable datasets without the constraints of real-world data collection. Explore the advantages and limitations of both approaches to optimize your data strategy.
Source and External Links
Crowd-sourced Data - Dime Wiki - World Bank - Crowdsourced data collection is a participatory method of building datasets with the help of a large group of people, allowing researchers to cheaply gather plentiful, dispersed, and real-time data through platforms like mobile apps or online marketplaces.
EDC-6: Crowdsourcing for Advancing Operations - Crowdsourced data often comes from social media, third-party providers, or mobile apps and provides valuable, low-cost real-time information such as travel times, incidents, and public sentiments that can complement traditional monitoring equipment.
How to Crowdsource Data Successfully - Data crowdsourcing involves collecting data from many sources to generate insights, typically using platforms where contributors complete tasks for compensation, which can improve services and decision-making across various sectors, including transportation and customer feedback.