Federated learning enables decentralized model training by aggregating locally computed updates without transferring raw data, enhancing privacy and reducing communication overhead. Distributed learning, in contrast, splits data or models across multiple machines to accelerate computation but often requires centralized data access or extensive synchronization. Explore the nuances and advantages of each approach to understand their applications in modern AI systems.
Why it is important
Understanding the difference between federated learning and distributed learning is crucial for optimizing data privacy and computational efficiency in AI models. Federated learning enables decentralized data training on local devices without sharing raw data, enhancing user privacy and compliance with data protection regulations. Distributed learning, on the other hand, involves splitting data across multiple nodes to speed up training but may require centralized data aggregation. Choosing the right approach impacts security, scalability, and performance in developing advanced machine learning systems.
Comparison Table
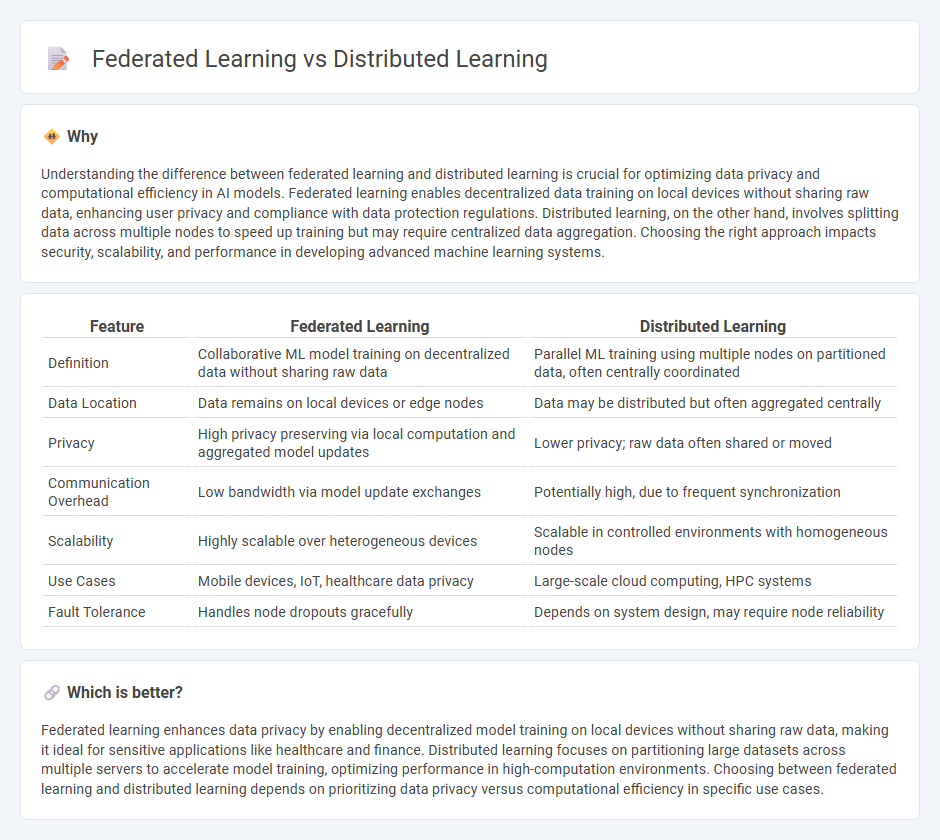
| Feature | Federated Learning | Distributed Learning |
|---|---|---|
| Definition | Collaborative ML model training on decentralized data without sharing raw data | Parallel ML training using multiple nodes on partitioned data, often centrally coordinated |
| Data Location | Data remains on local devices or edge nodes | Data may be distributed but often aggregated centrally |
| Privacy | High privacy preserving via local computation and aggregated model updates | Lower privacy; raw data often shared or moved |
| Communication Overhead | Low bandwidth via model update exchanges | Potentially high, due to frequent synchronization |
| Scalability | Highly scalable over heterogeneous devices | Scalable in controlled environments with homogeneous nodes |
| Use Cases | Mobile devices, IoT, healthcare data privacy | Large-scale cloud computing, HPC systems |
| Fault Tolerance | Handles node dropouts gracefully | Depends on system design, may require node reliability |
Which is better?
Federated learning enhances data privacy by enabling decentralized model training on local devices without sharing raw data, making it ideal for sensitive applications like healthcare and finance. Distributed learning focuses on partitioning large datasets across multiple servers to accelerate model training, optimizing performance in high-computation environments. Choosing between federated learning and distributed learning depends on prioritizing data privacy versus computational efficiency in specific use cases.
Connection
Federated learning and distributed learning both rely on multiple devices or nodes collaborating to train machine learning models without centralizing data, enhancing privacy and reducing latency. Federated learning is a specialized form of distributed learning focused on preserving user data confidentiality by keeping data localized on edge devices. This synergy enables scalable AI development across decentralized networks while maintaining robust data security standards.
Key Terms
Data Decentralization
Distributed learning enables multiple nodes to collaboratively train machine learning models by sharing data or model parameters, often relying on centralized coordination, whereas federated learning emphasizes data decentralization by keeping raw data on local devices and only exchanging model updates to preserve privacy and comply with data regulations. Federated learning is particularly advantageous in scenarios involving sensitive information like healthcare or financial data, where data privacy and security are paramount. Discover more about how data decentralization transforms machine learning frameworks in these paradigms.
Model Aggregation
Distributed learning involves splitting large datasets across multiple nodes to train model segments concurrently, with a centralized server aggregating updates by averaging gradients or parameters to form a global model. Federated learning enhances data privacy by allowing local model training on decentralized client devices, where only model updates--not raw data--are shared and securely aggregated using techniques like secure multiparty computation or homomorphic encryption. Explore further how these model aggregation strategies impact scalability, privacy, and performance in real-world applications.
Privacy Preservation
Distributed learning partitions data across multiple nodes for parallel processing but may expose sensitive information during data exchange. Federated learning enhances privacy preservation by keeping data localized on devices and sharing only model updates, reducing the risk of data breaches. Explore more to understand how these approaches balance performance and data protection.
Source and External Links
The Distributed Learning Model: Aspects, Upsides, And Applications - Distributed learning is an instructional model enabling students and instructors to connect remotely, allowing learning to happen anywhere and anytime through technology, overcoming spatial and timing barriers with synchronous or asynchronous methods.
Distributed learning - Wikipedia - Distributed learning allows instructors, students, and content to be in different locations, supporting instruction and learning independent of time and place, often overlapping with terms like distance education and blended learning.
Definition: distributed learning from 6 USC SS 464(g)(4) - Distributed learning is defined legally as education where students take academic courses by accessing information and communicating with instructors from various locations via computer networks or other technologies.